Модуль PT4TaskMakerNET: дополнительные компоненты
Если процедура имеет необязательные параметры, то в списке параметров они заключаются в квадратные скобки.
Процедуры для включения в задание файлов
В конструкторе учебных заданий PT4TaskMaker предусмотрена возможность включения в каждое учебное задание (в качестве исходных или результирующих данных) до 10 файлов. Кроме текстовых файлов в заданиях можно использовать двоичные файлы, все элементы которых имеют один и тот же тип (целочисленный, вещественный, символьный, строковый). Каждый файл должен содержать не более 999 элементов (для текстовых файлов элементами считаются файловые строки); в случае, если файл содержит более 999 элементов, элементы с номерами, превышающими 999, в окне задачника не отображаются. Для корректного отображения на экране, а также для правильной проверки результирующих файлов необходимо, чтобы строки в двоичных строковых и текстовых файлах и text состояли из не более чем 70 символов.
Все процедуры, связанные с определением файловых данных, следует вызывать после вызова процедуры CreateTask.
Файлы должны создаваться в текущем каталоге, поэтому при задании их имен не следует указывать имя диска и путь. Рекомендуется снабжать имена всех файлов, используемых в заданиях, расширением .tst.
Все данные из файла, как правило, нельзя одновременно отобразить в окне задачника, поэтому для файловых элементов предусмотрена возможность прокрутки. Для двоичных файлов прокрутка выполняется в горизонтальном направлении, а для текстовых файлов — в вертикальном.
procedure DataFileN(FileName: string; Y, W: integer); procedure DataFileR(FileName: string; Y, W: integer); procedure DataFileC(FileName: string; Y, W: integer); procedure DataFileS(FileName: string; Y, W: integer); procedure DataFileT(FileName: string; Y1, Y2: integer);
Процедуры группы DataFile с именами, завершающимися символами N, R, C, S, позволяют включить в задание в качестве исходного файла один двоичный файл с элементами целочисленного, вещественного, символьного и строкового типа соответственно. Процедура DataFileT позволяет включить в задание в качестве исходного файла один текстовый файл. К моменту вызова процедуры файл, включаемый в задание, должен быть создан, заполнен исходными данными и закрыт. Имя этого файла передается параметром FileName.
Два последних параметра имеют разный смысл для процедур, обрабатывающих двоичные файлы, и для процедуры DataFileT, обрабатывающей текстовые файлы. Для процедур, связанных с двоичными файлами, параметр Y указывает номер экранной строки в области исходных данных, в которой будут отображаться элементы данного файла, а параметр W указывает количество позиций, отводимых под отображение одного элемента файла. Если фактическая длина элемента файла оказывается меньше параметра W, то изображение элемента дополняется пробелами (пробелы добавляются слева для числовых данных и справа для символьных); если длина элемента файла окажется больше значения W, то в конце поля, выделенного для его вывода, будет указан символ «*» (звездочка) красного цвета. При определении параметра W необходимо предусматривать дополнительные позиции для пробелов, служащих разделителями элементов, а в случае строковых и символьных файлов — для апострофов, автоматически добавляемых к каждому элементу при его отображении на экране. Способ отображения вещественных чисел устанавливается, как и для обычных исходных данных, процедурой SetPrecision; по умолчанию вещественные числа отображаются в формате с фиксированной точкой и двумя знаками в дробной части. Количество элементов, отображаемых на экране, определяется автоматически так, чтобы заполнить по возможности всю экранную строку. Никакие другие исходные данные на этой строке размещать нельзя.
Для процедуры DataFileT параметры Y1 и Y2 определяют соответственно номер первой и последней экранной строки той части области исходных данных, которая отводится под отображение текстового файла. На каждой экранной строке размещается одна строка из текстового файла.
Параметры Y, Y1, Y2 должны принимать значения от 1 до 5 (Y и Y1 могут также принимать значение 0; этот случай описан в конце данного раздела); значение Y1 не должно превышать значение Y2. Параметр W должен лежать в диапазоне 1–72.
При наличии нескольких исходных файлов вызов соответствующих процедур группы DataFile может проводиться в любом порядке, независимо от порядка расположения этих файлов на экране. При попытке размещения двух файлов на одной экранной строке выводится сообщение об ошибке. Вызовы процедур группы DataFile могут проводиться как до, так и после вызовов процедур группы Data, определяющих «обычные», не файловые исходные данные.
