To restrict the number of rows a query should return, you create search conditions or filter criteria. In SQL, search conditions appear in the WHERE clause of the statement, or if you are creating an aggregate query, in the HAVING clause.
Note You can also use search conditions to indicate which rows are affected by an Update, Update Values, Delete, or Make-Table query.
When the query runs, the database engine examines and applies the search condition to each row in the tables you are searching. If the row meets the condition, it is included in the query. For example, a search condition that would find all the employees in a particular region might be:
region = 'UK'
To establish the criteria for including a row in a result, you can use multiple search conditions. For example, the following search criterion consists of two search conditions. The query includes a row in the result set only if that row satisfies both of the conditions.
region = 'UK' AND product_line = 'Housewares'
You can combine these conditions with AND or OR. The previous example uses AND. In contrast, the following criterion uses OR. The attendant query result will include any row that satisfies either or both of the search conditions:
region = 'UK' OR product_line = 'Housewares'
You can even combine search conditions on a single column. For example, the following criterion combines two conditions on the region column:
region = 'UK' OR region = 'US'
 Predicates in search conditions
Predicates in search conditions
A search condition consists of one or more predicates, each specifying a single condition. If the search condition includes more than one predicate, the predicates are linked with a logical AND (to narrow the search) or OR (to broaden it). The following example shows how you can use multiple conditions when searching an employee table to find the employee (or employees) with the specified first and last names:
WHERE lname = 'Smith' AND fname = 'Jean'
A single predicate follows this format:
search_expression operator search_value
In most instances, search_expression is the name of a column to search. Similarly, the most common form of search_value is a literal value to search for, which can be either a string of characters or a number.
The following two examples show literal values. The first searches for all the employees who are in the United Kingdom, and the second searches for all employees with a specific job level:
WHERE region = 'UK'
WHERE job_lvl = 100
Both search_expression and search_value can consist of any (or any combination) of the following:
- Literal A single text, numeric, date, or logical value. The following example uses a literal to find all rows for employees in the United Kingdom:
WHERE region = 'UK' - Column reference The name of a column in one of the tables being searched. The following example searches a
productstable for all rows in which the value of the production cost is lower than the shipping cost:WHERE prod_cost < ship_cost - Function A reference to a function that the database back end can resolve to calculate a value for the search. The function can be a function defined by the database server or a user-defined function that returns a scalar value. The following example searches for orders placed today (the GETDATE( ) function returns the current date):
WHERE order_date = GETDATE() - NULL The following example searches an
authorstable for all authors who have a first name on file:WHERE au_fname IS NOT NULL - Calculation The result of a calculation that can involve literals, column references, or other expressions. The following example searches a
productstable to find all rows in which the retail sales price is more than twice the production cost:WHERE sales_price > (prod_cost * 2) - Subquery A result set generated by another query. The following example searches a
productstable to find all the products from Swedish suppliers. The subquery first searches thesupplierstable to build a list of the suppliers located in that country/region. The second search then searches theproductstable, matching the product’s supplier ID against the list created by the subquery:WHERE supplier_id IN (SELECT supplier.supplier_id FROM supplier WHERE (supplier.country = 'Sweden'))
Including or excluding columns
You can choose which columns appear in a query result. When choosing which columns to include, there are several things to keep in mind:
- You can include all of a table’s columns For example, you can include everything about each employee. The resulting SQL looks like this:
SELECT * FROM employee - You can include exactly the columns you want For example, you can list the name of all the employees. The resulting SQL looks like this:
SELECT fname, minit, lname FROM employeeThe list of columns you include might not even include a column from every table in the query. This does not mean that the table does not contribute to the query.
- You can include all columns from all tables For example, when you combine data from the sales and stores tables, you can include every column from either table in the result. The resulting SQL might look like this:
SELECT * FROM sales INNER JOIN stores ON sales.stor_id = stores.stor_id - You can include derived columns That is, you can include columns that are not part of any database table of the query. For example, you can create a result set containing the job description and the average job level for each job. The resulting SQL might look like this:
SELECT job_desc, (max_lvl + min_lvl) / 2 FROM jobsYou can use SQL syntax to define the derived column (as in the preceding sample query) or you can employ a user-defined function that returns a scalar value.
