Advisories
Performance Advisories provide explicit and clear description of performance degradations affecting the database instance. Developed by Oracle performance tuning experts, these advisories:
Detect and diagnose performance degradations and provide paths to their resolution
Incorporate wait event analysis to focus only on significant issues affecting database performance
Use fuzzy evaluation techniques to combine relevant metrics and convey appropriate priority of each issue relative to the database workload in a given period and to other problems evident within the same period
Provide clear and detailed explanation of performance degradations offering just-in-time education, extensive background tuning information, and knowledge to assist DBAs with solving the problem at hand and avoid similar problems in the future
Advisories are presented in either a default ordered and categorized tuning plan or as an action plan that lists first the issues impacting database performance the most.
General
The advisories status denotes the advisories condition, as follows:
OK
Init(ializing)
Idle
Working
Stopped
In Progress
Error
If the advisories are configured for this instance, use Pause/Resume to Stop/Start the Performance Advisory feature
In the 15 Minutes Collection choose between the 15 minute and 1 hour collection frequencies based on tradeoff between timeliness requirements and space considerations
Instance Profile
The database instance profile settings define critical system hardware and software components, as follows:
Available RAM in MB
Specify the amount of physical memory (RAM) available for use by this database on the host computer. Only specify the amount of memory designated for use by this database taking into consideration memory used by the operating system and other application software hosted on this computer. Include memory available for both Oracle's SGA and user/background processes
To view available memory on a Windows NT/2000/XP computer:
Press Ctrl-Alt-Delete. The Windows Security window is displayed. Click Task Manager.
Select the Performance tab. Physical memory is listed in the Physical Memory group. Memory is displayed in kilobytes. Kilobytes can be converted to megabytes by dividing by 1024.
To view available memory on a UNIX computer, consult the operating system documentation for instructions or the system administrator.
Transaction Type
Database transaction type can be generally separated into the following types:
On-line Transaction Processing (OLTP) —These applications involve many users who are updating, inserting, and running numerous quick select statements. These statements access data through an index and return single row results or small result sets. The SQL statement response time is often sub-second. Examples of these kinds of applications are rental car reservation systems, order entry applications, airline reservation systems, and banking applications.
Decision Support System (DSS) — Decision support systems typically run adhoc or report generation SQL to mine data for trends, produce summary data, and perform general analysis of data. These types of queries can often take seconds or minutes to run. DSS queries don't always use indexes. When a full data set must be scanned to perform calculations, full table scans occur. Examples of DSS systems are those that look for market trends or monthly/quarterly/annual reporting applications.
Mixed or Hybrid — Mixed or hybrid systems are used both for on-line transaction processing and decision support. Tuning performance of these systems is more difficult because the two usage types often benefit from opposite tuning approaches. For example, to improve screen refresh response time, OLTP applications benefit from tuning actions that quickly return a query's first rows at the expense of response time for the total result set. On the other hand, DSS applications, in trying to maximize throughput, benefit from tuning actions that minimize time to return the entire result set at the expense of response time to return the query's first few rows.
Datafile disk devices
To find the number of disks in Windows:
Open the Control Panel.
Double-click Administrative Tools, then double-click Computer Management.
Expand the Storage node and select Disk Management.
The disk device information for the machine is displayed.
To find the number of disks in UNIX:
On UNIX, the underlying disk devices can be seen by using the following commands:
mount
df
iostat
These commands only give partial information about the disk devices available on the system. For example, the command mount does not list disks that are used as raw devices.
The more physical disks that are available to store datafiles, the more efficiently datafile access can be configured to avoid contention and I/O bottlenecks.
Understanding I/O problems
The performance of many software applications is inherently limited by disk input/output (I/O). Often, CPU activity must be suspended while I/O activity completes. Such an application is said to be I/O bound. Placing datafiles on multiple disk devices decreases the chance for I/O contention.
What is disk contention?
Disk contention occurs when multiple processes try to access the same disk simultaneously. Disks have limits on both the number of accesses and the amount of data they can transfer per second. When these limits are exceeded, processes will wait to access the disk.
Datafile RAID status
Is RAID striping in use?
RAID (Redundant Array of Independent Disks) arrays are a popular way of providing fault tolerant, high performance disk configurations. There are a number of RAID levels available.
This question seeks to establish whether a RAID configuration is in use, and if so, does the RAID level implement striping. Striping is a proven method for increasing I/O performance.
There are three common levels of RAID provided by storage vendors. Other levels typically implement differing configurations of mirroring, striping, and parity.
RAID 0
RAID 0 implements disk striping. In striped configurations, a logical disk is constructed from multiple physical disks. The data contained on the logical disk is spread evenly across the physical disks and hence random I/Os are also likely to be spread evenly. There is no redundancy built into this configuration. When a disk fails it need to be recovered from a backup.
RAID 1
RAID 1 implements disk mirroring. In mirrored configurations, a logical disk is comprised of at least two physical disks, each holding the exact same data as the others. In the event that one physical disk fails, processing can continue using the other physical disk. Writes are processed in parallel so there should be no degradation of write performance. Multiple disks are available for reads so there can be an improvement in read performance.
RAID 5
In RAID 5, a logical disk is comprised of multiple physical disks. Data is arranged across the physical devices in a similar way to disk striping (RAID 0). However, a certain proportion of the data on the physical devices is parity data. This parity data contains enough information to derive data on other disks should a single physical device fail.
RAID 0+1
It's common to combine RAID 0 and RAID 1. Such striped and mirrored configurations offer protection against hardware failure together with the spread of I/O load.
RAID levels 2, 3, 4, 6, 7, 10, and 53 are other RAID configurations that implement some form of striping.