Вызов процедур группы DataFile не влияет на содержимое включаемых в задание файлов. Он лишь приводит к копированию этого содержимого в специальный буфер в оперативной памяти. Созданная копия используется для отображения содержимого файла на экране; это позволяет просматривать начальное содержимое исходного файла и после его преобразования (или даже удаления) в ходе решения задания.
Поскольку при различных тестовых испытаниях учебного задания желательно не только изменять содержимое исходных файлов, но также и предлагать для обработки файлы с различными именами, возникает опасность «засорения» диска файлами, созданными при предыдущих при предыдущих тестовых испытаниях. Для того чтобы этого не произошло, в задачнике предусмотрено автоматическое удаление при завершении тестового испытания всех файлов, включенных в задание с помощью процедур группы DataFile. Заметим, что это удаление производится и в случае аварийного завершения программы, выполняющей учебное задание. Если же исходный файл был удален самой программой, выполняющей задание, то задачник не будет пытаться удалить этот файл еще раз.
Иногда (хотя и весьма редко — см., например, задание File4) при решении задания не требуется отображать содержимое исходного файла на экране. В этом случае в соответствующей процедуре группы DataFile параметр Y или Y1 надо положить равным 0. Если исходный файл не требуется ни отображать на экране, ни удалять после завершения тестового испытания, то в вызове процедуры группы DataFile нет необходимости.
Следует заметить, что формат двоичных строковых файлов является различным для разных языков программирования. В конструкторе предполагается, что подготовленный для включения в задание двоичный строковый файл имеет формат языка Pascal; в дальнейшем сам задачник выполняет автоматическое преобразование данного файла к формату того языка, на котором выполняется задание. При реализации задания в конструкторе для среды PascalABC.NET достаточно описать двоичный строковый файл как file of ShortString.
Пример реализации задания на обработку двоичных строковых файлов для различных языков программирования приводится в разделе «Примеры».
procedure ResultFileN(FileName: string; Y, W: integer); procedure ResultFileR(FileName: string; Y, W: integer); procedure ResultFileC(FileName: string; Y, W: integer); procedure ResultFileS(FileName: string; Y, W: integer); procedure ResultFileT(FileName: string; Y1, Y2: integer);
Процедуры группы ResultFile с именами, завершающимися символами N, R, C, S, позволяют включить в задание в качестве результирующего файла один двоичный файл с элементами целочисленного, вещественного, символьного и строкового типа соответственно. Процедура ResultFileT позволяет включить в задание в качестве результирующего файла один текстовый файл. К моменту вызова процедуры файл, включаемый в задание, должен быть создан, заполнен контрольными данными и закрыт. Под контрольными данными понимаются, как обычно, данные, которые должны содержаться в результирующем файле в случае правильного решения задания.
Смысл параметров процедур группы ResultFile совпадает со смыслом соответствующих параметров процедур группы DataFile, за исключением того, что теперь номера экранных строк Y, Y1, Y2 относятся к области результирующих данных. Ограничения на параметры для процедур группы ResultFile накладываются те же, что и для процедур группы DataFile.
В результате выполнения процедуры из группы ResultFile содержимое указанного контрольного файла будет скопировано в специальный буфер в оперативной памяти, после чего контрольный файл будет автоматически удален с диска. В дальнейшем, при выполнении задания, файл с таким же именем должен быть создан и заполнен требуемыми данными программой самого учащегося. Контрольные данные, записанные в оперативную память процедурой из группы ResultFile, используются при проверке правильности содержимого результирующего файла (созданного в ходе выполнения задания). Кроме того, эти контрольные данные могут выводиться на экран в качестве примера правильного решения. Имя файла и другие параметры, указанные в процедуре ResultFile, будут также использоваться для поиска и отображения на экране результирующего файла, созданного при выполнении задания. Все результирующие файлы, созданные в ходе решения задания, автоматически удаляются с диска при завершении программы. Подобное удаление производится и при аварийном завершении программы; если же результирующий файл не создан, то попытка его удалить не производится.
Как и в случае процедур группы DataFile, отображение некоторых результирующих файлов можно отключить, положив в соответствующих процедурах ResultFile значения параметров Y или Y1 равными 0 (см., например, задание File1). Это, естественно, не отменит сравнения содержимого результирующих файлов с контрольными данными и удаления результирующих файлов при завершении программы.
При определении двоичных строковых файлов результатов необходимо следовать тем же правилам, что и при определении исходных двоичных строковых файлов (см. завершающую часть описания процедур группы DataFile).
