Esta sección es un “Cómo” (“How-To”) en el que describimos las bases para planear, instalar, configurar, y ejecutar un MySQL Cluster. A diferencia del ejemplo de Sección 16.4, “Configuración de MySQL Cluster”, el resultado de las guías y procedimientos descritos a continuación deben ser utilizables para MySQL Cluster con unos requerimientos mínimos para disponibilidad y salvaguardia de los datos.
En esta sección, cubrimos requerimientos de hardware y software; red; instalación de MySQL Cluster; configuración; arrancar, parar y reiniciar el cluster; cargar una base de datos de ejemplo; y realizar consultas.
Suposiciones básicas
Este How-To hace las siguientes suposiciones:
-
Estamos preparando un cluster con 4 nodos, cada uno en máquinas separadas, y cada uno con dirección de red fija en una Ethernet como se muestra:
Nodo Dirección IP Nodo de administración (MGM) 192.168.0.10 Nodo MySQL server (SQL) 192.168.0.20 Nodo de datos (NDBD) "A" 192.168.0.30 Nodo de datos (NDBD) "B" 192.168.0.40 Puede verse mejor en el siguiente diagrama:
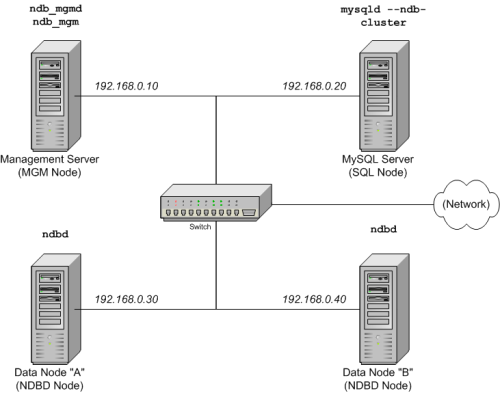
Nota: Para mayor simplicidad, usamos sólo direcciones IP numéricas en este How-To. Sin embargo, si la resolución de DNS está disponible en su red, es posible usar nombres de equipos en lugar de direcciones IP al configurar el cluster. Alternativamente, puede usar el fichero
/etc/hostso el equivalente en su sistema operativo para proporcionar significado al hacer la búsqueda de equipos si está disponible. -
Cada equipo en nuestro escenario es un PC de sobremesa basado en Intel con una distribución Linux genérica instalada en disco con una configuración estándar, y ejecutando sólo los servicios necesarios. El sistema operativo con un cliente de red TCP/IP estándar es suficiente. Para simplicidad, asumimos que el sistema de ficheros en todas las máquinas está configurado igual. En caso que no fuera así, necesita adaptar estas instrucciones.
-
Tarjetas 100 Mbps o 1 gigabit Ethernet están instaladas en cada máquina, junto con sus drivers, y las cuatro máquinas están conectadas via un elemento de red Ethernet como un switch. (Todas las máquinas deben usar tarjetas de red con la misma velocidad; esto es, las cuatro máquinas del cluster deben tener tarjetas 100 Mbps o las 4 máquinas deben tener tarjetas 1 Gbps.) MySQL Cluster funcionará en una red 100 Mbps ; sin embargo, gigabit Ethernet proporciona mejor rendimiento.
Tenga en cuenta que MySQL Cluster no está diseñado para una conectividad de red menor a 100 Mbps. Por esta razón (entre otras), intentar ejecutar un MySQL Cluster en una red pública como Internet no funcionará y no está recomendado.
-
Para nuestros datos de prueba, usaremos la base de datos
worlddisponible para descarga en la web de MySQL AB. Como ocupa poco espacio, suponemos que cada máquina tiene 256 MB RAM, que debe ser suficiente para ejecutar el sistema operativo, proceso NDB del equipo y (para los nodos de datos) almacenar la base de datos.
Aunque nos referimos a Linux en este How-To, las instrucciones y procedimientos que proporcionamos aquí pueden adaptarse tanto a Solaris como a Mac OS X. Suponemos que sabe realizar una instalación mínima y configurar el sistema operativo con capacidad de red, o que puede obtener asistencia cuando lo necesite.
