Wireshark can read in an ASCII hex dump and write the data described into a temporary libpcap capture file. It can read hex dumps with multiple packets in them, and build a capture file of multiple packets. It is also capable of generating dummy Ethernet, IP and UDP, TCP, or SCTP headers, in order to build fully processable packet dumps from hexdumps of application-level data only.
Wireshark understands a hexdump of the form generated by od -Ax -tx1 -v. In other words, each byte is individually displayed and surrounded with a space. Each line begins with an offset describing the position in the file. The offset is a hex number (can also be octal or decimal), of more than two hex digits. Here is a sample dump that can be imported:
000000 00 e0 1e a7 05 6f 00 10 ........
000008 5a a0 b9 12 08 00 46 00 ........
000010 03 68 00 00 00 00 0a 2e ........
000018 ee 33 0f 19 08 7f 0f 19 ........
000020 03 80 94 04 00 00 10 01 ........
000028 16 a2 0a 00 03 50 00 0c ........
000030 01 01 0f 19 03 80 11 01 ........
There is no limit on the width or number of bytes per line. Also the text dump at the end of the line is ignored. Bytes/hex numbers can be uppercase or lowercase. Any text before the offset is ignored, including email forwarding characters '>'. Any lines of text between the bytestring lines is ignored. The offsets are used to track the bytes, so offsets must be correct. Any line which has only bytes without a leading offset is ignored. An offset is recognized as being a hex number longer than two characters. Any text after the bytes is ignored (e.g. the character dump). Any hex numbers in this text are also ignored. An offset of zero is indicative of starting a new packet, so a single text file with a series of hexdumps can be converted into a packet capture with multiple packets. Packets may be preceded by a timestamp. These are interpreted according to the format given. If not the first packet is timestamped with the current time the import takes place. Multiple packets are read in with timestamps differing by one microsecond each. In general, short of these restrictions, Wireshark is pretty liberal about reading in hexdumps and has been tested with a variety of mangled outputs (including being forwarded through email multiple times, with limited line wrap etc.)
There are a couple of other special features to note. Any line where the first non-whitespace character is '#' will be ignored as a comment. Any line beginning with #TEXT2PCAP is a directive and options can be inserted after this command to be processed by Wireshark. Currently there are no directives implemented; in the future, these may be used to give more fine grained control on the dump and the way it should be processed e.g. timestamps, encapsulation type etc. Wireshark also allows the user to read in dumps of application-level data, by inserting dummy L2, L3 and L4 headers before each packet. The user can elect to insert Ethernet headers, Ethernet and IP, or Ethernet, IP and UDP/TCP/SCTP headers before each packet. This allows Wireshark or any other full-packet decoder to handle these dumps.
This dialog box lets you select a text file, containing a hex dump of packet data, to be imported and set import parameters.
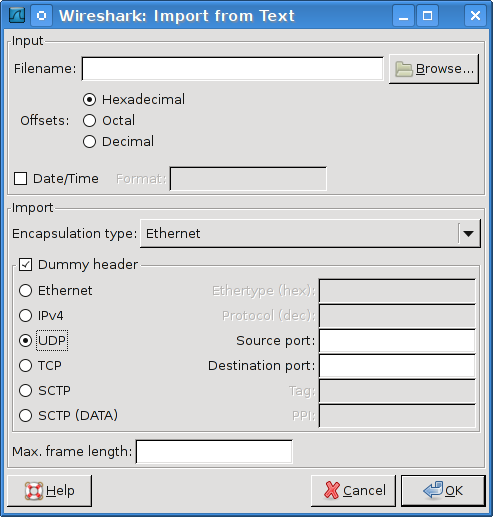
Specific controls of this import dialog are split in two sections:
- Input
-
Determine which input file has to be imported and how it is to be interpreted.
- Import
-
Determine how the data is to be imported.
The input parameters are as follows:
- Filename / Browse
-
Enter the name of the text file to import. You can use Browse to browse for a file.
- Offsets
-
Select the radix of the offsets given in the text file to import. This is usually hexadecimal, but decimal and octal are also supported.
- Date/Time
-
Tick this checkbox if there are timestamps associated with the frames in the text file to import you would like to use. Otherwise the current time is used for timestamping the frames.
- Format
-
This is the format specifier used to parse the timestamps in the text file to import. It uses a simple syntax to describe the format of the timestamps, using %H for hours, %M for minutes, %S for seconds, etc. The straightforward HH:MM:SS format is covered by %T. For a full definition of the syntax look for strftime(3).
The import parameters are as follows:
- Encapsulation type
-
Here you can select which type of frames you are importing. This all depends on from what type of medium the dump to import was taken. It lists all types that Wireshark understands, so as to pass the capture file contents to the right dissector.
- Dummy header
-
When Ethernet encapsulation is selected you have to option to prepend dummy headers to the frames to import. These headers can provide artificial Ethernet, IP, UDP or TCP or SCTP headers and SCTP data chunks. When selecting a type of dummy header the applicable entries are enabled, others are grayed out and default values are used.
- Max. frame length
-
You may not be interested in the full frames from the text file, just the first part. Here you can define how much data from the start of the frame you want to import. If you leave this open the maximum is set to 64000 bytes.
Once all input and import parameters are setup click OK to start the import.
![[Note]](note.png)
|
You will be prompted for an unsaved file first! |
|---|---|
|
If your current data wasn't saved before, you will be asked to save it first, before this dialog box is shown. |
When completed there will be a new capture file loaded with the frames imported from the text file.