Settings
From LogExpert
Settings
Choose "Settings" from the Options menu to open the settings dialog. The Settings is divided into 5 pages.
View settings
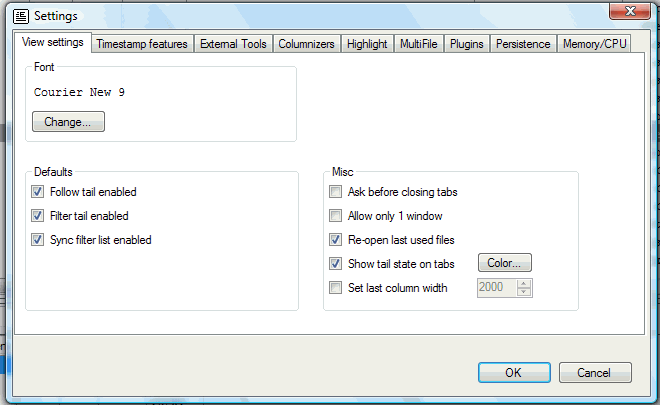
Font
Choose a font for the log file display.
Follow tail enabled
Configures if the Follow tail option is enabled by default.
Filter tail enabled
Configures if the Filter tail option is enabled by default. See Filter for details.
Sync filter list enabled
Configures if Sync filter is enabled by default. See Filter for details.
Ask before closing tabs
If checked, you will see a "really close?" dialog when closing a tab.
Allow only 1 instance
If checked, only one instance of LogExpert can be started. Additional instances will quit immediately. All files (given by command line args) will be loaded by the one and only running instance.
Re-open last used files
If checked, LogExpert will load the last used files on startup.
Show tail state on tabs
Shows an additional LED on every file tab. The LED shows the current state of Follow tail on every tab. See File handling for more information. The Color button lets you choose a color for the LED.
Set last column width
You can force a column width for the rightmost column. Just enable the option and adjust a value of your choice. The column with is applied every time a Columnizer is selected (i.e. loading a file or changing the Columnizer).
If you don't use this option, the width of the last column is determined automatically by using the width of the displayed lines when selecting a Columnizer.
Timestamp control
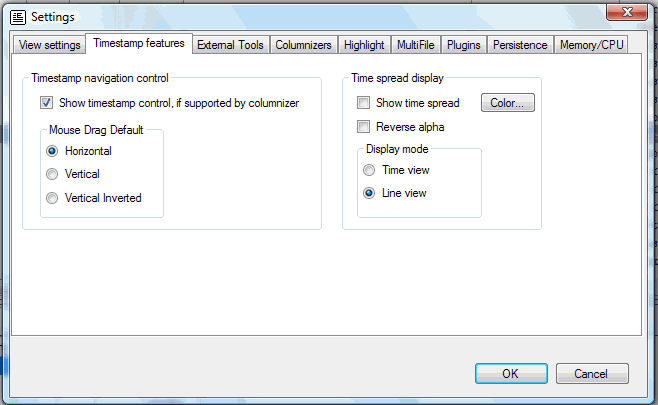
Choose here if you want to see the timestamp control in the status line. You can also choose how you want the control to operate: by left/right dragging or by up/down dragging. See Timeshift for more information.
The options for the Time spread display are described in the Time spread view help page.
External tools
The settings for the external tools are described in the External tools section of this document.
Columnizers
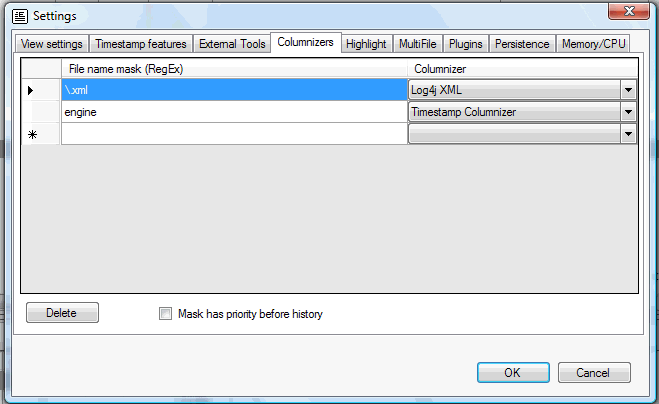
You can set default columnizers for file names matching a file name mask.
For adding new entries enter a file name mask into the empty field at the last line and choose a columnizer from the list. To delete an entry select it and click on the Delete button.
Mask has priority before history
If checked, the settings in this dialog will always be used when loading files. If not checked, the settings will only be used if no entry in the columnizer history is found for the file to be loaded. The columnizer history stores the last 40 file names with its columnizer selections.
Highlight

You can select default Highlight groups for file names matching a file name mask.
For adding new entries enter a file name mask into the empty field at the last line and choose a columnizer from the list. To delete an entry select it and click on the Delete button.
Multi File
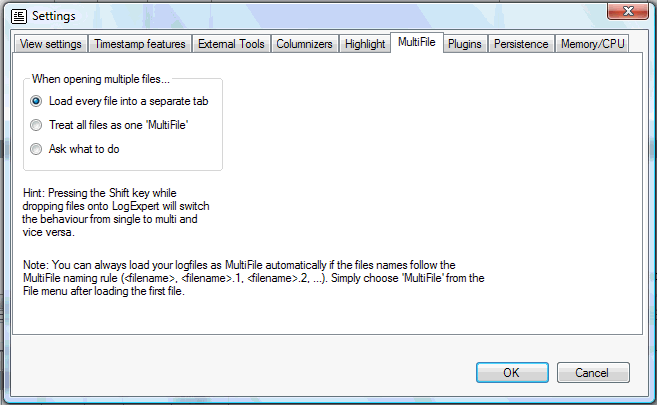
This page configures how LogExpert operates if you load multiple files at once. Multiple files can be loaded by selecting more than one file in the Open file dialog or by drag & drop multiple files onto LogExpert.