A query result can include data from multiple tables. To combine data from tables, you use the Join operation from SQL.
The Join operation matches rows of one table with rows of another table, based on values in those rows. For example, you can join the table titles with the table publishers. Each row in the result set will describe a title, including information about that title’s publisher, as shown in the following illustration:
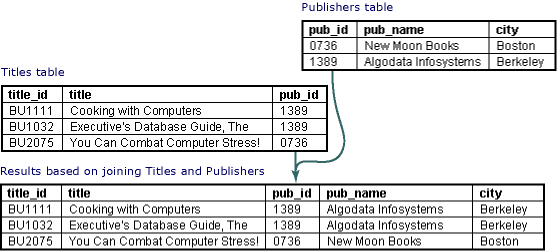
When you join tables, the type of join that you create affects the rows that appear in the result set. You can create the following types of joins:
- Inner join A join that displays only the rows that have a match in both joined tables. (This is the default type of join in the Query Designer.) For example, you can join the
titlesandpublisherstables to create a result set that shows the publisher name for each title. In an inner join, titles for which you do not have publisher information are not included in the result set, nor are publishers with no titles. The resulting SQL for such a join might look like this:SELECT title, pub_name FROM titles INNER JOIN publishers ON titles.pub_id = publishers.pub_idNote Columns containing NULL do not match any values when you are creating an inner join and are therefore excluded from the result set. Null values do not match other null values.
- Outer join A join that includes rows even if they do not have related rows in the joined table. You can create three variations of an outer join to specify the unmatched rows to be included:
- Left outer join All rows from the first-named table (the "left" table, which appears leftmost in the JOIN clause) are included. Unmatched rows in the right table do not appear. For example, the following SQL statement illustrates a left outer join between the
titlesandpublisherstables to include all titles, even those you do not have publisher information for:SELECT titles.title_id, titles.title, publishers.pub_name FROM titles LEFT OUTER JOIN publishers ON titles.pub_id = publishers.pub_id - Right outer join All rows in the second-named table (the "right" table, which appears rightmost in the JOIN clause) are included. Unmatched rows in the left table are not included. For example, a right outer join between the
titlesandpublisherstables will include all publishers, even those who have no titles in thetitlestable. The resulting SQL might look like this:SELECT titles.title_id, titles.title, publishers.pub_name FROM titles RIGHT OUTER JOIN publishers ON titles.pub_id = publishers.pub_id - Full outer join All rows in all joined tables are included, whether they are matched or not. For example, a full outer join between
titlesandpublishersshows all titles and all publishers, even those that have no match in the other table.SELECT titles.title_id, titles.title, publishers.pub_name FROM titles FULL OUTER JOIN publishers ON titles.pub_id = publishers.pub_id
- Left outer join All rows from the first-named table (the "left" table, which appears leftmost in the JOIN clause) are included. Unmatched rows in the right table do not appear. For example, the following SQL statement illustrates a left outer join between the
- Cross join A join whose result set includes one row for each possible pairing of rows from the two tables. For example, authors CROSS JOIN publishers yields a result set with one row for each possible author/publisher combination. The resulting SQL might look like this:
SELECT * FROM authors CROSS JOIN publishers
The JOIN operator matches rows by comparing values in one table with values in another. You decide which columns from each table should be matched. You have several choices:
- Related Columns Typically, you join tables by matching values in columns for which a foreign-key relationship exists. For example, you can join discounts to stores by matching the values of stor_id in the respective tables. The resulting SQL might look like this:
SELECT * FROM discounts INNER JOIN stores ON stores.stor_id = discounts.stor_id - Unrelated Columns You can also join tables by matching values in columns for which no foreign-key relationship exists. For example, you can join publishers to authors by matching the values of state in the respective tables. Such a join yields a result set in which each row describes an author-publisher pair located in the same state.
SELECT au_lname, au_fname, pub_name, authors.state FROM authors INNER JOIN publishers ON authors.state = publishers.state
Note also that you use multiple columns to match rows from the joined tables. For example, to find the author-publisher pairs in which the author and publisher are located in the same city, you use a join operation matching the respective state columns and the respective city columns of the two tables. You need to match both city and state because it is possible that different states could have like-named cities (e.g., Springfield, Illinois and Springfield, Massachusetts).