Discutimos los requerimientos hardware ,software, y de red de MySQL Cluster con más detalle en la siguiente sección . (Consulte Sección 16.3.1, “Hardware, software y redes”.)
Una de las ventajas de MySQL Cluster es que puede ejecutarse en hardware normal sin ningún requerimiento especial a parte de grandes cantidades de RAM, debido al hecho que todos los datos se almacenan en memoria. (Tenga en cuenta que esto puede cambiar y que queremos implementar almacenamiento en disco en versiones futuras.) Naturalmente, CPUs múltiples y más rápidas mejoran el rendimiento. Los requerimientos de memoria para procesos cluster son relativamente pequeños.
Los requerimientos de software para Cluster son modestos. Los
sistemas operativos de las máquinas no requieren ningún modulo
no usual, servicios, aplicaciones o configuración extraña para
soportar MySQL Cluster. Para Mac OS X o Solaris, la instalación
estándar es suficiente. Para Linux, una instalación estándar
debe ser todo lo necesario. Los requerimientos del software
MySQL son simples: todo lo necesario es una versión de
producción de MySQL-max 5.0; debe usar la versión
-max de MySQL 5.0 para tener soporte de
cluster. No es necesario compilar MySQL para usar cluster. En
este How-To, asumimos que está usando el
-max binario apropiado para Linux. Solaris, o
Mac OS X disponible en la página de descargas de MySQL
http://dev.mysql.com/downloads.
Para comunicación entre nodos, el cluster soporta red TCP/IP en cualquier topología estándar, y como mínimo se espera una red 100 Mbps Ethernet , más un switch, hub, o router para proporcionar conectividad de red al cluster entero. Recomendamos que MySQL Cluster se ejecute en su subred que no está compartida con máquinas no-cluster por las siguientes razones:
-
Seguridad: La comunicación entre nodos del cluster no están encriptadas. La única forma de proteger transmisiones dentro de un MySQL Cluster es ejecutar su cluster en una red protegida. Si trata de usar MySQL Cluster para aplicaciones Web , el cluster debe residir detrás de un firewall y no en su DMZ (DMZ) o en otro lugar.
-
Eficiencia: Inicializar un MySQL Cluster en una red privada o protegida permite que el cluster haga uso exclusivo del ancho de banda entre máquinas del cluster. Usar un switch esparado para su MySQL Cluster no sólo ayuda a protegerse de accesos no autorizados a los datos del clsuter, también asegura que los nodos del cluster están protegidos de interferencias causadas por transmisiones entre otras máquinas en la red. Para mayor confianza puede usar switches duales y tarjetas duales para eliminar la red como punto único de fallo; varios dispositivos soportan fallos para estos enlaces de comunicación.
Es posible usar la Scalable Coherent Interface (SCI) con MySQL Cluster, pero no es un requerimiento. Consulte Sección 16.7, “Usar interconexiones de alta velocidad con MySQL Cluster” para más información.
Cada máquina MySQL Cluster ejecutando nodos de almacenamiento o SQL deben tener insalados el binario MySQL-max . Para nodos de almacenamiento, no es necesario tener el binario MySQL server instalado, pero tiene que instalar el demonio del servidor MGM y los binarios de clientes (ndb_mgmd y ndb_mgm, respectivamente). En esta sección, cubrimos los pasos necesarios para instalar los binarios correctos para cada tipo de nodo del cluster.
MySQL AB proporciona binarios precompilados que soportan cluster
y que no tiene que compilar. (Si necesita un binario
personalizado, consulte
Sección 2.8.3, “Instalar desde el árbol de código fuente de desarrollo”.) Por lo tanto, el
primer paso del proceso de instalación para cada máquina del
cluster es bajar la versión más reciente de su plataforma
desde MySQL
downloads area. Asumimos que los guarda en el directorio
/var/tmp de cada máquina.
Hay RPMs disponibles para plataformas Linux 32-bit y 64-bit; los
binarios -max instalados por los RPMs
soportan el motor NDBCluster . Si elige
usarlos en lugar de los binarios, tenga en cuenta que debe
instalar ambos el paquete
-server y el -max en todas
las máquinas que tendrán nodos del cluster. (Consulte
Sección 2.4, “Instalar MySQL en Linux” para más información acerca de
instalar MySQL usando RPMs.) Tras instalar de los RPM, todavía
tiene que configurar el cluster como se discute en
Sección 16.3.3, “Configuración”.
