| Microsoft XML Core Services (MSXML) 5.0 for Microsoft Office - XPath Developer's Guide |  |
Sample Document Root Element Sub-Tree
If the diagrams in Sample Tree for the Document Root were all of the document's content that XPath exposed, quite a bit of content would still be inaccessible for linking or transforming purposes. Fortunately, there is also a sub-tree available within the <books> root element highlighted above.
Fully expanded, the <book> element's sub-tree looks like this:
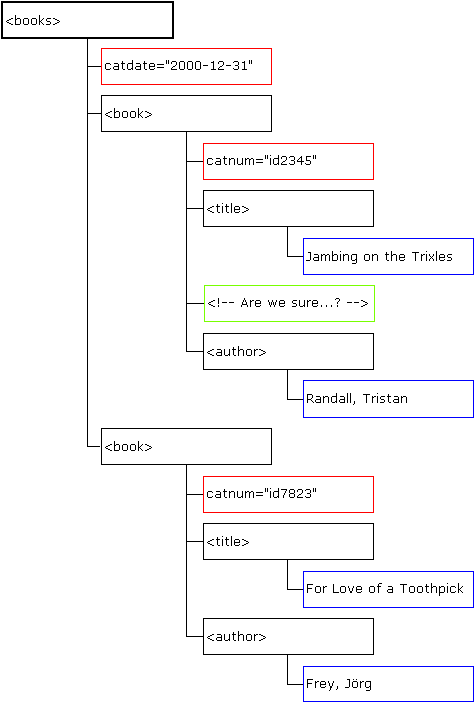
Note For simplicity, the above diagram disregards the newline characters following each element's end tag. For more information, see Controlling White Space with XSLT.
Like the full document tree shown in the preceding section, this sub-tree consists of a number of nested containers. While there is no Processing Instruction node type in this sub-tree, there could be; in addition, it shows the following node types:
- element nodes (outlined in black), such as
<books>itself,<book>,<title>, and<author> - attribute nodes (red),
catdateandcatnum - text nodes (blue), such as "Randall, Tristan" and "For Love of a Toothpick"
- comment nodes (green), of which there is only one here
Note The text node showing the name of the author of "For Love of a Toothpick." In the tree it appears as "Frey, Jörg" with the entity substitution made. As with the XML and document-type declarations, entity declarations are invisible to XPath and XSLT processors; all that these processors see is the complete document as parsed, including the expanded form of entities.
A seventh node type, namespace nodes, may or may not be present in a document. A namespace node consists of a prefix and a URI to which the prefix is bound, and exists implicitly for any element or attribute node within the scope of the element which declares the namespace prefix. The xml: prefix is by default in effect for all XML documents.
See Also
Sample XML File for XPath Tree Model