The output file generated by the Simulator Results Analyzer contains detailed information about each utterance and the decisions that the speech recognition engine made when recognizing each utterance. In addition, the Analysis section of the output file contains calculated percentages and totals that summarize the results of recognition for the entire batch of utterances used as input to Simulator. The information in the Analysis section will help you do the following:
Evaluate the overall accuracy for your grammars.
Examine out-of-grammar (OOG) phrases and consider whether to add them as synonyms for in-grammar phrases.
Identify the confidencelevel setting for speech recognition engine that provides optimum recognition accuracy.
Interpreting Accepted and Rejected Recognitions
To interpret the output of the Simulator Results Analyzer, it is useful to have some insight into the decisions that a speech recognition engine makes during recognition. For a given speech recognition grammar, a given utterance, and a given confidencelevel setting, a speech recognition engine can make one of five choices.
Correctly recognize (accept) an in-grammar utterance (CA/in). This means that:
There is a phrase in the grammar that is intended to capture the utterance.
The recognizer matches the utterance to the phrase.
The recognizer assigns a confidence score to the recognition result that is greater than or equal to its confidencelevel setting.
Correctly reject an out-of-grammar utterance (CR/out). This means that:
There is no phrase in the grammar that is intended to capture the utterance.
The recognizer does not create a recognition result or assigns a confidence score to the recognition result that is less than its confidencelevel setting.
Falsely reject an in-grammar utterance (FR/in). This means that:
There is a phrase in the grammar that is intended to capture the utterance.
The recognizer does not create a recognition result or assigns a confidence score to the recognition result that is less than its confidencelevel setting.
Falsely recognize (accept) an in-grammar utterance (FA/in). This means that:
There is a phrase in the grammar that is intended to capture the utterance.
The recognizer matches the utterance to a different phrase in the grammar.
The recognizer assigns a confidence score to the recognition result that is greater than or equal to its confidencelevel setting.
Falsely recognize (accept) an out-of-grammar utterance (FA/out). This means that:
There is no phrase in the grammar that is intended to capture the utterance.
The recognizer incorrectly matches the utterance to a phrase in the grammar.
The recognizer assigns a confidence score to the recognition result that is greater than or equal to its confidencelevel setting.
The examples in the following table provide additional clarification on these five categories. In each example it is assumed that the grammar consists of the names of cities in the United States, and that the application prompt is "For which city would you like the weather?"
Category | Example |
|---|---|
CA/in (Confidence score => confidencelevel) | Caller: "Boston" Application: "The weather in Boston is ..." |
CR/out (Confidence score < confidencelevel) | Caller: "Pizza" Application: "I didn't understand that" |
FR/in (Confidence score < confidencelevel) | Caller: "Boston" Application: "I didn't understand that" |
FA/in (Confidence score => confidencelevel) | Caller: "Boston" Application: "The weather in Austin is ..." |
FA/out (Confidence score => confidencelevel) | Caller: "Pizza" Application: "The weather in Poughkeepsie is ..." |
For a list and description of all the elements and attributes in the output file that the Simulator Results Analyzer produces, see Simulator Results Analyzer Input and Output File Format.
Evaluating the Overall Accuracy of Your Grammars
The Analysis section in the output file provides counts and percentages for all utterances that were not correctly recognized. You can evaluate the overall accuracy of your grammars by looking at how many errors were generated, and what percentage this number constitutes in the total of all attempted recognitions. There are separate error categories for words, phrases, and semantics. The following excerpt from the output file shown in Simulator Results Analyzer Input and Output File Format shows the summary of recognition errors for a batch of utterances.
| Copy Code | |
|---|---|
<Analysis> <WordError wordCount="13" insertions="0" deletions="3" substitutions="1" rate="0.3076923" /> <PhraseError phraseCount="11" correct="8" incorrect="3" rate="0.2727273" /> <SemanticError phraseCount="11" correct="10" incorrect="1" rate="0.0909091" /> | |
In the WordError element, the rate attribute indicates what percentage of the attempts to recognize individual words were unsuccessful. The deletions attribute contains the number of words for which there was no recognition result. The substitutions attribute contains the number of words that were incorrectly matched to a phrase in a grammar.
The figures for SemanticError are particularly important, because they indicate that an incorrect semantic result was returned to your application. The semantics of a recognized phrase are the actionable portion of a recognition result for your application. In the FA/In example in the table above, there is a mismatch between the semantics of what the caller said (Boston) and the semantics of the recognition result (Austin). Because the semantics do not match, the caller receives the weather report for the wrong city.
Out-of-Grammar Utterances
Words that were not in the grammar but that were accepted for an in-grammar phrase by mistake may indicate that you can improve a grammar's performance by adding one or more phrases. The OutOfGrammar section in the output file lists each out-of-grammar phrase that was mistakenly recognized for a phrase in the grammar and keeps a count of how many times each phrase was accepted in error. An out-of-grammar word that is repeatedly accepted in error for in-grammar phrase may be a good candidate for adding to a grammar.
The following excerpt from the output file shown in Simulator Results Analyzer Input and Output File Format shows the summary of out-of-grammar utterances for a batch of recognitions.
| Copy Code | |
|---|---|
<OutOfGrammar total="3"> <Phrase count="1">[noise]</Phrase> <Phrase count="1">sport</Phrase> <Phrase count="1">top stories</Phrase> </OutOfGrammar> | |
In the above example, the utterance "sport" may be a candidate for adding to the grammar. It was probably misrecognized for a phrase in the grammar (sports). You can determine this by inspecting the individual recognition result for the utterance "sport", shown below. You can see that the speech recognition engine produced the recognition result "sports" (RecoResultText) from the utterance "sport" (TranscriptText), even though the word "sport" is not in the grammar (InGrammar).
| Copy Code | |
|---|---|
<Utterance id="utterance_0.0.6.0"> <AudioUri>../Samples/Sample%20Simulator/waves/utt_06.wav</AudioUri> <AudioType>audio/x-wav</AudioType> <TranscriptText>sport</TranscriptText><RecoResultText>sports</RecoResultText> <RecoResultSemantics ms:typespace="ECMA-262" ms:dataType="object" xmlns:ms="http://www.microsoft.com/xmlns/webreco" xmlns:emma="http://www.w3.org/2003/04/emma"> <application emma:confidence="0.9370015" ms:actualConfidence="1" ms:dataType="string" ms:valueType="string" xmlns="">SPORTS</application> <grammar emma:confidence="0.9370015" ms:actualConfidence="1" ms:dataType="string" ms:valueType="string" xmlns="">menu_choices.grxml</grammar> </RecoResultSemantics> <RecoResultRuleTree> <Rule id="top" uri="grammars\menu_choices.grxml">sports</Rule> </RecoResultRuleTree> <RecoResultPronunciation>S P AO RA T S</RecoResultPronunciation> <RecoResultConfidence>0.9216749</RecoResultConfidence> <RecoResultSemanticConfidence>0.9370015</RecoResultSemanticConfidence> <InGrammar>False</InGrammar> <SemanticsMatch>False</SemanticsMatch> <WordError wordCount="1" insertions="0" deletions="0" substitutions="1" /> </Utterance> | |
Adding commonly mispronounced words to your grammar can improve its performance and increases the likelihood that mispronunciations return the same semantic results back to the application as a correct pronunciation.
Choosing the Optimum confidencelevel Setting
Simulator Results Analyzer uses the confidence scores that the speech recognition engine assigns to each utterance to calculate acceptance and rejection rates for each of the available confidencelevel settings that are available on the Microsoft speech recognition engine. There are two ConfidenceThreshold sections in the output file; one for phrases and one for semantics.
The <ConfidenceThreshold type="phrase"> sections shows how the confidencelevel setting on the speech recognition engine affects acceptance/rejection rates for recognized phrases.
The <ConfidenceThreshold type="semantics"> shows how the confidencelevel on the speech recognition engine affects the acceptance/rejection rates for the semantics of recognized phrases.
By inspecting the results in the ConfidenceThreshold sections, you can identify the confidence level that produces the best results for the batch of input utterances. It is important to understand that no single metric can fully describe speech recognition accuracy. Often, improving one metric can have a negative effect on another metric. Reducing the number of false acceptances can raise the number of false rejections.
 Important Important |
|---|
To properly assess the confidence threshold setting for your application via the output of Simulator Results Analyzer, set confidencelevel="0" in the configuration file that you specify in the /RecoConfig option on the command line when you launch the Simulator tool. This will ensure that all recognitions are returned, regardless of confidence score. |
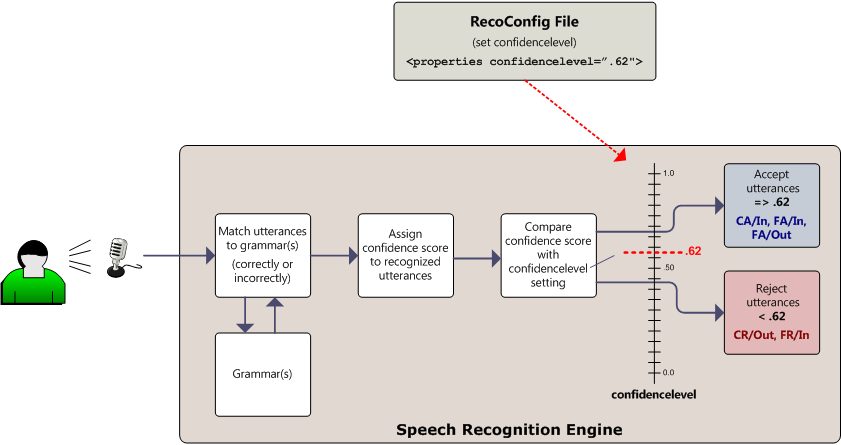
The following diagram illustrates the roles played by the confidence score assigned to an utterance (by the speech recognition engine) and the speech recognition engine's confidencelevel setting (which you can set) in determining whether or not the utterance is accepted (recognized). Whether correctly or incorrectly recognized, whether in-grammar or out-of-grammar, an utterance is accepted if the confidence score assigned by the speech recognition engine to the utterance is greater than or equal to the value of its confidencelevel. The speech recognition engine contains logic that calculates a confidence score for each utterance and its semantics. You can set the confidencelevel of the speech recognition engine in the RecoConfig file. See Speech Recognition Engine Configuration File Settings.