Nota: Tras completar la instalación no arranque los binarios. Le mostraremos como hacerlo siguiendo la configuración de todos los nodos.
Instalación de nodos de almacenamiento y SQL
En cada una de las 3 máquinas designadas para tener los nodos de almacenamiento o SQL, realice los siguientes pasos como root del sistema:
-
Compruebe los ficheros
/etc/passwdy/etc/group( o use cualquier herramienta proporcionada por el sistema operativo para tratar usuarios y grupos) para ver si hay un grupomysqly usuariomysqlen el sistema, como algunas de las distribuciones de sistema operativo los crean como parte del proceso de instalación. Si no están presentes, cree un nuevo grupomysqly un usuariomysqlpara este grupo:groupadd mysql useradd -g mysql mysql
-
Cambie al directorio que contiene el fichero descargado; desempaquételo; cree un symlink al ejecutable mysql-max. Tenga en cuenta que el nombre del fichero y difectorio cambia en función del número de versión de MySQL .
cd /var/tmp tar -xzvf -C /usr/local/bin mysql-max-5.0.10-pc-linux-gnu-i686.tar.gz ln -s /usr/local/bin/mysql-max-5.0.10-pc-linux-gnu-i686 mysql
-
Cambie al directorio
mysql, y ejecute el script proporcionado para crear las bases de datos del sistema:cd mysql scripts/mysql_install_db --user=mysql
-
Configure los permisos necesarios para los directorios de MySQL server y de datos:
chown -R root . chown -R mysql data chgrp -R mysql .
Tenga en cuenta que el directorio de datos en cada máquina con un nodo de datos es
/usr/local/mysql/data. Haremos uso de esta información al configurar el nodo de administración . (Consulte Sección 16.3.3, “Configuración”.) -
Copie el script de arranque de MySQL en el directorio apropiado, hágalo ejecutable, y configúrelo para arrancar junto al sistema operativo:
cp support-files/mysql.server /etc/rc.d/init.d/ chmod +x /etc/rc.d/init.d/mysql.server chkconfig --add mysql.server
Aquí usamos Red Hat chkconfig para crear enlaces a los scripts de arranque; use lo que sea apropiado para su sistema operativo / distribución, tal como update-rc.d en Debian.
Recuerde que los pasos listados anteriormente deben realizarse separadamente en cada máquina en que el nodo de almacenamiento o SQL residen.
Instalación del nodo de administración
Para el nodo MGM (administración), no es necesario instalar el
ejecutable mysqld, sólo los binarios para el
cliente y servidor MGM, que pueden encontrarse en el archivo
-max descargado. De nuevo asumimos que ha
guardado este fichero en /var/tmp. Como
root del sistema (esto es, tras usar sudo,
su root, o su equivalente en su sistema para
asumir temporalmente los privilegios de administrador de
sistema), realice los siguientes pasos para instalar
ndb_mgmd y ndb_mgm en el
nodo de administración del cluster:
-
Mueva el directorio
/var/tmp, y extraiga ndb_mgm y ndb_mgmd del archivo a un directorio disponible como/usr/local/bin:cd /var/tmp tar -zxvf mysql-max-5.0.10-pc-linux-gnu-i686.tar.gz /usr/local/bin '*/bin/ndb_mgm*'
-
Vaya al directorio en que ha desempaquetado los ficheros, y hágalos ejecutables:
cd /usr/local/bin chmod +x ndb_mgm*
En Sección 16.3.3, “Configuración”, crearemos y escribiremos los ficheros de configuración para todos los nodos del cluster de ejemplo.
Para nuestro cluster de 4 nodos y 4 equipos, necesitamos escribir 4 ficheros de configuración, 1 por nodo/equipo.
