XML Input Format Fields
The structure of the input records generated by the XML input format is determined at run time, depending on the document being parsed, and on the values specified for the input format parameters.
The XML input format parses an XML document by "visiting" the nodes in the document, and the input record fields are the attributes and values of the nodes that are visited by the XML input format.
By default, nodes are visited from the document root, that is, the single top-level
node in an XML document that contains all the other nodes in the document.
However, by supplying an XPath in either the from-entity
or as a value of the rootXPath parameter,
users can specify that the document nodes are to be visited starting from the node(s)
selected by the XPath.
Before parsing the XML document and return the input records, the XML input format
initially examines the nodes found along the paths from the root node or from the node(s)
selected by the user-supplied root XPath to the first n leaf nodes, where n
is the value of the dtNodes parameter.
During this phase, the XML input format creates a representation of the tree
structure ("schema" tree)
by merging nodes with the same name and hierarchical position. When completed, the
schema tree contains one single instance of each node type, and each node
contains an attribute set equal to the union of all the attributes found in the nodes
of that type.
At this moment, an input record field is created for each attribute belonging to a node
type and for each node type having a value.
Once the schema tree has been determined and the input record structure has been
created, the XML input format parses the XML document and generates input records,
visiting the document nodes and extracting their values and attributes.
The XML input format implements three different algorithms to decide
how document nodes will be visited.
The three algorithms represent three different ways in which the information contained
in an XML document can be retrieved, and the choice of an algorithm depends on the
structure of the document and on the structure of the information that needs to be
extracted.
Since different algorithms visit different sets of nodes, the choice of an algorithm
affects which fields (i.e. which node attributes and values) will be contained in the
input records.
Users can specify the algorithm to use through the
fMode ("field mode") parameter, which can
be set to "Branch", "Tree", or "Node".
Branch Field Mode
In this mode, input records contain the attributes and values of the nodes that are visited along all the possible paths from the document root or from the node(s) selected by the user-supplied root XPath to all the leaf nodes.
This mode is appropriate for documents in which each hierarchical level consists of
nodes of the same type, as depicted in the following diagram:
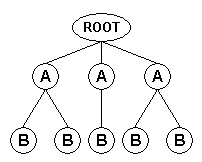
In this structure, the root node contains only nodes of type "A", and each
"A" node contains only nodes of type "B".
For example, the root of the following XML document contains "Continent"
nodes only; each "Continent" node contains "Country" nodes only,
and each "Country" node contains "City" nodes only:
<?xml version="1.0" ?>
<World>
<Continent ContinentName='North America'>
<Country CountryName='USA'>
<City> Redmond </City>
<City> San Francisco </City>
</Country>
<Country CountryName='Canada'>
<City> Vancouver </City>
<City> Toronto </City>
</Country>
</Continent>
<Continent ContinentName='Europe'>
<Country CountryName='Italia'>
<City Population='3350000'> Roma </City>
<City> Milano </City>
</Country>
</Continent>
</World>
This document can be thought of as containing six "entries", the leaf
"City" nodes, with the information associated with each entry being
contained in the nodes that are encountered along a path from the root node to the leaf
node.In this example, the information about "Roma" includes the attributes and value of the "City" node (the "Roma" node value and the "3350000" value of its "Population" attribute), the attributes and value of its parent "Country" node (the "Italia" value of the "CountryName" attribute), and the attributes and value of its grandparent "Continent" node (the "Europe" value of the "ContinentName" attribute).
The schema tree extracted from this example document specifies that
the document root node contains nodes of the "Continent" type, and that
nodes of this type have a "ContinentName" attribute. "Continent" nodes,
in turn, contain nodes of the "Country" type, with a "CountryName"
attribute; finally, "Country" nodes contain nodes of the "City"
type, and nodes of this type have a value, and a "Population" attribute.
The input records generated after the schema tree would thus contain four fields:
"ContinentName", "CountryName", "City",
and "Population".