Процедуры для включения в задание указателей и динамических структур данных
В учебные задания можно включать указатели только одного определенного в задачнике типа:
type
PNode = ^TNode;
TNode = record
Data : integer;
Next : PNode;
Prev : PNode;
Left: PNode;
Right: PNode;
Parent: PNode;
end;
Этот тип позволяет формировать одно- и двусвязные линейные динамические структуры
(при этом используются поля связи Next и Prev), бинарные деревья и деревья общего вида (при этом используются поля связи Left и Right),
а также бинарные деревья с обратной связью (при этом используются поля связи Left, Right и Parent).
Поскольку значение адреса, хранящегося в указателе, не представляет интереса (и, кроме того,
может изменяться при каждом тестовом запуске программы), на экране отображается
не оно, а условное обозначение указателя «ptr», снабженное обязательным
комментарием, например, P1 = ptr, PX = ptr и т. д.
В задании можно использовать до 36 различных указателей, которым присваиваются номера от
0 до 35. Указатели с номерами от 0 до 9 имеют комментарии с цифровым индексом
(P0–P9), а указатели с номерами от 10 до 35 — с буквенным
(PA–PZ).
Если некоторый указатель имеет нулевое значение, то вместо текста «ptr» отображается
текст «nil» (или аналогичный текст с обозначением нулевого указателя, соответствующего текущему
языку программирования), например, P1 = nil для языка Pascal,
P1 = NULL для языка C++. Комментарии к указателям также
используются при отображении на экране динамических структур, если они содержат элементы,
с которыми связаны данные указатели.
procedure SetPointer(NP: integer; P: PNode);
Эта процедура позволяет определить в учебном задании указатель с номером NP (значение этого указателя при инициализации задания будет равно P, однако при выполнении задания оно может измениться). Все прочие процедуры, связанные с этим указателем и описываемые далее, используют не его конкретное значение, а номер NP.
Номер NP должен лежать в диапазоне от 0 до 35; он указывается в обязательном комментарии к данному указателю (см. выше). Если процедура SetPointer для указателя с номером NP не вызвана, то указатель с этим номером будет иметь нулевое значение.
procedure DataP([Cmt: string;] NP: integer; X, Y: integer); procedure ResultP([Cmt: string;] NP: integer; X, Y: integer);
Процедуры DataP и ResultP помещают указатель с номером NP в список исходных или,
соответственно, результирующих данных учебного задания и отображают его на
экране. При отображении на экране указатель снабжается обязательным комментарием
вида P# =, где в качестве символа # указывается символ, связываемый
с указателем (для NP от 0 до 9 — соответствующая цифра, для NP от 10 до 35 —
заглавная латинская буква от A до Z). Само значение указателя на экран не выводится;
вместо него указывается одно из двух условных обозначений: ptr для
ненулевого указателя и nil для нулевого указателя. Как и прочие
элементы данных, указатель может снабжаться дополнительным комментарием Cmt,
который приписывается слева к обязательному (например, вызов
процедуры с параметрами Cmt = 'Адрес начала стека: ' и NP = 6
приведет к выводу на экран следующей строки: Адрес начала стека: P6 = ptr).
В дополнительном комментарии Cmt можно использовать управляющие последовательности.
В процедурах DataP и ResultP задается также экранная позиция, начиная с
которой элемент данных выводится в соответствующую экранную область. Параметр Y
определяет номер строки (от 1 до 5), параметр X — позицию в строке (от 1 до 78;
как обычно, требуется, чтобы элемент данных вместе с комментарием полностью
умещался на строке).
Варианты данных процедур, в которых параметр Cmt отсутствует, добавлены в версию 4.11 конструктора.
procedure DataList(NP: integer; X, Y: integer); procedure ResultList(NP: integer; X, Y: integer);
Процедуры DataList и ResultList предназначены для помещения структуры типа «одно- или двусвязный линейный динамический список» в набор исходных или, соответственно, результирующих данных, а также для вывода этой структуры на экран. Параметр NP задает номер указателя (предварительно определенный процедурой SetPointer), который указывает на начало данного списка, т. е. на его первый элемент. Если соответствующий указатель является нулевым, то список считается пустым. Пустой список на экране не отображается.
Непустой динамический список отображается на двух экранных строках; первая строка содержит имена указателей, входящих в задание и связанных с данным списком (они задаются процедурой ShowPointer), во второй строке — значения элементов списка (точнее, их полей Data целого типа) и виды связи между элементами.
Если память для элемента результирующего списка должна быть выделена программой учащегося,
то значение его поля Data на экране обрамляется точками (например, .23.).
Если в исходной динамической структуре требуется разрушить один или несколько элементов, то эти элементы выделяются более бледным цветом,
а в случае, если программа учащегося не освободит память, занимаемую этими элементами, они будут выделены красным цветом.
