| Microsoft XML Core Services (MSXML) 5.0 for Microsoft Office - XSLT Developer's Guide |  |
How the MSXML Processor Parses White Space
When MSXML parses an XML document, all white space in the document is preserved and passed to a downstream application.
The built-in XSLT processor is not the downstream application that receives the output of the MSXML parser. This can be confusing to developers who are new to MSXML. The following diagram shows the intermediate steps that receive the output of the parser, build a Document Object Model (DOM) tree, and cache this tree in memory for ready access later.
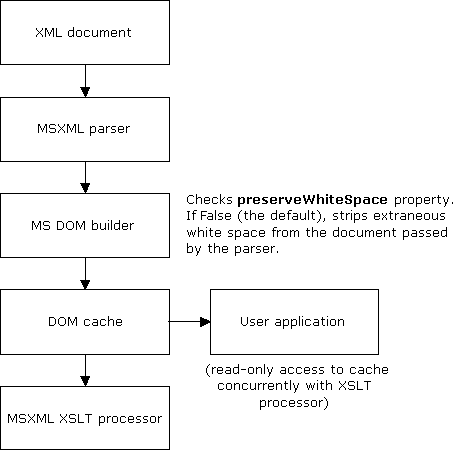
The input document that the XSLT processor works with, therefore, is actually the DOM tree in memory. By default, the Microsoft DOM tree builder removes extraneous white space from the document passed to it by the parser. Any content that is not in the scope of an xml:space attribute whose value is "preserve" is extraneous in this context.
To override this default and retain the original document's extraneous white space in the DOM tree, you must set the preserveWhiteSpace property to True at the time the DOM is loaded. In other words, you cannot preserve the original document's extraneous or insignificant white space using XSLT features alone. By the time the XSLT processor sees a version of the original the document, all such white space has, by default, been stripped.
The only way to set the preserveWhiteSpace property to True is to process the DOM through script or a programming language. For more information, see White Space and the DOM.