Key-Range Locking
Key-range locking solves the phantom read concurrency problem and supports serializable transactions. Key-range locks cover individual records and the ranges between records, preventing phantom insertions or deletions into a set of records accessed by a transaction. Key-range locks are used only on behalf of transactions operating at the serializable isolation level.
Serializability requires that any query executed during a transaction must obtain the same set of rows if it is executed again at some later point within the same transaction. If this query attempts to fetch a row that does not exist, the row must not be inserted by other transactions until the transaction that attempts to access the row completes. If a second transaction were allowed to insert the row, it would appear as a phantom.
If a second transaction attempts to insert a row that resides on a locked data page, page-level locking prevents the phantom row from being added, and serializability is maintained. However, if the row is added to a data page not already locked by the first transaction, a locking mechanism should be in place to prevent the row from being added.
A key-range lock works by covering the index rows and the ranges between those index rows rather than locking the entire base table rows. Because any attempt to insert, update, or delete any row within the range by a second transaction requires a modification to the index, the second transaction is blocked until the first transaction completes because key-range locks cover the index entries.
Key-Range Lock Modes
Key-range locks include both a range and a row component, specified in range-row format:
- Range represents the lock mode protecting the range between two consecutive index entries.
- Row represents the lock mode protecting the index entry.
- Mode represents the combined lock mode used. Key-range lock modes consist of two parts. The first represents the type of lock used to lock the index range (RangeT) and the second represents the lock type used to lock a specific key (K). The two parts are connected with an underscore (_), such as RangeT_K.
| Range | Row | Mode | Description |
|---|---|---|---|
| RangeS | S | RangeS_S | Shared range, shared resource lock; serializable range scan. |
| RangeS | U | RangeS_U | Shared range, update resource lock; serializable update scan. |
| RangeI | Null | RangeI_N | Insert range, null resource lock; used to test ranges before inserting a new key into an index. |
| RangeX | X | RangeX_X | Exclusive range, exclusive resource lock; used when updating a key in a range. |
Note The internal Null lock mode is compatible with all other lock modes.
Key-range lock modes have a compatibility matrix that shows which locks are compatible with other locks obtained on overlapping keys and ranges.
| Existing granted mode | |||||||
|---|---|---|---|---|---|---|---|
| Requested mode | S | U | X | RangeS_S | RangeS_U | RangeI_N | RangeX_X |
| Shared (S) | Yes | Yes | No | Yes | Yes | Yes | No |
| Update (U) | Yes | No | No | Yes | No | Yes | No |
| Exclusive (X) | No | No | No | No | No | Yes | No |
| RangeS_S | Yes | Yes | No | Yes | Yes | No | No |
| RangeS_U | Yes | No | No | Yes | No | No | No |
| RangeI_N | Yes | Yes | Yes | No | No | Yes | No |
| RangeX_X | No | No | No | No | No | No | No |
Conversion Locks
Conversion locks are created when a key-range lock overlaps another lock.
| Lock 1 | Lock 2 | Conversion Lock |
|---|---|---|
| S | RangeI_N | RangeI_S |
| U | RangeI_N | RangeI_U |
| X | RangeI_N | RangeI_X |
| RangeI_N | RangeS_S | RangeX_S |
| RangeI_N | RangeS_U | RangeX_U |
Conversion locks can be observed for a short period of time under different complex circumstances, sometimes while running concurrent processes.
Serializable Range Scan, Singleton Fetch, Delete, and Insert
Key-range locking ensures that these scenarios are serializable:
- Range scan query
- Singleton fetch of nonexistent row
- Delete operation
- Insert operation
However, the following conditions must be satisfied before key-range locking can occur:
- The transaction-isolation level must be set to SERIALIZABLE.
- The operation performed on the data must use an index range access. Range locking is activated only when query processing (such as the optimizer) chooses an index path to access the data.
The following examples for each of the scenarios are based upon this table and index.
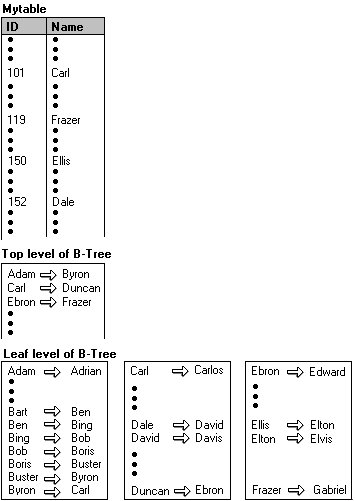
Range Scan Query
To ensure a range scan query is serializable, the same query should return the same results each time it is executed within the same transaction. New rows must not be inserted within the range scan query by other transactions; otherwise, these become phantom inserts. For example, the following query uses the table and index in the previous illustration:
SELECT name FROM mytable WHERE name BETWEEN 'A' AND 'C'
Key-range locks are placed on the index entries corresponding to the range of data rows where the name is between the values Adam and Dale, preventing new rows qualifying in the previous query from being added or deleted. Although the first name in this range is Adam, the RangeS_S mode key-range lock on this index entry ensures that no new names beginning with the letter A can be added before Adam, such as Abigail. Similarly, the RangeS_S key-range lock on the index entry for Dale ensures that no new names beginning with the letter C can be added after Carlos, such as Clive.
Note The number of RangeS_S locks held is n+1, where n is the number of rows that satisfy the query.
Singleton Fetch of Nonexistent Data
If a query within a transaction attempts to select a row that does not exist, issuing the query at a later point within the same transaction has to return the same result. No other transaction can be allowed to insert that nonexistent row. For example, given this query:
SELECT name FROM mytable WHERE name = 'Bill'
A key-range lock is placed on the index entry corresponding to the name range from Ben to Bing because the name Bill would be inserted between these two adjacent index entries. The RangeS_S mode key-range lock is placed on the index entry Bing. This prevents any other transaction from inserting values, such as Bill, between the index entries Ben and Bing.
Delete Operation
When deleting a value within a transaction, the range the value falls into does not have to be locked for the duration of the transaction performing the delete operation. Locking the deleted key value until the end of the transaction is sufficient to maintain serializability. For example, given this DELETE statement:
DELETE mytable WHERE name = 'Bob'
An exclusive (X) lock is placed on the index entry corresponding to the name Bob. Other transactions can insert or delete values before or after the deleted value Bob. However, any transaction attempting to read, insert, or delete the value Bob will be blocked until the deleting transaction either commits or rolls back.
Range delete can be executed using three basic lock modes: row, page, or table lock. The page, table, or row locking strategy is decided by query optimizer, or can be specified by the user through optimizer hints such as ROWLOCK, PAGLOCK, or TABLOCK. In case page or table lock is used, SQL Server immediately releases the index page containing the deleted rows assuming that all rows are deleted from this page. In contrast, when row lock is used, all deleted rows are marked only as deleted; they are removed from the index page later using a background task.
Insert Operation
When inserting a value within a transaction, the range the value falls into does not have to be locked for the duration of the transaction performing the insert operation. Locking the inserted key value until the end of the transaction is sufficient to maintain serializability. For example, given this INSERT statement:
INSERT mytable VALUES ('Dan')
The RangeI_N mode key-range lock is placed on the index entry corresponding to the name David to test the range. If the lock is granted, Dan is inserted and an exclusive (X) lock is placed on the value Dan. The RangeI_N mode key-range lock is necessary only to test the range and is not held for the duration of the transaction performing the insert operation. Other transactions can insert or delete values before or after the inserted value Dan. However, any transaction attempting to read, insert, or delete the value Dan will be locked until the inserting transaction either commits or rolls back.