The JOIN operator matches rows by comparing values in one table with values in another. You can decide exactly what constitutes a match. Your choices fall into two broad categories:
- Match on Equality Typically, you match rows when the respective column values are equal. For example, to create a result set in which each row contains a full description of each publisher (that is, with columns from the publishers table and the pub_info table), you use a join matching rows where the values of pub_id in the respective tables are equal. The resulting SQL might look like this:
SELECT * FROM publishers INNER JOIN pub_info ON publishers.pub_id = pub_info.pub_id - Other You can match rows using some test other than equality. For example, to find the employees and the jobs for which they are underqualified, you can join employee with jobs, matching rows in which the job’s minimum required level exceeds the employee’s job level. The resulting SQL might look like this:
SELECT fname, minit, lname, job_desc, job_lvl, min_lvl FROM employee INNER JOIN jobs ON employee.job_lvl < jobs.min_lvl
When combining data from multiple tables, you must decide what tables to use. There are several noteworthy considerations:
- Combining Three or More Tables Each JOIN operation combines two tables. However, you can use multiple JOIN operations within one query to assemble data from any number of tables. Because the result of each JOIN operation is effectively a table, you can use that result as an operand in a subsequent join operation. For example, to create a result set in which each row contains a book title, an author, and the percentage of that book’s royalties the author receives, you must combine data from three tables: authors, titles, and titleauthor. The resulting SQL might look like this:
SELECT title, au_fname, au_lname, royaltyper FROM authors INNER JOIN titleauthor ON authors.au_id = titleauthor.au_id INNER JOIN titles ON titleauthor.title_id = titles.title_id - Using a Table merely to join others You can include a table in a join even if you do not want to include any of that table’s columns in a result set. For example, to establish a result set in which each row describes a title-store pair in which that store sells that title, you include columns from two tables: titles, and stores. But you must use a third table, sales, to determine which stores have sold which titles. The resulting SQL might look like this:
SELECT title, stor_name FROM titles INNER JOIN sales ON titles.title_id = sales.title_id INNER JOIN stores ON sales.stor_id = stores.stor_idNotice that the sales table contributes no columns to the result set.
- Using a table twice in one query You can use the same table two (or more) times within a single query.
- Using something else in place of a table In place of a table, you can use a query, a view, or a user-defined function that returns a table.
You can create a query result in which each result row corresponds to an entire group of rows from the original data. When collapsing rows, there are several things to keep in mind:
- You can eliminate duplicate rows Some queries can create result sets in which multiple identical rows appear. For example, you can create a result set in which each row contains the city and state name of a city containing an author – but if a city contains several authors, there will be several identical rows. The resulting SQL might look like this:
SELECT city, state FROM authorsThe result set generated by the preceding query is not very useful. If a city contains four authors, the result set will include four identical rows. Since the result set does not include any columns other than city and state, there is no way to distinguish the identical rows from each other. One way to avoid such duplicate rows is to include additional columns that can make the rows different. For example, if you include author name, each row will be different (provided no two like-named authors live within any one city). The resulting SQL might look like this:
SELECT city, state, fname, minit, lname FROM authorsOf course, the preceding query eliminates the symptom, but does not really solve the problem. That is, the result set has no duplicates, but it is no longer a result set about cities. To eliminate duplicates in the original result set, and still have each row describe a city, you can create a query returning only distinct rows. The resulting SQL might look like this:
SELECT DISTINCT city, state FROM authors - You can calculate on groups of rows That is, you can summarize information in groups of rows. For example, you can create a result set in which each row contains the city and state name of a city containing an author, plus a count of the number of authors contained in that city. The resulting SQL might look like this:
SELECT city, state, COUNT(*) FROM authors GROUP BY city, state - You can use selection criteria to include groups of rows For example, you can create a result set in which each row contains the city and state name of a city containing several authors, plus a count of the number of authors contained in that city. The resulting SQL might look like this:
SELECT city, state, COUNT(*) FROM authors GROUP BY city, state HAVING COUNT(*) > 1
Using a table twice in one query
You can use the same table two (or more) times within a single query. There are several situations in which you do this.