-
Cada nodo de datos o SQL necesita un fichero
my.cnfque proporciona dos informaciones: un connectstring diciendo al nodo dónde encontrar el nodo MGM , y una línea diciendo al servidor MySQL en este equipo (la máquina del nodo de datos) que se ejecute en modo NDB.Para más información de connectstrings, consulte Sección 16.4.4.2, “El
connectstringde MySQL Cluster”. -
El nodo de administración necesita un fichero
config.inique le diga cuántas replicas mantener, cuánta memoria reservar para datos e índices en cada nodo de datos, dónde encontrar los nodos de datos, dónde se guardarán los datos en cada nodo de datos, y dónde encontrar los nodos SQL.
Configuración de los nodos de almacenamiento y SQL
El fichero my.cnf necesitado por los nodos
de datos es muy simple. El fichero de configuración debe estar
localizado en el directorio /etc y puede
editarse (y crearse en caso necesario) usando un editor de
texto, por ejemplo:
vi /etc/my.cnf
Para cada nodo de datos y SQL en nuestra configuración de
ejemplo, my.cnf debe tener este aspecto:
[MYSQLD] # Options for mysqld process: ndbcluster # run NDB engine ndb-connectstring=192.168.0.10 # location of MGM node [MYSQL_CLUSTER] # Options for ndbd process: ndb-connectstring=192.168.0.10 # location of MGM node
Tras introducir lo anterior, guarde este fichero y salga del editor de texto. Hágalo pra las máquinas que guarden el nodo de datos "A", el "B" y el nodo SQL.
Configuración del nodo de administración
El primer paso al configurar el nodo MGM es crear el directorio en que puede encontrarse el fichero de configuración y crear el fichero própiamente dicho. Por ejemplo (ejecutando como root):
mkdir /var/lib/mysql-cluster cd /var/lib/mysql-cluster vi config.ini
Mostramos vi para crear el fichero, pero puede usar cualquier editor de textos.
Para nuestra inicialización representativa, el fichero
config.ini debe leerse así:
[NDBD DEFAULT] # Options affecting ndbd processes on all data nodes:
NoOfReplicas=2 # Number of replicas
DataMemory=80M # How much memory to allocate for data storage
IndexMemory=18M # How much memory to allocate for index storage
# For DataMemory and IndexMemory, we have used the
# default values. Since the "world" database takes up
# only about 500KB, this should be more than enough for
# this example Cluster setup.
[TCP DEFAULT] # TCP/IP options:
portnumber=2202 # This the default; however, you can use any
# port that is free for all the hosts in cluster
# Note: It is recommended beginning with MySQL 5.0 that
# you do not specify the portnumber at all and simply allow
# the default value to be used instead
[NDB_MGMD] # Management process options:
hostname=192.168.0.10 # Hostname or IP address of MGM node
datadir=/var/lib/mysql-cluster # Directory for MGM node logfiles
[NDBD] # Options for data node "A":
# (one [NDBD] section per data node)
hostname=192.168.0.30 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's datafiles
[NDBD] # Options for data node "B":
hostname=192.168.0.40 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's datafiles
[MYSQLD] # SQL node options:
hostname=192.168.0.20 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for SQL node's datafiles
# (additional mysqld connections can be
# specified for this node for various
# purposes such as running ndb_restore)
(NOTA: La base de datos "world" puede descargarse desde http://dev.mysql.com/doc/ donde puede encontrarse en "Examples".)
Una vez que todos los ficheros de configuración se han creado y se han especificado estas opciones, está preparado para arrancar el cluster y verificar que todos los procesos están en ejecución. Se discute acreca de esto en Sección 16.3.4, “Arranque inicial”.
Para información más detallada acerca de los parámetros de configuración de MySQL Cluster y sus usos, consulte Sección 16.4.4, “Fichero de configuración” y Sección 16.4, “Configuración de MySQL Cluster”. Para configuración de MySQL Cluster para realizar copias de seguridad, consulte Sección 16.6.4.4, “Configuración para copias de seguridad de un nodo”.
Nota: El puerto por defecto para administración del cluster es 1186; el puerto por defecto para nodos de datos es 2202. A partir de MySQL 5.0.3, esta restricción se elimina, y el cluster reserva los puertos de los nodos de datos automáticamente de los que están libres.
