16. Internationalization with Unicode
What is Unicode?
Unicode is a universal text encoding standard. Rather than being just another way to encode written language, the Unicode standard seeks to gradually replace all other character encoding standards as they will eventually no longer be needed.
Unicode assigns each written character, across all languages, a unique number. As a point of reference, the first 128 characters in Unicode are exactly the same as the ASCII code table characters with the same code point values. And the first 256 characters are exactly the same as the ISO 8859-1 (ISO Latin-1) standard.
A character's unique number (also known as its code point) is written long hand as U+nnnn where nnnn is a hexadecimal number. The Unicode Standard encodes characters in the range U+0000…U+10FFFF. Because this amounts to a 21-bit code space, there are a variety of ways to encode the actual numbers and streams of numbers. These encoding schemes are known as Unicode Transformation Formats (UTFs).
Common UTFs include UTF-8 (CCSID 1208 on IBM i) and UTF-16 (CCSID 1200 on IBM i). UCS-2 (CCSID 13488 on IBM i) is an older UTF and is a subset of UTF-16.
LANSA uses whichever UTF is appropriate. For example, UTF-8 is generally used for flat files for two reasons. The first is that only one byte is required for each character that is in the ASCII code table, so space is saved. The second reason is that there are no issues with byte order. A UTF-8 file is binary-identical whether on Windows, IBM i, or Linux, so it can be easily copied from one platform to another.
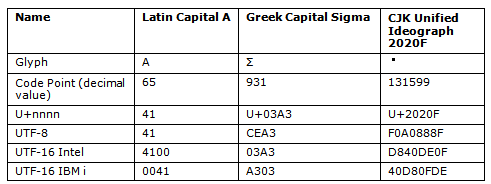
This table gives some examples of different characters and how they are encoded.
Why is Unicode Necessary?
Prior to the development of Unicode as a standard, data conversion from language to language was onerous, with data loss whenever a character could not be represented in a particular code page. It was difficult to correctly handle data that was outside of the norm for a particular region. For example, Japanese names could not be correctly stored or displayed in a system designed for English names, as the character sets and code pages used varied so widely between the two languages.
The introduction of Unicode allows every written language's characters to be handled correctly with no concern of data loss when the data is moved between different environments.
With Unicode, LANSA can now allow display and editing of any number of languages at the same time, both in the Visual LANSA IDE, and also in developed applications.
New development can take advantage of 16.1.1 Unicode Field Types from the beginning, thus minimizing future changes to support new languages or non-standard descriptive text such as names and addresses.
Unicode can also be utilized when modifying existing applications. Fields used in RDMLX applications can be changed to use one of the Unicode Field Types.