Наконец, если в списке, преобразованном программой учащегося, элементы располагаются не на требуемых местах,
то они заключаются в скобки (например, (23)), а если элемент списка содержит ошибочную ссылку Next, то она помечается
двумя красными звездочками (например 46 - **). Красные звездочки указываются в конце списка также в случае, если
его длина превышает максимально допустимую.
Специальные обозначения используются также для циклических списков (см. пример 3).
Элемент данных типа «линейный список» должен содержать не более 14 элементов типа TNode, причем значения их полей Data должны лежать в диапазоне от –9 до 99, поскольку для каждого поля Data отводится по две экранные позиции. Для большей наглядности рекомендуется использовать числа из диапазона 10–99, резервируя однозначные и отрицательные числа для особых элементов (например, барьерного элемента циклического списка — см. задание Dynamic70). Если значение элемента списка не умещается в поле вывода, то в его последней экранной позиции выводится красная звездочка — признак ошибки.
Для отображения списка как двусвязного необходимо, чтобы в его элементах были определены поля связи Next и Prev;
в этом случае связи между соседними элементами списка обозначаются двойными линиями: «=». Если в задании
требуется использовать односвязный список, то для его элементов надо определить поле связи Next, а для полей Prev
следует указать значение, не связанное с
элементами этого списка (например, адрес какой-либо глобальной переменной типа TNode).
Связи между элементами односвязных списков обозначаются одинарными линиями: «-».
Вызов процедуры DataList или ResultList приводит к тому, что соответствующий список становится текущей динамической структурой для данного задания. Все последующие вызовы процедур ShowPointer, SetNewNode и SetDisposedNode будут влиять на эту текущую структуру.
procedure DataBinTree(NP, X, Y1, Y2: integer); procedure ResultBinTree(NP, X, Y1, Y2: integer); procedure DataTree(NP, X, Y1, Y2: integer); procedure ResultTree(NP, X, Y1, Y2: integer);
Эти процедуры предназначены для включения в задание бинарных деревьев и деревьев общего вида (называемых также деревьями с произвольным ветвлением) в качестве исходных (DataBinTree и DataTree) или результирующих (ResultBinTree и ResultTree) данных. Для деревьев общего вида используется представление «левая дочерняя вершина — правая сестра» («left child — right sibling»). Как и для процедур DataList и ResultList, описанных выше, первым параметром этих процедур является номер указателя типа PNode, ранее определенного с помощью процедуры SetPointer. В данном случае этот указатель должен указывать на корень добавляемого в задание дерева; если он является нулевым указателем, то дерево считается пустым и не отображается на экране. В отличие от процедур, связанных с линейными списками, для отображения дерева можно (и рекомендуется) выделять на экране более двух строк; номера начальной и конечной экранной строки задаются параметрами Y1 и Y2 соответственно. В отличие от других «прокручиваемых» данных (а именно типизированных и текстовых файлов), дерево может не занимать выделенные для него строки по всей ширине: параметр X показывает, начиная с какой позиции экранных строк будет отображаться дерево и связанная с ним информация. Следует отметить, что использовать для других целей можно только левую часть строки, связанной с деревом; все позиции строки, начиная с позиции X, будут использоваться для отображения дерева.
Вызов любой из описываемых процедур приводит к тому, что соответствующее дерево становится текущей динамической структурой для данного задания. Все последующие вызовы процедур ShowPointer, SetNewNode и SetDisposedNode будут влиять на эту текущую структуру.
При отображении дерева используются обозначения, аналогичные тем, которые применяются при отображении линейных динамических структур.
В частности, в качестве вершины изображается значение ее поля Data, причем для вывода этого значения выделяются две экранные позиции
(если двух позиций недостаточно, например, в случае значения 234, то на второй из выделенных позиций изображается красная звездочка:
2*).
В качестве обозначения связей между вершинами используются одинарные и двойные линии («-» и «=»);
двойные линии, как и для линейных списков, означают,
что связь между вершинами является двусторонней (так называемые деревья с обратной связью — см. пример 6).
Обратная связь обеспечивается полем Parent; ее можно использовать только для бинарных деревьев.