Arrancar el cluster no es complicado una vez configurado. Cada proceso de los nodos del cluster debe arrancarse separadamente, y en la máquina en que reside. Mientras es posible arrancar los nodos en cualquier orden, seguidos por los nodos de almacenamiento y finalmente por los nodos SQL:
-
En la máquina de administración, realice el siguiente comando del shell del sistema para arrancar los procesos del nodo MGM:
shell> ndb_mgmd -f /var/lib/mysql-cluster/config.ini
Tenga en cuenta que ndb_mgmd debe saber dónde encontrar su fichero de configuración , usando la opción
-fo--config-file. (Consulte Sección 16.5.3, “El proceso del servidor de administración ndb_mgmd” para más detalles.) -
En cada equipo de los nodos de datos, ejecute este comando para arrancar el proceso NDBD por primera vez:
shell> ndbd --initial
Tenga en cuenta que es muy imporante usar el parámetro
--initialsólo al arrancar ndbd por primera vez, o tras reiniciar tras una copia de seguridad/restauración o cambio de configuración. Esto es debido a que este parámetro hará que el nodo borre cualquier fichero creado por instancias ndbd anteriormente necesarios para la restauración, incluyendo el fichero log de restauración. -
En la máquina cluster donde reside el nodo SQL, ejecute un mysqld normal como se muestra:
shell> mysqld &
Si todo ha ido bien, y el cluster se ha inicializado correctamente, el cluster debería ser operacional. Puede comprobarlo invocando el nodo cliente de administración ndb_mgm ; la salida debe parecerse a la que hay a continuación:
shell> ndb_mgm -- NDB Cluster -- Management Client -- ndb_mgm> show Connected to Management Server at: localhost:1186 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 @192.168.0.30 (Version: 5.0.11, Nodegroup: 0, Master) id=3 @192.168.0.40 (Version: 5.0.11, Nodegroup: 0) [ndb_mgmd(MGM)] 1 node(s) id=1 @192.168.0.10 (Version: 5.0.11) [mysqld(SQL)] 1 node(s) id=4 (Version: 5.0.11)
Puede encontrar ligeras diferencias en función de la versión exacta de MySQL que use.
Nota: Si usa una versión
antigua de MySQL, puede ver el nodo SQL referenciado como
'[mysqld(API)]'. Esto refleja un uso antiguo
que ya está obsoleto.
Debería ser capaz de trabajar con bases de datos, tablas y datos en MySQL Cluster. Consulte Sección 16.3.5, “Cargar datos de ejemplo y realizar consultas” para una breve discusión.
Trabajar don datos en MySQL Cluster no es muy distinto que trabajar con MySQL sin Cluster. Hay que tener en cuenta dos puntos al hacerlo:
-
Las tablas deben crearse con la opción
ENGINE=NDBoENGINE=NDBCLUSTER, o cambiarse (medianteALTER TABLE) para usar el motor NDB CLuster para que puedan replicarse en el cluster. Si está importando tablas de una base de datos existente usando la salida de mysqldump, puede abrir el script SQL en un editor de texto y añadir está opción a cualquier comando de creación de tablas, o reemplazar cualquier opciónENGINE(oTYPE) existente con alguna de estas. Por ejemplo, suponga que tiene la base de datos de ejemploworlden otro MySQL server (que no soporta MySQL Cluster), y desea exportar la definición de la tablaCity:shell> mysqldump --add-drop-table world City > city_table.sql
El fichero
city_table.sqlresultante contendrá el comando de creación de la tabla ( y el comandoINSERTnecesario para importar los datos de la tabla):DROP TABLE IF EXISTS City; CREATE TABLE City ( ID int(11) NOT NULL auto_increment, Name char(35) NOT NULL default '', CountryCode char(3) NOT NULL default '', District char(20) NOT NULL default '', Population int(11) NOT NULL default '0', PRIMARY KEY (ID) ) TYPE=MyISAM; INSERT INTO City VALUES (1,'Kabul','AFG','Kabol',1780000); INSERT INTO City VALUES (2,'Qandahar','AFG','Qandahar',237500); INSERT INTO City VALUES (3,'Herat','AFG','Herat',186800); # (remaining INSERT statements omitted)
Necesitará asegurarse que MySQL usa el motor NDB para esta tabla. Hay dos formas de hacerlo. Una es, antes de importar la tabla en la base de datos del cluster, modificar su definición para que lea (usando
Citycomo ejemplo):DROP TABLE IF EXISTS City; CREATE TABLE City ( ID int(11) NOT NULL auto_increment, Name char(35) NOT NULL default '', CountryCode char(3) NOT NULL default '', District char(20) NOT NULL default '', Population int(11) NOT NULL default '0', PRIMARY KEY (ID) ) ENGINE=NDBCLUSTER; INSERT INTO City VALUES (1,'Kabul','AFG','Kabol',1780000); INSERT INTO City VALUES (2,'Qandahar','AFG','Qandahar',237500); INSERT INTO City VALUES (3,'Herat','AFG','Herat',186800); # (etc.)
