The BLACKHOLE storage engine acts as a
“black hole” that accepts data but throws it away and
does not store it. Retrievals always return an empty result:
mysql>CREATE TABLE test(i INT, c CHAR(10)) ENGINE = BLACKHOLE;Query OK, 0 rows affected (0.03 sec) mysql>INSERT INTO test VALUES(1,'record one'),(2,'record two');Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql>SELECT * FROM test;Empty set (0.00 sec)
The BLACKHOLE storage engine is included in
MySQL-Max binary distributions. To enable this storage engine if
you build MySQL from source, invoke configure
with the --with-blackhole-storage-engine option.
To examine the source for the BLACKHOLE engine,
look in the sql directory of a MySQL source
distribution.
When you create a BLACKHOLE table, the server
creates a table format file in the database directory. The file
begins with the table name and has an .frm
extension. There are no other files associated with the table.
The BLACKHOLE storage engine supports all kinds
of indexes. That is, you can include index declarations in the
table definition.
You can check whether the BLACKHOLE storage
engine is available with this statement:
mysql> SHOW VARIABLES LIKE 'have_blackhole_engine';
Inserts into a BLACKHOLE table do not store any
data, but if the binary log is enabled, the SQL statements are
logged (and replicated to slave servers). This can be useful as a
repeater or filter mechanism. For example, suppose that your
application requires slave-side filtering rules, but transferring
all binary log data to the slave first results in too much
traffic. In such a case, it is possible to set up on the master
host a “dummy” slave process whose default storage
engine is BLACKHOLE, depicted as follows:
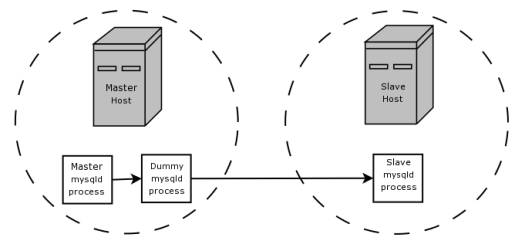
The master writes to its binary log. The “dummy”
mysqld process acts as a slave, applying the
desired combination of replicate-do-* and
replicate-ignore-* rules, and writes a new,
filtered binary log of its own. (See
Section 6.8, “Replication Startup Options”.) This filtered log is
provided to the slave.
The dummy process does not actually store any data, so there is little processing overhead incurred by running the additional mysqld process on the replication master host. This type of setup can be repeated with additional replication slaves.
Other possible uses for the BLACKHOLE storage
engine include:
-
Verification of dump file syntax.
-
Measurement of the overhead from binary logging, by comparing performance using
BLACKHOLEwith and without binary logging enabled. -
BLACKHOLEis essentially a “no-op” storage engine, so it could be used for finding performance bottlenecks not related to the storage engine itself.