Data Mining Column Content Types
There are five basic column content types, each of which is described later in this topic. Do not confuse column content type with column data type; a column content type provides the role that a column fulfills for a data mining model. A key column, for example, can have a column data type of LONG or TEXT and still serve the role of key column. Attribute and table columns, two column types discussed later in this topic, can also be used as prediction columns.
The column types and their associated properties allow the data mining algorithm provider to make some sense of the training data provided to it during the training process.
The following case diagram is used later in the topic to explain column types.

For more information about cases, see Introduction to Data Mining Models.
Key Columns
A key column (or columns) uniquely identifies a row. For example, the CustomerID and OrderItemID columns in the case diagram represent key columns. A case may be uniquely identified by one or more key columns.
Attribute Columns
Attribute columns provide information about direct attributes of the case. In the case diagram, the Age and Gender columns both represent attribute columns. An attribute column is further defined by a domain and handling hints.
Domains
A domain, or the set of possible values that can appear in the attribute column, further defines attribute columns. Domains are classified into a few simple groups, detailed in the following list.
DISCRETE
The values for the attribute column are discrete; this is the simplest form of attribute column. The Gender column in the case diagram represents a typical discrete attribute column, in that the data represents a finite, counted number of gender categories. The values in a discrete attribute column do not imply ordered data, even if numeric; the values are clearly separated, with no possibility of fractional values. Telephone area codes are a good example of numeric discrete data.
ORDERED
The values for the attribute column define an ordered set. Although there is an ordered set, no distance or magnitude information is implied. For example, if an ordered attribute column supplying information about a ranking of skill levels ranging from one to five is defined, there is no relative value between skill levels; a skill level of five is not necessarily five times better than a skill level of one. Ordered attribute columns are also considered to be discrete in terms of content type.
CYCLICAL
The values for the attribute column define a cyclical ordered set. An example of a cyclical ordered set is the numbered days of the week, as day number one follows day number seven.
Cyclical attribute columns are considered both ordered and discrete in terms of content type.
CONTINUOUS
The values for the attribute column define a continuous curve set. The values in the continuous curve are naturally ordered and have implicit distance and magnitude semantics. Unlike a discrete column, which represents finite, counted data, a continuous column represents measurement data with possibly infinite fractions of values. The Age column in the case diagram is an example of a continuous attribute column; the values in this column represent a measurement, in years, that could be represented by an infinite number of fractional values, such as 21.1, 21.003, and so on.
DISCRETIZED
The values for the attribute column define an ordered set transformed and modeled from continuous data supplied to the model. Some data mining algorithm providers cannot accept continuous attribute columns as input, or they may not be able to predict continuous values. For these cases, columns that have continuous domains can be employed as discretized attribute columns, in which the continuous values are grouped into discrete categories, so that the continuous data can be treated as discrete data for the purpose of analysis. For some data mining algorithm providers, discretized columns can take arguments to override default discretization behavior. The following list details currently supported discretization behavior flags.
- AUTOMATIC
- The data mining algorithm provider selects its default discretization method.
- EQUAL_AREAS
- The data mining algorithm provider attempts to divide the data into groups containing an equal number of continuous values. This method is best used for normal distribution curves, but will not work well for a high count of values in a narrow group in the continuous data. For example, if half of the order items specified in the case diagram are free, or have a Cost value of zero, then half the data is under a single point in the curve. For such a distribution, this method attempts to break such data up as part of establishing equal area discretization into multiple areas, producing undesirable results.
- THRESHOLDS
- The data mining algorithm provider attempts to divide the data into groups by reviewing the curve of the continuous data and searching for inflection points; this works well for continuous data that does not conform to a normal distribution, as the inflection points of such data can suggest reasonable boundaries for discretization.
- CLUSTERS
- The data mining algorithm provider attempts to divide the data into groups by sampling the training data, initializing to a number of random points, and running several iterations of the Expectation-Maximization (EM) clustering algorithm. This method is beneficial in that it will work on any distribution curve, but is more expensive in terms of processing time.
SEQUENCE_TIME
The values for the attribute column represent time measurement units. A time column does not have to contain a data type of any particular format; for example, a number representing periods or quarters is acceptable. The sequence time attribute column is typically used to associate a sequence time with individual attribute values such as purchase time.