The default behaviour is to load every file into a separate tab window. But you can also configure that LogExpert treats the files as MultiFile. So you can use the MultiFile feature even if your file names don't fit the naming convention for the automatic MultiFile feature. Note that LogExpert cannot handle a logfile rollover with MultiFiles correctly, if the logfiles don't follow the naming convention.
Plugins

Here you can configure the plugins, if you have any plugins available. The config options depends on the plugin. If the plugins provides an in-place config dialog you will see the settings directly embedded on the Plugins tab (like in the screenshot above). If the plugin needs a larger GUI, it can provide it's own config dialog. In this case you will see a "Config" button which causes the plugin to show its own dialog.
Persistence
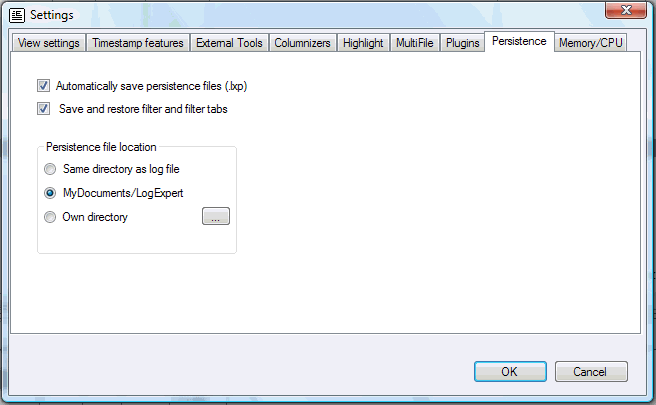
Here you can choose if LogExpert saved persistence files automatically. A persistence file is an XML files which contains informations about a logfile. You can also select an location where to store these files.
A persistence files has the file extension .lxp. If you Choose "Same directory as log file" the persistence file will have the same name as your log file (with added .lxp). If you choose one of the other options, the persistence file name is built from the absolute pathname of your log file (with added .lxp).
Memory / CPU
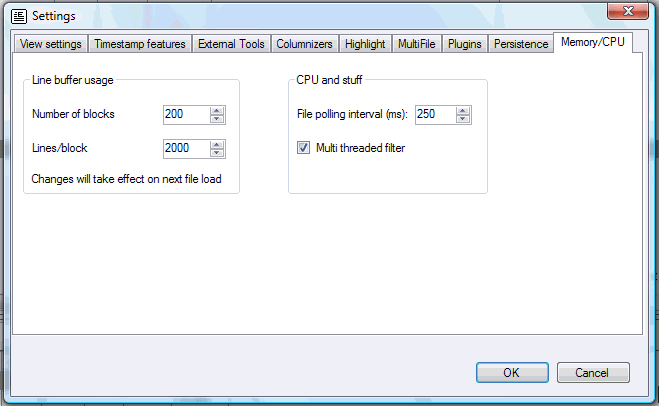
You can adjust the memory that uses LogExpert for buffering lines. Also you can adjust the file polling interval for the tail mode.
Buffer usage
The buffer usage for every file can be adjusted. When working with large files you should consider to increase the defaults. This will speed up operations like filtering a lot! This is especially true when opening log files directly from a network drive (which is not recommended for large files).
Here's how it works internally:
When loading files, LogExpert will group all lines into blocks. The number of lines per block can be adjusted. When the maximum number of blocks is reached, LogExpert will start to remove blocks from memory. The blocks which are used least will be removed at first. As soon as one of the lines of a removed blocks is needed again (because of scrolling or searching/filtering) the complete block will be reloaded from the file.
To find optimal sizes you can experiment a bit. For my system it seems be be a good choice to have large blocks (about 500 to 3000 lines) instead of too much blocks. But this experience may vary from system to system.
For a better performance the buffer limit will not be checked every time a block is added. Instead there's a kind of garbage collector thread which checks the number of blocks from time to time (10 secs interval for now). This means there may be a larger memory consumption for some seconds, before blocks are free'd by the garbage thread.
Buffer usage values count for every loaded file. If you have 10 large files open with settings of 2000 lines/block and number of blocks = 100, you will have 2.000.000 lines in memory. Beause the internal representation of strings is 2-byte-Unicode, every character will take 2 bytes of memory. That means, a 40 MB ASCII log file will consume about 80 MB memory if loaded completely.
If you're using LogExpert mostly as a tail tool (only viewing the last few lines), you may be happy with small buffer usage values. If you use LogExpert for heavy 'offline' analysis of large log files, you should try to increase buffer values (if you have enough RAM). The increased filtering speed is worth the RAM consumption. Trust me, your live will be easier a lot! ;)
Multi threaded filter
If enabled, the filter function will use multiple threads. This can improve the speed of the filter. The real speed gain depends on the actual system (number of processors etc.). On my dual core notebook it's about twice as fast if the file is completely held in memory. When the file doesn't fit completely in memory (buffer settings), then multi threading can be even faster than twice. Because if some threads are waiting for disk, the other ones can continue with filter searching in already loaded buffers.
Currently, the number of threads started for filtering is processor count + 2. Every thread will get a part of the logfile. When all threads have completed, the results are merged. Because every thread works on a different part of the logfile, the block size settings may affect the speed, if buffer purges/reloads occure while filtering.
File polling interval
You can adjust the polling interval. This is the interval a log file is checked for changes. In most situations you should have no reason to change the value.
The smallest allowed value is 20ms.