- Creating a self-join with a reflexive relationship You can join a table to itself using a reflexive relationship
— a relationship in which the referring foreign-key columns and the referred-to primary-key columns are in the same table. For example, suppose the employee table contains an additional column, employee.manager_emp_id, and that a foreign key exists from manager_emp_id to employee.emp_id. Within each row of the employee table, the manager_emp_id column indicates the employee’s boss. More precisely, it indicates the employee’s boss’s emp_id. By joining the table to itself using this reflexive relationship, you can establish a result set in which each row contains a boss’s name and the name of one of that boss’s employees. The resulting SQL might look like this:
SELECT boss.lname, boss.fname, employee.lname, employee.fname FROM employee INNER JOIN employee boss ON employee.manager_emp_id = boss.emp_id - Creating a self-join without a reflexive relationship You can join a table to itself without using a reflexive relationship. For example, you can establish a result set in which each row describes an employee and a potential mentor for that employee. (A potential mentor is an employee with a higher job level.) The resulting SQL might look like this:
SELECT employee.fname, employee.lname, mentor.fname, mentor.lname FROM employee INNER JOIN employee mentor ON employee.job_lvl < mentor.job_lvlNotice that the join uses a condition other than equality.
- Using a table twice without a self-join Even without a self-join, you can use the same table twice (or more) in a query. For example, you can establish a result set containing the other books by the author or authors of your favorite book. In this case, you use the titleauthors table twice
— once to find the authors of your favorite book (Is Anger the Enemy?), and once to find the other books by those authors. The resulting SQL might look like this: SELECT other_title.title FROM titles favorite_title INNER JOIN titleauthor favorite_titleauthor ON favorite_title.title_id = favorite_titleauthor.title_id INNER JOIN authors ON favorite_titleauthor.au_id = authors.au_id INNER JOIN titleauthor other_titleauthor ON authors.au_id = other_titleauthor.au_id INNER JOIN titles other_title ON other_titleauthor.title_id = other_title.title_id WHERE favorite_title.title = 'Is Anger the Enemy?' AND favorite_title.title <> other_title.titleNote To distinguish between the multiple uses of any one table, the preceding query uses the following aliases: favorite_title, favorite_titleauthor, other_titleauthor, and other_title.
Using views, user-defined functions, and subqueries in place of a table
Whenever you write a query, you articulate what columns you want, what rows you want, and where the query processor should find the original data. Typically, this original data consists of a table or several tables joined together. But the original data can come from sources other than tables. In fact, it can come from views, user-defined functions that return a table, or subqueries.
Using a view in place of a table
You can select rows from a view. For example, suppose the database includes a view called “ExpensiveBooks,” in which each row describes a title whose price exceeds 19.99. The view definition might look like this:
SELECT *
FROM titles
WHERE price > 19.99
You can select the expensive psychology books merely by selecting the psychology books from the ExpensiveBooks view. The resulting SQL might look like this:
SELECT *
FROM ExpensiveBooks
WHERE type = 'psychology'
Similarly, a view can participate in a JOIN operation. For example, you can find the sales of expensive books merely by joining the sales table to the ExpensiveBooks view. The resulting SQL might look like this:
SELECT *
FROM sales
INNER JOIN
ExpensiveBooks
ON sales.title_id
= ExpensiveBooks.title_id
Using a user-defined function in place of a table
In Microsoft SQL Server 2000, you can create a user-defined function that returns a table. Such functions are useful for performing complex or procedural logic.
For example, suppose the employee table contains an additional column, employee.manager_emp_id, and that a foreign key exists from manager_emp_id to employee.emp_id. Within each row of the employee table, the manager_emp_id column indicates the employee’s boss. More precisely, it indicates the employee’s boss’s emp_id. You can create a user-defined function that returns a table containing one row for each employee working within a particular high-level manager’s organizational hierarchy. You might call the function fn_GetWholeTeam, and design it to take an input variable
You can write a query that uses the fn_GetWholeTeam function as a source of data. The resulting SQL might look like this:
SELECT *
FROM
fn_GetWholeTeam ('VPA30890F')
“VPA30890F” is the emp_id of the manager whose organization you want to retrieve.