When using the "Branch" field mode, the XML input format generates an input record for each path from the document root node or from the node(s) selected by the user-supplied root XPath to all the leaf nodes. Each input record contains the attributes and values of the nodes encountered along the path:
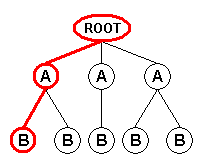 Record 1 |
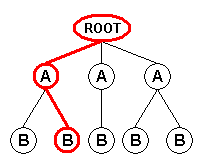 Record 2 |
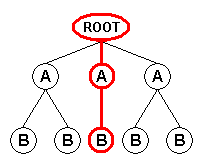 Record 3 |
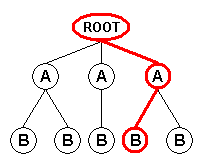 Record 4 |
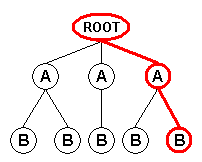 Record 5 |
If a node does not specify an attribute that is contained in the attribute superset of the corresponding schema tree node, or if a node does not supply a value while the corresponding schema tree node specifies that at least one node of that type has a value, then the corresponding field value is set to NULL.
For example, parsing the above example XML document in "Branch" field mode would produce the following output:
ContinentName CountryName City Population ------------- ----------- ------------- ---------- North America USA Redmond - North America USA San Francisco - North America Canada Vancouver - North America Canada Toronto - Europe Italia Roma 3350000 Europe Italia Milano -
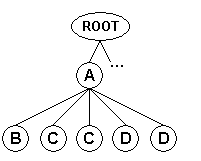
Tree Field Mode
In this mode, input records contain the attributes and values of the nodes found in subtrees that include all nodes of distinct types.
This mode is appropriate for documents in which a specific hierarchical level contains
child nodes all having different types, as depicted in the following diagram:
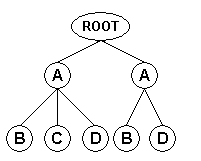
In this structure, the root node contains only nodes of type "A"; each
"A" node however contains nodes all having different types
(a single "B" node, a single "C" node, and a single "D"
node).
For example, the root of the following XML document contains "Message"
nodes; each "Message" node contains a single "From" node, a single
"To" node, and a single "Body" node:
<?xml version="1.0" ?>
<Messages>
<Message Date='2004-05-28T12:24:05'>
<From> Gabriele </From>
<To> Monica </To>
<Body> How's going? </Body>
</Message>
<Message Date='2004-05-28T13:01:14'>
<From> Monica </From>
<To> Gabriele </To>
<Body> Fine, thanks. </Body>
</Message>
</Messages>
This document can be thought of as containing two "entries",
the "Message" subtrees, with the information associated with each entry being
contained in all the nodes in the subtree and in the nodes that are encountered along a
path from the root node to the subtree root.In this example, the information about a message includes the attributes and values of all the nodes included in the subtree ("From", "To", and "Body" nodes), and the attributes and values of all the nodes encountered along the path from the document root to the subtree root ("Date" attribute of the "Message" node).
The schema tree extracted from this example document specifies that
the document root node contains nodes of the "Message" type, and that
nodes of this type have a "Date" attribute. "Message" nodes,
in turn, contain nodes of the "From", "To", and "Body"
types, each type having a node value.
The input records generated after the schema tree would thus contain four fields:
"Date", "From", "To", and "Body".
When using the "Tree" field mode, the XML input format generates an input record for each subtree that includes all nodes of distinct types. Each input record contains the attributes and values of the nodes found in the subtrees, together with the attributes and values of the nodes encountered along the paths from the document root node or from the node(s) selected by the user-supplied root XPath to the subtree root nodes:
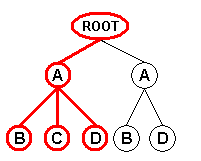 Record 1 |
 Record 2 |
For example, parsing the above example XML document in "Tree" field mode would produce the following output:
Date From To Body ------------------- -------- -------- ------------- 2004-05-28 12:24:05 Gabriele Monica How's going? 2004-05-28 13:01:14 Monica Gabriele Fine, thanks.