Для деревьев предусмотрены два варианта отображения. Первый вариант предназначен для отображения бинарного дерева; он применяется для деревьев, включенных в задание процедурами DataBinTree и ResultBinTree. В этом варианте обе дочерние вершины располагаются ниже родительской вершины (на следующем уровне — см. примеры 5 и 6). Второй вариант предназначен для отображения дерева общего вида (вершины которого могут содержать более двух дочерних вершин); он применяется для деревьев, включенных в задание процедурами DataTree и ResultTree. В этом варианте вершина, определяемая полем Left вершины P, как обычно, располагается ниже и левее вершины P и задает ее первую (левую) дочернюю вершину, а вершина, определяемая полем Right, моделирует следующую вершину-«сестру» вершины P и поэтому располагается на том же уровне, что и вершина P. Такой способ отображения деревьев позволяет, в частности, легко определить глубину дерева общего вида и номер уровня для любой его вершины (см. пример 7).
Перечислим другие обозначения, имеющие тот же смысл, что и для линейных структур:
- если вершина дерева должна быть создана в программе учащегося, то данная вершина
выделяется слева и справа точками, например,
.23.(для этого используется процедура SetNewNode); - если в дереве, преобразованном программой учащегося, существующие вершины располагаются не на своих местах, то они заключаются в скобки:
(23); - если в исходном дереве требуется разрушить одну или несколько вершин, то эти вершины выделяются более бледным цветом (а в случае, если программа учащегося не освободит память, занимаемую этими вершинами, они будут выделены красным цветом);
- если переход по ссылке Left или Right для данной вершины дерева невозможен, то, как и в случае линейных структур, это отмечается красными звездочками, которые, однако, изображаются не рядом с данной вершиной, а ниже вершины (что подчеркивает тот факт, что ошибка возникла при попытке перехода на следующий уровень дерева).
Для деревьев, в отличие от линейных структур, нулевые поля связи не отображаются. Если поле Left или Right равно нулевому указателю, то на изображении дерева у соответствующей вершины просто отсутствует левая или правая связь.
Максимальное число вершин в дереве равно 18; это объясняется тем, что каждая вершина занимает 4 позиции экранной строки и, кроме того, 4 начальных позиции отводятся под дополнительную информацию (номера уровней дерева). Поэтому, с учетом того, что ширина экранной строки равна 78, вписать в нее можно только дерево с не более чем 18 вершинами. Впрочем, в заданиях рекомендуется использовать не более 16 вершин, начиная вывод дерева с 11 экранной позиции; это дает возможность использовать левую часть строк для отображения других данных, например, указателей, связанных с данным деревом.
Количество уровней дерева ограничивается только количеством его вершин и, таким образом, может достигать 18. В соответствии с общепринятой практикой, уровни дерева нумеруются от 0. Номер уровня отображается в левой части области, отведенной под изображение дерева; он выделяется цветом и отделяется от изображения дерева двоеточием.
Если количество уровней превышает число экранных строк, выделенных для отображения дерева, то для дерева становится возможной прокрутка, подобная прокрутке файловых данных (точнее, данных из текстовых файлов, поскольку для деревьев, как и для текстовых файлов, прокрутка выполняется в вертикальном направлении). На возможность прокрутки указывают дополнительные символы, которые изображаются слева от номера уровня. Символ «стрелка вверх», расположенный на первой экранной строке, отведенной для отображения дерева, означает, что изображение дерева можно пролистать вверх, а символ «стрелка вниз», расположенный на последней экранной строке, отведенной для отображения дерева, означает, что изображение дерева можно пролистать вниз (см. пример 8). В режиме окна с динамической компоновкой все деревья отображаются полностью, поэтому отдельная прокрутка для них не требуется.
Обычно первая строка, отводимая под изображение дерева, содержит его корень и помечается слева числом 0 (нулевой уровень дерева). Единственная ситуация, когда это правило нарушается, связана с ошибочным формированием бинарного дерева с обратной связью в случае, если поле Parent корня не содержит значение nil. В этой ситуации перед строкой с изображением корня дерева помещается еще одна строка, в которой над корнем изображается красная звездочка — признак ошибки.
Изображение дерева может также содержать строки, расположенные ниже последнего уровня; эти строки могут потребоваться для вывода имен указателей, связанных с вершинами-листьями, расположенными на последнем уровне, а также для вывода звездочек, отмечающих ошибочные ссылки Left или Right для вершин, расположенных на последнем уровне дерева. Заметим, что ссылка считается ошибочной в двух случаях:
- если она содержит неверный адрес,
- если она ссылается на вершину, которую нельзя отобразить, поскольку для этой вершины не предусмотрено экранного места.
В частности, звездочки обязательно будут выведены при попытке отобразить на экране дерево с количеством вершин, превышающим 18.