Esto debe hacerse para la definición de cada tabla que será parte de la base de datos clusterizada. La forma más fácil de hacerlo es símplemente hacer un buscar y reemplazar en el fichero
world.sqly reemplazar todas las instancias deTYPE=MyISAMconENGINE=NDBCLUSTER. Si no quiere modificar el fichero, puede usarALTER TABLE; consulte a continuación las particularidades.Asumiendo que ha creado la base de datos llamada
worlden el nodo SQL del cluster, puede usar el cliente de línea de comandos mysql para leercity_table.sql, y crear y llenar de datos la tabla correspondiente de la forma usual:shell> mysql world < city_table.sql
Es muy importante recordar que el comando anterior debe ejecutarse en la máquina en que corre el nodo SQL -- en este caso, la máquina con dirección IP 192.168.0.20.
Para crear una copia de la base de datos
worlden el nodo SQL, guarde el fichero en/usr/local/mysql/data, luego ejecuteshell> cd /usr/local/mysql/data shell> mysql world < world.sql
Por supuesto, el script SQL debe ser leíble por el usuario
mysql. Si guarda el fichero en un lugar distinto, ajuste lo anterior correctamente.Es importante tener en cuenta que NDB Cluster en MySQL 5.0 no soporta descubrimiento automático de bases de datos. (Consulte Sección 16.8, “Limitaciones conocidas de MySQL Cluster”.) Esto significa que , una vez que la base de datos
worldy sus tablas se han creado en un nodo de datos, necesitará ejecutar el comando CREATE DATABASE world; (a partir de MySQL 5.0.2, puede usar CREATE SCHEMA world; en su lugar), seguido por FLUSH TABLES; en cada nodo de datos del cluster. Esto hará que el nodo reconozca la base de datos y lea sus definiciones de tablas.Ejecutar consultas SELECT en el nodo SQL no es distinto a ejecutarlas en cualquier otra instancia de un MySQL server. Para ejecutar consultas de línea de comandos, primero necesita loguearse en el MySQL Monitor normalmente:
shell> mysql -u root -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 to server version: 4.1.9-max Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql>
Si no modifica las cláusulas
ENGINE=en las definiciones de tabla antes de importar el script SQL, debe ejecutar los siguientes comandos en este punto:mysql> USE world; mysql> ALTER TABLE City ENGINE=NDBCLUSTER; mysql> ALTER TABLE Country ENGINE=NDBCLUSTER; mysql> ALTER TABLE CountryLanguage ENGINE=NDBCLUSTER;
Tenga en cuenta que símplemente usamos la cuenta
rootpor defecto del sistema con una contraseña vacía. Por supuesto, en un sistema de producción, debe siempre seguir las precauciones de seguridad para instalar un MySQL server, incluyendo una contraseña de root y la creación de una cuenta de usuario con sólo los permisos necesarios para realizar las tareas necesarias para ese usuario. Para más información acerca de esto, consulte Sección 5.6, “El sistema de privilegios de acceso de MySQL”.Vale la pena tener en cuenta que los nodos del cluster no utilizan el sistema de permisos de MySQL al acceder el uno al otro, y preparar o cambiar las cuentas de usuario de MySQL (incluyendo la cuenta
root) no tiene efecto en la interacción entre nodos, sólo en aplicaciones accediendo al nodo SQL.Seleccionar una base de datos y ejecutar una consulta SELECT contra una tabla en la base de datos se realiza de la forma normal, como salir del MySQL Monitor:
mysql> USE world; mysql> SELECT Name, Population FROM City ORDER BY Population DESC LIMIT 5; +-----------+------------+ | Name | Population | +-----------+------------+ | Bombay | 10500000 | | Seoul | 9981619 | | São Paulo | 9968485 | | Shanghai | 9696300 | | Jakarta | 9604900 | +-----------+------------+ 5 rows in set (0.34 sec) mysql> \q Bye shell>