Performance implications of RAID
Both RAID 0 and RAID 5 improve the performance of concurrent random reads by spreading the load across multiple devices. However, RAID 5 tends to degrade write I/O since both the source block and the parity block must be read and then updated.
Dedicated redo devices
Are the redo log files located on a disk device dedicated only to the redo log files?
To view the redo log file locations on disk, run the following sql query as system, sys or a sysdba:
SQL>select * from v$logfile
GROUP# STATUS MEMBER
------\ \ \ \ ------\ \ \ \ ------------------------------------
1 D:\ORACLE\ORADATA\XXXX\REDO04.LOG
2 D:\ORACLE\ORADATA\XXXX\REDO03.LOG
3 D:\ORACLE\ORADATA\XXXX\REDO02.LOG
The log writer (LGWR) process writes sequentially to the redo log files. LGWR writes all change vectors to the redo log files. A change vector is a physical representation of the data changed in an Oracle data block. The actual data blocks changed by an update, insert, or delete are written out to disk sometime before or immediately after the user runs a commit command. When a user commits, the redo logs on the disk must contain a representation of all the changes they made in the database. This guarantees that the database can be recovered when there is a database crash. A crash can cause loss of data stored in memory, such as changed data blocks that have not yet been written to disk. After every commit, the user waits for LGWR to respond with a confirmation that the change vectors were written to the log files. The speed at which the LGWR can write to the redo log files has a direct impact on user response time when data changes are made.
LGWR writes most efficiently to the redo log files when LGWR is the only process writing to the disk. Contention occurs when the disk is used for other file I/O while the LGWR is writing to the redo logs. Contention causes slower redo log writes and thus causes slower response time in completing a user commit.
The fastest redo log file write times are achieved on raw devices.
Alternated redo devices
For databases running in archive log mode.
Are the redo log files in the database set up on different disks?
The archiver process (ARCH) should be reading from a different disk than that which is written to by the log writer process (LGWR).
The redo log files can be queried from the view v$logfile as in:
SQL>select * from v$logfile
GROUP# STATUS MEMBER
--------- ------- ----------------------------------
1 D:\ORACLE\ORADATA\XXXX\REDO04.LOG
2 D:\ORACLE\ORADATA\XXXX\REDO03.LOG
3 D:\ORACLE\ORADATA\XXXX\REDO02.LOG
From this view you can see whether the log files are on different partitions. Different partitions could be on the same disk or disk device. To determine whether different partitions are on the same device, you will need more information about the underlying disk device system.
The archive log file location can be determined by using the following command:
SQL>archive log list
Database log mode Archivelog
Automatic archival Enabled
Archive destination D:\ORACLE\arch
Oldest online log sequence 188082
Current log sequence 188084
The information above shows that all of the redo logs and the archive log are on the same device. This configuration could cause contention.
What are "alternated redo devices"?
An Oracle database has a minimum of 2 redo log files. It is recommended that these two files be on separate disks. When there are more than two redo log files, the 3rd redo log file can be put on the same disk as the first log file and the 4th log file on the same disk as the 2nd log file. This is called alternating redo log files .
The only process writing to a redo log file is the log writer process, known as LGWR. LGWR only writes to one of the redo log files at a time. Thus LGWR writes efficiently to the redo log files whether they are on one disk or separate disks*. LGWR writes to the available redo log file using the round robin method. LGWR writes to one redo log file until filled and then switches to the next redo log file, eventually coming back to the first redo log file.
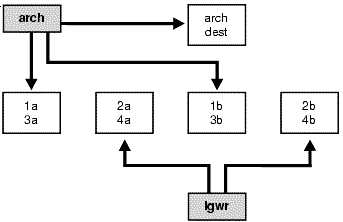
Contention can occur in the redo log archive process (ARCH) if the archiver process reads from a log file located on the same disk as one currently being written by the log writer process. ARCH reads the redo log files after LGWR has filled them. After filling a redo log file, the LGWR switches to the next redo log file. When this next redo log file is on a separate disk from the last redo log file, no contention occurs (as long as the archiver finishes reading the log file before the log writter switches back to a log file residing on the same disk).
Higher archiver throughput can be achieved by implementing larger numbers of dedicated redo devices and alternating the redo logs in round robin fashion. The greater the number of redo log devices, the higher possible throughput from multiple archiver processes. In general, a two disk configuration for alternating log files should be sufficient.
*In some less common cases, using multiple disks for a redo log file by using striping can be beneficial.
Dedicated archive devices
To determine the devices to which the archive process is writing, run the command archive log list in sqlplus (or svrmgr) as internal or sysdba.
Example:
sql>connect internal
connected.
sql>archive log list
Database log mode Archivelog
Automatic archival Enabled
Archive destination D:\Oracle\Ora81\RDBMS
Oldest online log sequence 3
Current log sequence 6
Compare 'Archive destination' with the other files in the database. The other files can be found with the following sql commands:
select name from v$datafile;
select name from v$tempfile;
select member from v$logfile;
select value from v$parameter where name='control_files';
Do any other database files use the same disk device? Do any other applications other than the database use the same disk device?
The archiver process (ARCH) backs up redo log files after they have been filled by the log writer process (LGWR). When ARCH is unable to keep up with the amount of redo generated by LGWR, contention can occur when LGWR starts writing to a new redo log located on a disk currently being read by the archiver process. To quickly complete the archive process and avoid contention, the archiver process should write archived redo log files to a disk that is only used for this purpose.
Advisories
Disable collection of advisories whose monitoring value is insignificant.
Best Practices
Disable/Enable the Best Practice feature.
Schedule the days on which collection of best practices data is to occur.
E-Business
Disable/Enable the E-Business feature.
Schedule the days on which collection of e-business data is to occur.