Приведем примеры изображений линейных списков и деревьев. В этих примерах предполагается, что в качестве текущего языка задачника выбран язык Pascal; для других языков вместо nil используются обозначения нулевых указателей или нулевых объектов — (см. описание процедуры SetObjectStyle), соответствующие этим языкам.
P1 24 - 23 >nil
Первый элемент данного списка связан с указателем P1; список содержит два элемента и является односвязным: на это указывает символ «–» между элементами, означающий, что поле Next первого элемента (со значением 24) указывает на второй элемент (со значением 23). Поле Next второго элемента равно nil.
P1 P2 nil< 14 = 23 = 34 >nil
Данный список является двусвязным (двойная связь, использующая оба поля связи — Next и Prev, — обозначается знаком «=»), причем в задании с этим списком связаны два указателя: P1 указывает на его первый, а P2 — на его последний элемент.
P0 << = 15 - 23 = 34 = >>
Данный список является двусвязным циклическим списком (на его цикличность указывают символы «<<» и «>>»), однако одна из его связей отсутствует. А именно, элемент 23 (на который указывает указатель P0) не связан с предыдущим элементом 15, т. е. поле Prev элемента 23 содержит ошибочное значение (например, равно nil). При правильно разработанном задании подобная ситуация может возникнуть только для ошибочных списков, созданных в программе учащегося. Заметим, что связь в другом направлении (от 15 к 23) имеется, т. е. поле Next элемента 15 указывает на элемент 23.
PXPY 95 - 63 -.34.- >>
Данный список является односвязным циклическим списком. Он имеет две особенности. Во-первых, на элемент 95 указывают сразу два указателя (PX и PY), и, во-вторых, элемент 34 должен быть размещен в памяти процедурой New при выполнении задания (на это указывают обрамляющие его точки). Подобные элементы, естественно, могут содержаться только в результирующих списках. Они определяются с помощью процедуры SetNewNode.
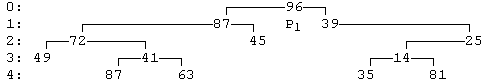
Так выглядит на экране бинарное дерево глубины 4. С корнем этого дерева (поле Data которого равно 96) связан указатель P1.
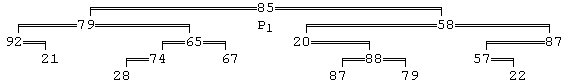
Так выглядит на экране бинарное дерево с обратной связью (номера уровней на данной иллюстрации не указаны).
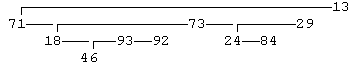
Так выглядит на экране дерево общего вида (номера уровней и имена связанных с деревом указателей на данной иллюстрации не указаны). В данном случае корень дерева 13 имеет три непосредственных потомка: вершины 71, 73 и 29. Напомним, что в дереве общего вида поле Left определяет первую (левую) дочернюю вершину, а поле Right — очередную (правую) вершину-сестру.
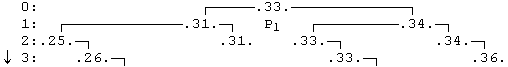
Так выглядит на экране бинарное дерево с включенным режимом прокрутки. Дополнительной особенностью этого дерева является наличие точек около каждой его вершины. Это означает, что данное дерево является результирующим, причем память для всех его вершин должна быть выделена в программе учащегося.
procedure ShowPointer(NP: integer);
Процедура обеспечивает отображение указателя с номером NP при выводе текущего линейного списка или дерева. Например, ее вызов вида ShowPointer(1) обеспечил отображение указателя P1 в примерах 1, 2 и 5. Если указатель номер NP является нулевым, то вызов процедуры ShowPointer игнорируется без вывода сообщения об ошибке. Если указатель с номером NP не является нулевым и не связан ни с одним из элементов списка, то выводится сообщение об ошибке.
С одним элементом списка или дерева можно связать не более двух указателей
(исключение составляет последний элемент списка, с которым можно связать не более трех указателей).
Порядок вызова процедур ShowPointer для одного и того же элемента списка
является произвольным; при отображении указателей, связанных с одним и тем же
элементом, они выводятся в отсортированном порядке (например, P3P6).
В случае списков имена указателей отображаются над элементом, и при наличии нескольких указателей на один элемент
их имена располагаются слева направо. В случае деревьев имена указателей располагаются под элементом,
и при наличии нескольких указателей на один элемент их имена располагаются одно под другим.
Если количество указателей, связываемых процедурами ShowPointer с данным элементом списка,
превосходит максимально допустимое (например, с последним элементом связывается
четыре различных указателя), то список связанных указателей дополняется символом
ошибки — звездочкой (например, P1P2P3*).