Using a subquery in place of a table
You can select rows from a subquery. For example, suppose you have already written a query retrieving titles and identifiers of the coauthored books
SELECT
titles.title_id, title, type
FROM
titleauthor
INNER JOIN
titles
ON titleauthor.title_id
= titles.title_id
GROUP BY
titles.title_id, title, type
HAVING COUNT(*) > 1
You can then write another query that builds on this result. For example, you can write a query that retrieves the coauthored psychology books. To write this new query, you can use the existing query as the source of the new query’s data. The resulting SQL might look like this:
SELECT
title
FROM
(
SELECT
titles.title_id,
title,
type
FROM
titleauthor
INNER JOIN
titles
ON titleauthor.title_id
= titles.title_id
GROUP BY
titles.title_id,
title,
type
HAVING COUNT(*) > 1
)
co_authored_books
WHERE type = 'psychology'
The emphasized text shows the existing query used as the source of the new query’s data. Note that the new query uses an alias (“co_authored_books”) for the existing query.
Similarly, a query can participate in a JOIN operation. For example, you can find the sales of expensive coauthored books merely by joining the ExpensiveBooks view to the query retrieving the coauthored books. The resulting SQL might look like this:
SELECT
ExpensiveBooks.title
FROM
ExpensiveBooks
INNER JOIN
(
SELECT
titles.title_id,
title,
type
FROM
titleauthor
INNER JOIN
titles
ON titleauthor.title_id
= titles.title_id
GROUP BY
titles.title_id,
title,
type
HAVING COUNT(*) > 1
)
You can order the rows in a query result. That is, you can name a particular column or set of columns whose values determine the order of rows in the result set. There are several ways in which you can use ordering:
- You can arrange rows in ascending or descending order By default, SQL uses order-by columns to arrangesrows in ascending order. For example, to arrange the book titles by ascending price, simply sort the rows by the price column. The resulting SQL might look like this:
SELECT * FROM titles ORDER BY priceOn the other hand, if you want to arrange the titles with the more expensive books first, you can explicitly specify a highest-first ordering. That is, you indicate that the result rows should be arranged by descending values of the price column. The resulting SQL might look like this:
SELECT * FROM titles ORDER BY price DESC - You can sort by multiple columns For example, you can create a result set with one row for each author, ordering first by state and then by city. The resulting SQL might look like this:
SELECT * FROM authors ORDER BY state, city - You can sort by columns not appearing in the result set For example, you can create a result set with the most expensive titles first, even though the prices do not appear. The resulting SQL might look like this:
SELECT title_id, title FROM titles ORDER BY price DESC - You can sort by derived columns For example, you can create a result set in which each row contains a book title
— with the books that pay the highest royalty per copy appearing first. The resulting SQL might look like this: SELECT title, price * royalty / 100 as royalty_per_unit FROM titles ORDER BY royalty_per_unit DESC(The formula for calculating the royalty that each book earns per copy is emphasized.)
To calculate a derived column, you can use SQL syntax, as in the preceding example, or you can use a user-defined function that returns a scalar value.
- You can sort grouped rows For example, you can create a result set in which each row describes a city, plus the number of authors in that city
— with the cities containing many authors appearing first. The resulting SQL might look like this: SELECT city, state, COUNT(*) FROM authors GROUP BY city, state ORDER BY COUNT(*) DESC, stateNotice that the query uses state as a secondary sort column. Thus, if two states have the same number of authors, those states will appear in alphabetical order.
- You can sort using international data That is, you can sort a column using collating conventions that differ from the default conventions for that column. For example, you can write a query that retrieves all the book titles by the Icelandic novelist Halldor Laxness. To display the titles in alphabetical order, you use an Icelandic collating sequence for the title column. The resulting SQL might look like this:
SELECT title FROM authors INNER JOIN titleauthor ON authors.au_id = titleauthor.au_id INNER JOIN titles ON titleauthor.title_id = titles.title_id WHERE au_fname = 'Halldor' AND au_lname = 'Laxness' ORDER BY title COLLATE SQL_Icelandic_Pref_CP1_CI_AS