The matrix multiplication sample application performs multiplication of two matrices using 3 different implementations. All implementations are using ANSI C code.
The sample takes a command line argument that defines which of the matrix multiplication implementations will be executed. See the following table for descriptions of the 3 implementations and the command line argument that invokes each one.
This sample demonstrates how the CPU Profiler can be used to detect bottlenecks, identify problematic memory access patterns, and verify improved performance.
To select which implementation of the matrix multiplication will be performed, open the CodeXL Project Settings dialog, or in Visual Studio open the VS Project Settings dialog.
|
# |
Multiplication Implementation |
Command line argument |
Description |
|
1. |
Inefficient |
|
Inefficient implementation that performs redundant loop iterations. |
|
2. |
Classic |
-c |
Classic textbook implementation that uses naïve nested loops. The loops perform a sub-optimal memory access pattern. |
|
3. |
Improved |
-i |
Improved implementation that uses nested loops with continuous memory access pattern. |
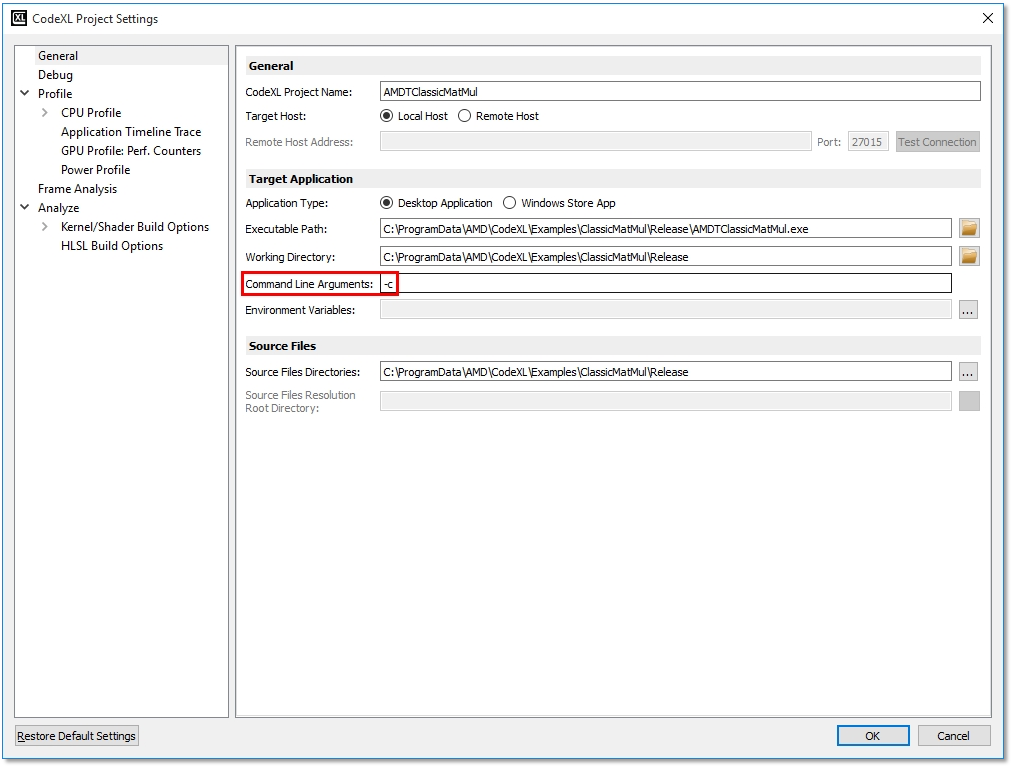
Project Settings for launching the classic implementation of matrix multiplication using the –c command line argument
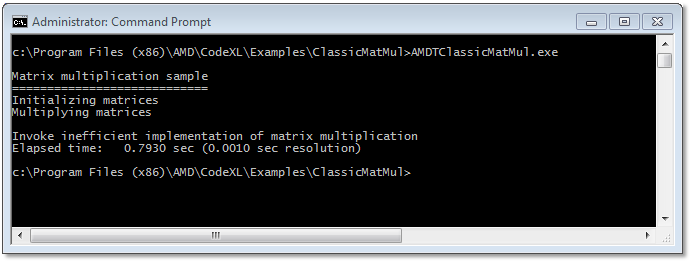
Use Time-Based Profiling to detect the redundant loop iterations in the inefficient implementation (launched by not supplying any command line argument).