Если с элементом бинарного дерева связывается более двух указателей, то под вторым указателем изображается еще один указатель вида P*.
Символ ошибки * выделяется красным цветом.
Если указатель надо связать с элементом списка или дерева, помеченным точками (см. пример 8), то вызов процедуры ShowPointer для данного указателя надо выполнить до того, как для соответствующего элемента списка или дерева будет вызвана процедура SetNewNode (в противном случае при вызове процедуры ShowPointer будет выведено сообщение об ошибке вида «Не найден элемент с адресом P1»).
[Pascal]
procedure SetNewNode(NNode: integer);
[C++]
void SetNewNode(int NNode);
Процедура определяет для текущего списка элемент с номером NNode (нумерация ведется от 1) как элемент, который требуется разместить в памяти с помощью процедуры New в ходе выполнения задания (подобные элементы выделяются в списке с помощью обрамляющих точек — см. пример 4). Она также позволяет аналогичным образом выделить элемент текущего дерева (см. пример 8); при этом предполагается, что элементы дерева нумеруются в префиксном порядке (в частности, корень дерева всегда имеет номер 1; по поводу префиксного порядка см. задание Tree13).
Данная процедура может применяться только к результирующим спискам и деревьям (для определения которых используются процедуры группы Result: ResultList, ResultBinTree, ResultTree). Если результирующий список или дерево не содержит элемента с номером NNode, то выводится сообщение об ошибке.
В случае, если указатель на элемент номер NNode требуется отобразить на экране, вызов соответствующей процедуры ShowPointer необходимо выполнить до вызова процедуры SetNewNode.
Если при выполнении задания учащийся будет выделять память (процедурой New для языка Pascal или аналогичными средствами для других языков) для тех элементов результирующего списка или дерева, для которых это не предусмотрено заданием, то соответствующие элементы в результирующем списке (дереве) будут обрамлены точками, что приведет к сообщению «Ошибочное решение».
procedure SetDisposedNode(NNode: integer);
Процедура определяет для текущего списка или дерева элемент с номером NNode (нумерация ведется от 1, элементы дерева нумеруются в префиксном порядке), который требуется удалить из динамической памяти в ходе выполнения задания. Данная процедура может применятся только к исходным спискам и деревьям (для определения которых используются процедуры группы Data: DataList, DataBinTree, DataTree). Если исходный список или дерево не содержит элемента с номером NNode, то выводится сообщение об ошибке.
Элементы, помечаемые с помощью процедуры SetDisposedNode, выделяются на экране цветом меньшей яркости. Если они не удаляются из памяти в ходе выполнения задания, то их цвет изменяется на красный и выводится соответствующее сообщение об ошибке.
procedure SetObjectStyle;
Данная процедура устанавливает «объектный стиль» для динамических структур и связанных с ними ссылок при выполнении задания в среде PascalABC.NET. Она должна вызываться при формировании заданий, ориентированных на использование не записей TNode и связанных с ними указателей PNode, а объектов класса Node (данный класс определен в вариантах задачника для языков платформы .NET и, в частности, для языка PascalABC.NET).
При разработке заданий класс Node не используется. Даже если разрабатываемая группа заданий ориентирована на его применение, сами задания надо создавать с помощью записей TNode, указателей PNode и описанных выше процедур. Однако для решения подобных задач на языках платформы .NET, а также на языках Python и Java, вместо записей и связанных с ними указателей надо применять объекты класса Node. Среди языков, поддерживаемых версией 4.11 задачника, имеется единственный язык, позволяющий использовать как указатели, так и объекты: это язык PascalABC.NET. Именно поэтому для данного языка предусмотрена процедура SetObjectStyle (в прочих языках, использующих объекты Node, настройка объектного стиля в заданиях на обработку динамических структур выполняется автоматически).
Создавая задания на обработку динамических структур для языка PascalABC.NET, разработчик должен указать учащемуся требуемый способ решения, используя соответствующие термины в формулировке задания («запись» или «объект», «указатель» или «ссылка» и т. п.), а также настроив, при необходимости, вывод динамических структур на «объектный стиль», вызвав процедуру SetObjectStyle (по умолчанию применяется «стиль указателей», подробно описанный выше). Процедура SetObjectStyle должна быть вызвана после процедуры CreateTask (необходимо также, чтобы ее вызов располагался перед вызовами любых процедур, обеспечивающих добавление к заданию динамических структур и связанных с ними указателей). В результате ее вызова изменяется отображение этих элементов данных, а именно:
- вместо текста ptr для непустого указателя указывается текст Node (т. е. имя непустого объекта типа Node);
- в стандартном комментарии к указателю вместо буквы P указывается буква A, например,
A1 = Node(эту особенность следует учитывать в формулировке задания, используя в ней вместо имен указателей P1, P2 и т. д. имена объектов A1, A2 и т. д.).
