20.1.4 Auto Scaling Considerations
These examples are mostly focused on triggering scaling events rather than working out real-world settings for when to scale up and when to scale down. This is because each application and its users create a unique scenario of variability of load and appropriate maximum response times. Some applications may be fine with maximum response times of 30 seconds or more provided the average stays below 2 seconds. Whereas others would want to ensure that never occurs and hence scale out much more quickly.
It would be very desirable to be able to demonstrate the auto scaling, but it takes 20 minutes to bring a web server alive and so a demonstration needs to take at least 60 minutes to show it scaling out and then scaling back. That would usually be impractical. The tutorials provide a manual demonstration of scaling that will need to suffice.
Firstly, use a large database instance that will cope with the maximum expected load as it cannot be scaled out without taking the whole system down. Thus the number of EC2 instances will control response time which the Auto Scaling Group (ASG) manages.
These tests were run in a Single Availability Zone (AZ) stack rather than the default Multi-AZ Stack. This should make no essential difference to the scaling process as the alarms are purely based on CPU utilization inside the EC2 instances which is not effected by accessing the RDS instance in another AZ. Yes, the average response time is slower but the amount of CPU used will be about the same, there will just be some sub-second delays in execution which will not change the per minute CPU utilization.
The scaling works on the average CPU utilization of the existing instances. Only the Web Server ASG is configured to scale out. If there are no existing instances in this ASG, there is no average CPU utilization and so scaling cannot occur. Thus there must be at least 1 instance in this ASG.
Why do we not just have one ASG? What is the purpose of having two? This is because updating the database must be managed by a single instance. There cannot be more than one instance responsible for changing tables otherwise the state of the database stored on the instance and the state of the tables in the RDS will not match. It's critical for table updates like adding a column that the web server matches the database server state. Hence there must only be 1 web server responsible for this. This is what the DBWebServer ASG exists for. To ensure that 1 and only 1 web server instance is running which is in control of changing the database state.
In the CloudWatch AWS Console change the WebServerApp CPUAlarmHigh from >70 for 15 minutes to > 70 for 5 minutes. This will allow the scaling to occur more quickly. Also change the WebServerApp CPUAlarmLow from <30 for 15 minutes to <30 for 5 minutes.
Now change scaling policy for both alarms to wait 1200 seconds (20 minutes) before allowing another scaling event. This must be at least as long as it takes to get an instance up and running and also then to positively affect the CPU utilization.
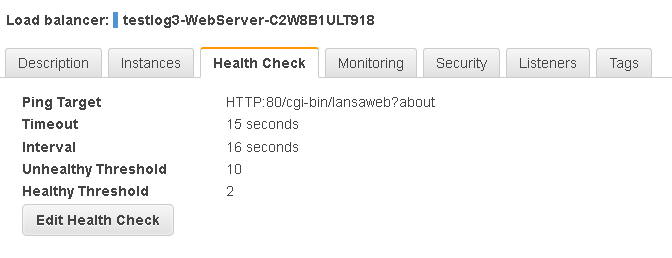
Reduce the ELB health check so that an instance is recognized as Healthy as quickly as possible. The Timeout must be more than most response times. Preferably more than the maximum response time. In this case 15 seconds may keep the instance healthy whilst allowing scaling to occur ASAP. Make the Interval 1 second longer at 16 seconds, the Unhealthy Threshold to the maximum of 10 and the Healthy Threshold to the minimum of 2. This takes health out of the equation as much as possible to allow the ASG to scale as it becomes necessary without instances taking too long to become healthy nor be terminated too soon when under load.
A load test was then run on this LANSA Stack with 30 virtual users for 43 minutes. This scaled out from 1 to 3 instances and then once the load finished, gradually reduced back to 1 instance.