Distributions
The domain of an attribute column classified as Continuous can also have a distribution associated with it. This is information given to the data mining algorithm provider describing the expected distribution of the column values that will be inserted into the model when trained. Specific values may be known to have typical distributions. For some algorithms, it is particularly beneficial to know the distribution ahead of time. If the distribution is not known or is not given, the provider may assume whatever distribution it finds convenient. Examples and diagrams of some distribution flags are included in the following table.
| Diagram | Distribution |
|---|---|
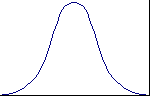 |
NORMAL
The values for the continuous attribute column form a histogram with a normal Gaussian distribution. For example, income values may form such a distribution curve. |
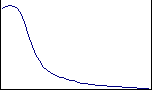 |
LOG_NORMAL
The values for the continuous attribute column form a Gaussian distribution histogram with all values greater than zero, where the curve possesses an elongated upper tail and a skew toward the low end of the curve. The quantity associated with the number of order items purchased would follow this curve if a value of zero is not explicitly recorded and most consumers tend to buy smaller numbers of the order item. |
 |
UNIFORM
The values for the continuous attribute column form a flat curve, in which all values are equally likely. |
Other supported distribution flags include:
- BINOMIAL
- MULTINOMIAL
- POISSON
- T-DISTRIBUTION
Hints
Other information can be given to the data mining algorithm provider to help it build good models of the training data. These modeling flags are provider-specific, but supported examples include the following.
MODEL_EXISTENCE_ONLY
The values for the attribute column are less important than the presence of the attribute. For example, the case diagram displays a list of order items associated with a given customer, including the ID, cost and product type of the order item. For modeling purposes, the fact that the customer purchased a given order item may be more important than the cost of the order item itself. In this case, the Cost column should be marked as Model Existence Only.
NOT NULL
The values for the attribute column should never contain a null value, and an error will result if a null value is encountered for this attribute column during the training process.
IGNORE NULL
The values for the attribute column can contain a null value, and the null value should not be considered informative by the data mining model. Null values will be ignored if encountered for this attribute column during the training process.
NULL INFORMATIVE
The values for the attribute column can contain a null value, and the null value should be considered informative by the data mining model. Null values will be modeled as a missing state if encountered for this attribute column during the training process.
Qualifier Columns
A qualifier column is a special type of attribute column that provides information about another attribute column to the data mining algorithm provider. The following list details currently supported qualifier column types, but third-party providers can add additional qualifier column types.
PROBABILITY
The value in this attribute column is the probability, as a number between zero and one, of the associated value.
VARIANCE
The value in this attribute column is the variance of the associated value.
STDEV
The value in this attribute column is the standard deviation of the associated value.
SUPPORT
The value in this attribute column is the weight (case replication factor) of the associated value.
PROBABILITY_VARIANCE
The value in this attribute column is the variance of the probability for the associated value.
PROBABILITY_STDEV
The value in this attribute column is the standard deviation of the probability for the associated value.
ORDER
The value in this attribute column is the ordering of the associated value.
Relation Columns
A relation column is a column used in a case to further classify another attribute, relation or key column, by pointing out a hierarchical relationship between attribute columns within the case set. For example, the ProductType column further classifies the ProductID column in the case diagram presented earlier in this topic; it provides a classification into which certain products fit. In effect, it establishes a hierarchy in that all products belong to a product type. A given relation value must always be consistent for all of the instance values of the other column that it describes. If a product is associated with a given product type, it must always be associated in the data with that product type.
Table Columns
A table column is a column that represents a set of data mining columns, also known as nested columns; it is described by a set of columns that are contained within the definition of a named table column. The OrderItems column in the case diagram represents a table column.
Prediction Columns
Attribute or table columns can be used as input columns, output columns, or both. The data mining algorithm provider will build a data mining model capable of predicting or explaining output column values based on the values of the input columns.
Prediction columns, besides serving as output columns, can also be used as input columns for other prediction columns within a case, allowing for complex predictive analysis. Not all data mining algorithm providers support all content types for prediction purposes; the capabilities of each data mining algorithm provider can be checked in the MINING_SERVICES schema rowset.
For more information about the MINING_SERVICES schema rowset, see MINING_SERVICES.
Predictions can convey not only simple information like the estimated age of a customer, but they can also convey additional statistical information, such as the confidence level and standard deviation. Further, the prediction may actually be a collection of predictions, such as the set of order items a customer is likely to buy based on a specific customer case. Each of the predictions in the collection may also include a set of statistics accompanying it, expressed as a histogram. A histogram provides multiple possible prediction values, each accompanied by a probability and other statistics. In this case, each prediction (which by itself can be part of a collection of predictions) may have a collection of possible values that constitutes a histogram.
Because the prediction information can be very detailed and complex, it is often necessary to extract only a portion of the prediction. For example, you may want to examine a specific prediction value or a range of values. Not every provider and every data mining model can support all of the possible requests. Therefore, it is necessary for the output column to indicate what kind of information may be extracted out of it, using transformation functions.
A set of standard transformation functions has been defined as part of the OLE DB for Data Mining specification.
For more information about the OLE DB for Data Mining specification, see the Microsoft OLE DB Web page at the Microsoft Web site.