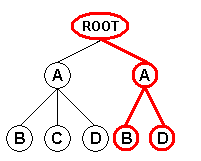
While parsing an XML document in "Tree" mode, if a subtree is found containing
multiple instances of the same node type, that subtree is "replicated"
combinatorially to generate all the possible subtrees containing one single instance
of each node type.
The following diagram depicts an XML document in which a subtree contains multiple
instances of the same node type:
In this diagram, the "A" node contains one instance of the "B"
node type, two instances of the "C" node type, and two instances of the
"D" note type.
For example, the "Message" node in the following XML document contains a
single "From" node, two "To" nodes, and two "Body" nodes:
<?xml version="1.0" ?>
<Messages>
<Message Date='2004-05-28T12:24:05'>
<From> Gabriele </From>
<To> Jeff </To>
<To> Steve </To>
<Body Language='ENU'> Review ready? </Body>
<Body Language='ITA'> E' pronta la review? </Body>
</Message>
</Messages>
This document can be thought of as a "compact" representation of four different
messages:
- From "Gabriele" to "Jeff" in the "ENU" language;
- From "Gabriele" to "Jeff" in the "ITA" language;
- From "Gabriele" to "Steve" in the "ENU" language;
- From "Gabriele" to "Steve" in the "ITA" language;
When using the "Tree" field mode, these "Message" subtrees are replicated combinatorially to generate all the possible subtrees containing one single instance of each of the "From", "To", and "Body" node types:
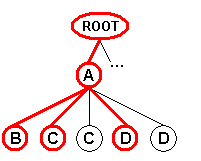 Record 1 |
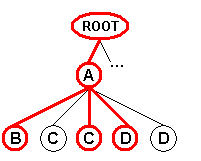 Record 2 |
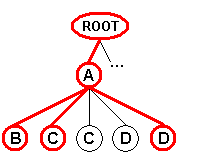 Record 3 |
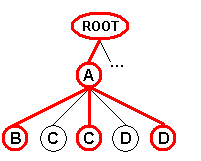 Record 4 |
For example, parsing the above example XML document in "Tree" field mode would produce the following output:
Date From To Body Language ------------------- -------- ----- -------------------- -------- 2004-05-28 12:24:05 Gabriele Jeff Review ready? ENU 2004-05-28 12:24:05 Gabriele Jeff E' pronta la review? ITA 2004-05-28 12:24:05 Gabriele Steve Review ready? ENU 2004-05-28 12:24:05 Gabriele Steve E' pronta la review? ITA
Node Field Mode
In this mode, input records contain only the attributes and values of the document root node or of the node(s) selected by the user-supplied root XPath.
This mode is appropriate for situations in which the information to be retrieved
is associated with a specific node type only.
For example, the relevant information in the document depicted by the following diagram
might be associated with "B" node types only:
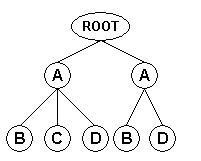
When using the "Node" field mode, the XML input format generates an input record for each root node, either the document root or the node(s) selected by the user-supplied root XPath. Each input record contains the attributes and values of that node only:
 Record 1 |
 Record 2 |
For example, parsing the previous "Cities" example XML document in "Node" field mode specifying "/World/Continent/Country" as the root XPath would produce the following output:
CountryName ----------- USA Canada Italia
Field Types
The data type of each field extracted from the schema tree is determined in the following way:- If all the non-empty field values (node values or attribute values) encountered while constructing the schema tree are formatted as decimal numbers, then the field is assumed to be of the REAL type.
- If all the non-empty field values (node values or attribute values) encountered while constructing the schema tree are formatted as integer numbers, then the field is assumed to be of the INTEGER type.
- If all the non-empty field values (node values or attribute values) encountered while constructing the schema tree are formatted as timestamps in the format specified by the iTsFormat parameter, then the field is assumed to be of the TIMESTAMP type.
- Otherwise, the field is assumed to be of the STRING type.
As an example, the following help command displays the input record structure determined by the XML input format when parsing the previous "Cities" example XML document:
C:\>LogParser -h -i:XML Cities.xmlThe structure displayed by this help command will be:
Fields: ContinentName (S) CountryName (S) City (S) Population (I)