Аналогичные изменения (символа P на символ A) выполняются и при отображении указателей, связанных с динамическими структурами. Например, односвязный список, приведенный в примере 1, при установке объектного стиля будет иметь следующий вид:
A1 24 - 23 >nil
Слово nil осталось неизменным, так как в PascalABC.NET оно применяется для обозначения как нулевых указателей, так и «пустых» объектов. При использовании других языков платформы .NET обозначения «пустых» объектов соответствующим образом корректируются; так, для языка C# применяется обозначение null, а для языка VB.NET — обозначение Noth (от слова Nothing).
Заметим, что объектный стиль используется в базовых группах ObjDyn и ObjTree, имеющихся в варианте задачника для системы PascalABC.NET. Эти группы с содержательной точки зрения полностью аналогичны группам Dynamic и Tree, ориентированным на применение указателей.
Процедуры для разработки заданий по параллельному MPI-программированию
Процедуры, описанные в настоящем разделе, связаны с разработкой заданий по параллельному программированию и доступны в конструкторе учебных заданий, начиная с версии 4.9 задачника Programming Taskbook. Подробное описание этих процедур приводится в соответствующем разделе описания задачника Programming Taskbook for MPI.
procedure CreateTask([SubgroupName: string;] var ProcessCount: integer);
Данные перегруженные варианты процедуры CreateTask предназначены для инициализации задания по параллельному программированию. От исходных вариантов процедуры CreateTask их отличает наличие параметра ProcessCount. Параметр SubgroupName имеет тот же смысл, что и для исходных вариантов процедуры: он определяет заголовок подгруппы, в которую включается задание, если разрабатываемую группу заданий целесообразно разбить на подгруппы. Если параметр SubgroupName является пустой строкой или отсутствует, то задание не связывается с какой-либо подгруппой.
Параметр ProcessCount определяет количество процессов при выполнении задания в параллельном режиме. Допускается использовать от 2 до 36 процессов. При определении параметра ProcessCount желательно применять датчик случайных чисел; это позволит протестировать предложенный алгоритм решения при различном количестве процессов параллельного приложения.
Если параметр ProcessCount меньше или равен 1, то для инициализации задания используется соответствующий вариант процедуры CreateTask без данного параметра (при этом выходное значение параметра ProcessCount полагается равным 1, а задание выполняется в обычном, «непараллельном» режиме).
Если параметр ProcessCount превосходит 36, то в окне задачника выводится сообщение об ошибке.
Способ использования параметра ProcessCount при инициализации задания по параллельному программированию зависит от того, какую «роль» играет программа, вызвавшая процедуру CreateTask с параметром ProcessCount (см. таблицу).
| «Роль» программы | Входное значение параметра ProcessCount | Выходное значение параметра ProcessCount |
| Непараллельная программа-загрузчик, обеспечивающая запуск параллельного варианта программы | Используется (определяет число процессов при запуске параллельного варианта программы) | Всегда равно 0 |
| Главный процесс параллельной программы (процесс ранга 0) | Не используется | Равно числу процессов в параллельной программе; используется при формировании входных и выходных данных |
| Подчиненный процесс параллельной программы | Не используется | Всегда равно 0 |
| Непараллельная программа, обеспечивающая демонстрационный запуск учебного задания | Используется | Всегда равно входному значению; используется при формировании входных и выходных данных |
procedure SetProcess(ProcessRank: integer);
Данная процедура устанавливает в качестве текущего процесса параллельного приложения процесс ранга ProcessRank. Все числовые исходные и контрольные данные связываются с текущим процессом. До первого вызова данной процедуры текущим процессом считается процесс ранга 0. Процедуру можно вызывать несколько раз с одним и тем же параметром (например, первый раз процесс делается текущим при определении связанных с ним исходных данных, а второй раз — при определении его контрольных данных).
Параметр ProcessRank должен принимать значения в диапазоне от 0 до N – 1, где N — количество процессов, возвращаемое параметром ProcessCount процедуры CreateTask. При нарушении этого условия выводится сообщение об ошибке «Параметр процедуры SetProcess находится вне диапазона 0..N–1, где N — количество используемых процессов».