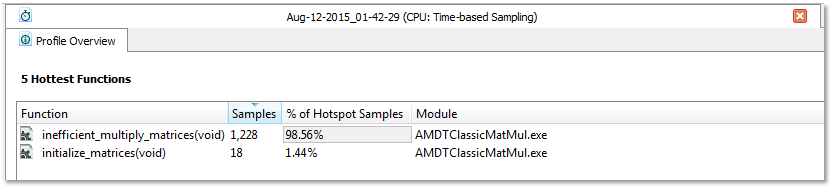
Double clicking the inefficient_multiply_matrices(void) opens the source code view which demonstrates why this function is not efficient:
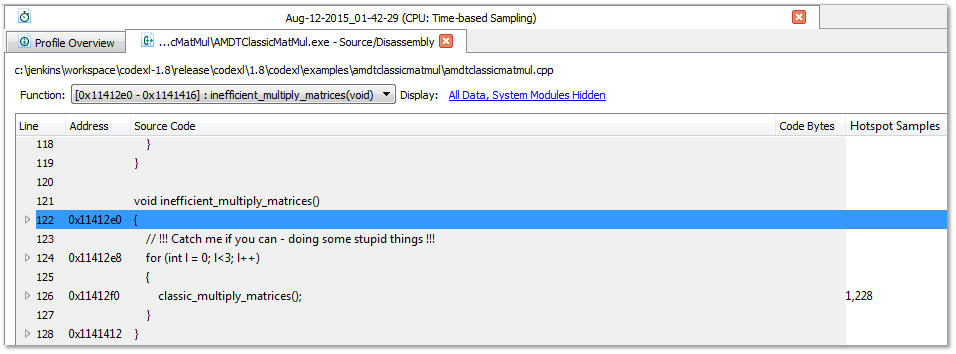
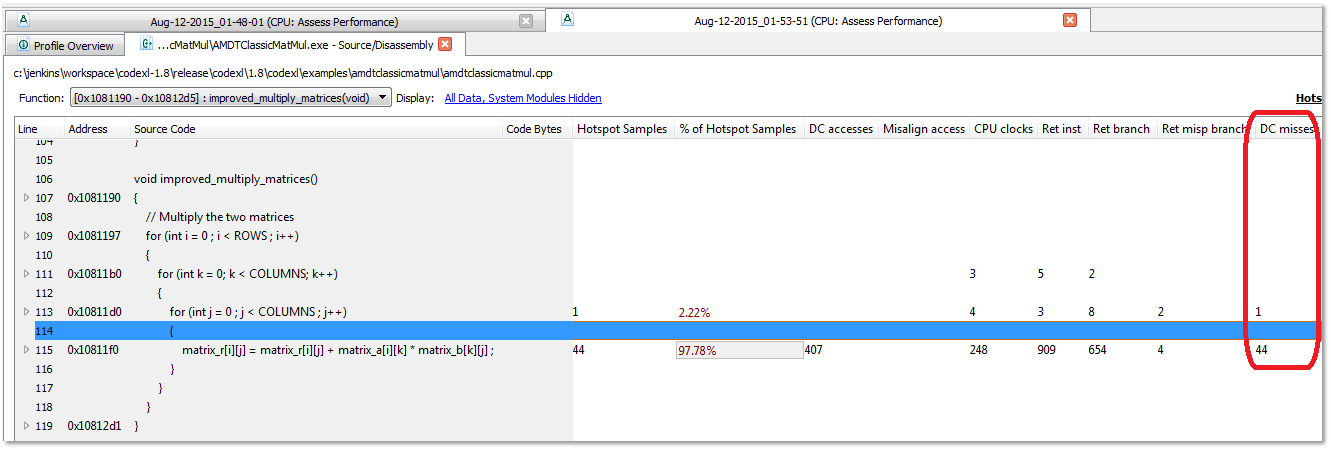
Use Event-Based Profiling with the Assess Performance session type to diagnose the problems in the classic implementation (launched by supplying “-c” as the command line argument):
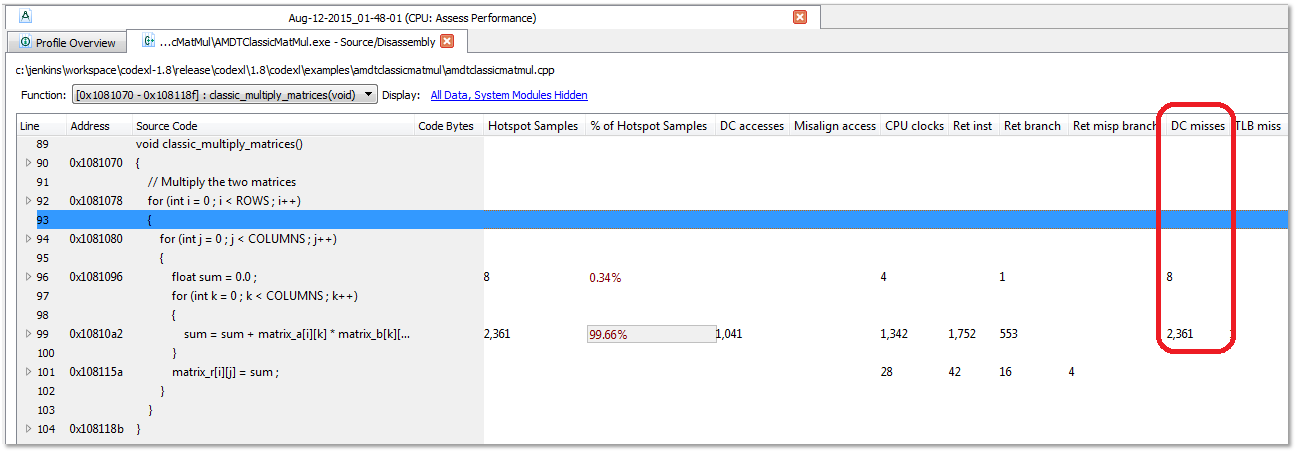
Large number of cache misses in the internal nested loop non-sequential access to arrays
Finally, executing the improved implementation (launched by supplying “-i” as the command line argument) shows the number of cache misses is significantly reduced: