Speech API Overview
The Microsoft Speech Platform application programming interface (API) dramatically reduces the code overhead required for an application to use speech recognition and text-to-speech, making speech technology more accessible and robust for a wide range of applications.
This section covers the following topics:
API Overview
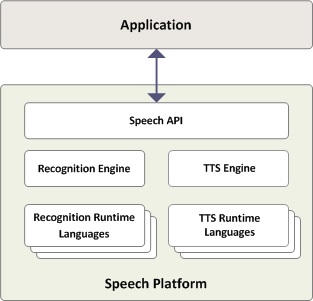
The Microsoft Speech Platform API provides a high-level interface between an application and speech engines. The Speech Platform API implements all the low-level details needed to control and manage the real-time operations of various speech engines.
You can manage two types of speech engines using the Speech Platform API: speech synthesis engines (text-to-speech or TTS) and recognition engines (speech recognizers). TTS engines synthesize text strings and files into spoken audio using synthetic voices. Speech recognizers convert human spoken audio into readable text strings and files.
API for Text-to-Speech
Applications can control text-to-speech (TTS) using the ISpVoice Component Object Model (COM) interface. Once an application has created an ISpVoice object, the application only needs to call ISpVoice::Speak to generate speech output from some text data. In addition, the IspVoice interface also provides several methods for changing voice and synthesis properties such as speaking rate ISpVoice::SetRate, output volume ISpVoice::SetVolume, and changing the current speaking voice ISpVoice::SetVoice
Using the Speech Platform API, you can also insert special controls together with the input text to change real-time synthesis properties like voice, pitch, word emphasis, speaking rate, and volume. This synthesis markup, using standard XML format, is a simple but powerful way to customize TTS speech, independent of the specific engine or voice currently in use.
The IspVoice::Speak method can operate either synchronously (return only when completely finished speaking) or asynchronously (return immediately and speak as a background process). When speaking asynchronously (SPF_ASYNC), you can poll for real-time status information such as speaking state and current text location using ISpVoice::GetStatus. Also while speaking asynchronously, you can generate new speech output by either immediately interrupting the current output (SPF_PURGEBEFORESPEAK), or by automatically appending new text to the end of the current output.
In addition to the ISpVoice interface, the Speech Platform API also provides many utility COM interfaces for more advanced TTS applications.
Events
The Speech Platform API communicates with applications by sending events using standard callback mechanisms (Window Message, callback proc, or Win32 Event). You typically use TTS events for synchronizing to the speech output. Applications can synchronize to real-time actions as they occur such as word boundaries, phoneme or viseme (mouth animation) boundaries, or custom bookmarks. Applications can initialize and handle these real-time events using ISpNotifySource, ISpNotifySink, ISpNotifyTranslator, ISpEventSink, ISpEventSource, and ISpNotifyCallback.
Lexicons
Applications can provide custom word pronunciations for speech synthesis engines using methods provided by ISpContainerLexicon, ISpLexicon and ISpPhoneConverter.
Resources
You can find and select speech data, such as voice files and pronunciation lexicons, using the following COM interfaces in the Speech Platform API: ISpDataKey, ISpRegDataKey, ISpObjectTokenInit, ISpObjectTokenCategory, ISpObjectToken, IEnumSpObjectTokens, ISpObjectWithToken, and ISpResourceManager.
Audio
Finally, there is an interface for customizing the audio output to some special destination such as telephony and custom hardware (ISpAudio, ISpMMSysAudio, ISpStream, ISpStreamFormat, ISpStreamFormatConverter). Back to top
Back to topAPI for Speech Recognition
Just as ISpVoice is the main interface for speech synthesis, ISpRecoContext is the main interface for speech recognition. Like the ISpVoice, ISpRecoContext is an ISpEventSource, which means that it is the speech application's vehicle for receiving notifications for the requested speech recognition events.
An application has the choice of two different types of speech recognition engines (ISpRecognizer). A shared recognizer, which may be shared with other speech recognition applications, is recommended for most speech applications. To create an ISpRecoContext for a shared ISpRecognizer, an application need only call COM's CoCreateInstance on the component CLSID_SpSharedRecoContext. In this case, the Speech Platform API will set up the audio input stream, setting it to the default audio input stream. For large server applications that run alone on a system, and for which performance is key, an in-process (InProc) speech recognition engine is more appropriate. To create an ISpRecoContext for an InProc ISpRecognizer, the application must first call CoCreateInstance on the component CLSID_SpInprocRecoInstance to create its own InProc ISpRecognizer. Then the application must make a call to ISpRecognizer::SetInput (see also ISpObjectToken) to set up the audio input. Finally, the application can call ISpRecognizer::CreateRecoContext to obtain an ISpRecoContext.
The next step is to register for notifications of events that are of interest to your application. As the ISpRecognizer is also an ISpEventSource, which in turn is an ISpNotifySource, your application can call one of the ISpNotifySource methods from its ISpRecoContext to indicate where the events for that ISpRecoContext should be reported. Then it should call ISpEventSource::SetInterest to indicate for which events it wants to receive notification. The most important event is SPEI_RECOGNITION, which indicates that the ISpRecognizer has recognized some speech for this ISpRecoContext. See SPEVENTENUM for details on the other available speech recognition events.
Finally, a speech application must create, load, and activate an ISpRecoGrammar. The recognition engine uses the contents of ISpRecoGrammar to define the utterances that can be recognized, either free dictation (broad coverage of the words in a language), or a limited set of words and phrases specific to your application (command and control). First, the application creates an ISpRecoGrammar using ISpRecoContext::CreateGrammar. Then, the application loads the grammar, either by calling ISpRecoGrammar::LoadDictation for dictation, or one of the ISpRecoGrammar::LoadCmdxxx methods for command and control. To activate these grammars so that recognition can start, the application calls ISpRecoGrammar::SetDictationState for dictation or ISpRecoGrammar::SetRuleState or ISpRecoGrammar::SetRuleIdState for command and control.
When recognition results come back to the application by means of the requested notification mechanism, the lParam member of the SPEVENT structure will be an ISpRecoResult, from which the application can determine what was recognized and for which ISpRecoGrammar of the ISpRecoContext.
An ISpRecognizer, whether shared or InProc, can have multiple ISpRecoContexts associated with it, and each one can be notified in its own way of events pertaining to it. An ISpRecoContext can have multiple ISpRecoGrammars created from it, each one for recognizing different types of utterances.