Las aplicaciones usando MySQL pueden usar APIs estándar. Es importante recordar que sus aplicaciones deben acceder al nodo SQL, y no al nodo MGM o a los de almacenamiento. Este breve ejemplo muestra cómo puede ejecutar la misma consulta que la anterior usando la extensión de PHP 5
mysqliejecutando un servidor web en cualquier punto de la red:<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1"> <title>SIMPLE mysqli SELECT</title> </head> <body> <?php # connect to SQL node: $link = new mysqli('192.168.0.20', 'root', '', 'world'); # parameters for mysqli constructor are: # host, user, password, database if( mysqli_connect_errno() ) die("Connect failed: " . mysqli_connect_error()); $query = "SELECT Name, Population FROM City ORDER BY Population DESC LIMIT 5"; # if no errors... if( $result = $link->query($query) ) { ?> <table border="1" width="40%" cellpadding="4" cellspacing ="1"> <tbody> <tr> <th width="10%">City</th> <th>Population</th> </tr> <? # then display the results... while($row = $result->fetch_object()) printf(<tr>\n <td align=\"center\">%s</td><td>%d</td>\n</tr>\n", $row->Name, $row->Population); ?> </tbody </table> <? # ...and verify the number of rows that were retrieved printf("<p>Affected rows: %d</p>\n", $link->affected_rows); } else # otherwise, tell us what went wrong echo mysqli_error(); # free the result set and the mysqli connection object $result->close(); $link->close(); ?> </body> </html>Suponemos que el proceso ejecutándose en el servidor web puede alcanzar la IP del nodo SQL.
De forma parecida, puede usar la MySQL C API, Perl-DBI, Python-mysql, o los conectores propios de MySQL AB para realizar las tareas de definición y manipulación de datos como haría normalmente con MySQL.
-
Recuerde que cada tabla
NDBdebe tener una clave primaria. Si no se define clave primaria por el usuario cuando se crea la tabla, el motorNDB Clustercreará una oculta automáticamente. (Nota: esta clave oculta ocupa espacio como cualquier otro índice de tabla. No es raro encontrar problemas debido a espacio insuficiente en memoria para guardar estos índices creados automáticamente.)
Para parar el cluster símplemente introduzca lo siguiente en una shell en la máquina con el nodo MGM :
shell> ndb_mgm -e shutdown
Esto hará que ndb_mgm,
ndb_mgmd, y cualquier proceso
ndbd termine normalmente. Cualquier nodo SQL
puede terminarse usando mysqladmin shutdown y
otros medios. Tenga en cuenta que la opción
-e aquí se usa para pasar un comando al
cliente ndb_mgm desde el shell. Consulte
Sección 4.3.1, “Usar opciones en la raya de comando”.
Para reiniciar el cluster, símplemente ejecute estos comandos:
-
En el equipo de administración (
192.168.0.10en nuestra configuración):shell> ndb_mgmd -f /var/lib/mysql-cluster/config.ini
-
En cada uno de los nodos de datos (
192.168.0.30y192.168.0.40):shell> ndbd
Recuerde de no invocar este comando con la opción
--initialcuando reinicie el nodo NDBD normalmente. -
Y en el equipo SQL (
192.168.0.20):shell> mysqld &
Para inforamción de hacer copias de seguridad de clusters, consulte Sección 16.6.4.2, “Usar el servidor de administración para crear una copia de seguridad”.
Para restaurar un cluster de una copia de seguridad requiere el uso del comando ndb_restore . Esto se trata en Sección 16.6.4.3, “Cómo restablecer una copia de seguridad de un nodo”.
Más información sobre la configuración del cluster MySQL puede encontrarse en Sección 16.4, “Configuración de MySQL Cluster”.