How Merge Replication Works
From SQL Replication
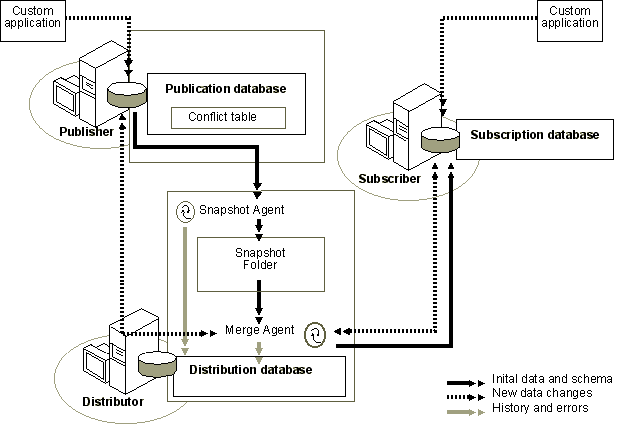
How Merge Replication Works
Merge replication is implemented by the Snapshot Agent and Merge Agent. The Snapshot Agent prepares snapshot files containing schema and data of published tables, stores the files in the snapshot folder, and inserts synchronization jobs in the publication database. The Snapshot Agent also creates replication-specific stored procedures, triggers, and system tables.
The Merge Agent applies the initial snapshot jobs held in the publication database tables to the Subscriber. It also merges incremental data changes that occurred at the Publisher or Subscribers after the initial snapshot was created, and reconciles conflicts according to rules you configure or a custom resolver you create.
The role of the Distributor is very limited in merge replication, so implementing the Distributor locally (on the same server as the Publisher) is very common. The Distribution Agent is not used at all during merge replication, and the distribution database on the Distributor stores history and miscellaneous information about merge replication.
UNIQUEIDENTIFIER Column
Microsoft® SQL Server™ 2000 identifies a unique column for each row in the table being replicated. This allows the row to be identified uniquely across multiple copies of the table. If the table already contains a column with the ROWGUIDCOL property that has a unique index or primary key constraint, SQL Server will use that column automatically as the row identifier for the publishing table.
Otherwise, SQL Server adds a uniqueidentifier column, titled rowguid, which has the ROWGUIDCOL property and an index, to the publishing table. Adding the rowguid column increases the size the publishing table. The rowguid column and the index are added to the publishing table the first time the Snapshot Agent executes for the publication.
Triggers
SQL Server then installs triggers that track changes to the data in each row or each column. The triggers capture changes made to the publishing table and record the changes in merge system tables. Tracking triggers on the publishing tables are created while the Snapshot Agent for the publication runs for the first time. Triggers are created at the Subscriber when the snapshot is applied at the Subscriber.
Different triggers are generated for articles that track changes at the row level or the column level. Because SQL Server supports multiple triggers of the same type on the publishing table, merge replication triggers do not interfere with application-defined triggers.
Stored Procedures
The Snapshot Agent also creates custom stored procedures that update the subscription database. There is one custom stored procedure for INSERT statements, one for UPDATE statements, and one for DELETE statements. When data is updated and the new records need to be entered in the subscription database, the custom stored procedures are used rather than individual INSERT, UPDATE, and DELETE statements. For more information, see Using Custom Stored Procedures in Articles.
System Tables
SQL Server then adds several system tables to the database to support data tracking, efficient synchronization, and conflict detection, resolution and reporting. For every changed or created row, the table MSmerge_contents contains the generation in which the most recent modification occurred. It also contains the version of the row as a whole and every attribute of the row. MSmerge_tombstone stores DELETEs to the data within a publication. These tables use the rowguid column to join to the publishing table.
The generation column in these tables acts as a logical clock indicating when a row was last updated at a given site. Actual datetime values are not used for marking when changes occur, or deciding conflicts, and there is no dependence on synchronized clocks between sites. This makes the conflict detection and resolution algorithms more resilient to time zone differences and differences between physical clocks on multiple servers. At a given site, the generation numbers correspond to the order in which changes were performed by the Merge Agent or by a user at that site.
MSmerge_genhistory and MSmerge_replinfo allow SQL Server to determine the generations that need to be sent with each merge.
There are several tracking columns added to a merge publication table. If your publishing table has column names reserved for merge processing, you will not be able to generate an initial snapshot because of duplicate column names. Reserved column names are:
- reason_code
- source_object
- reason_text
- Pubid
- conflict_type
- origin_datasource
- tablenick
- create_time
Initial Snapshot and the Snapshot Agent
Before a new Subscriber can receive incremental changes from a Publisher, the Subscriber must contain tables with the same schema and data as the tables at the Publisher. Copying the complete current publication from the Publisher to the Subscriber is called applying the initial snapshot. SQL Server will create and apply the snapshot for you, or you can choose to apply the snapshot manually. For more information, see Applying the Initial Snapshot.
Even when creating a subscription for which the snapshot is not applied automatically (sometimes referred to as a nosync subscription), portions of the snapshot are still applied. The necessary tracking triggers and tables are created at the Subscriber, which means that you still need to create and apply a snapshot even when subscriptions specify that the snapshot will not be applied automatically.
Replication of changed data occurs only after merge replication ensures that the Subscriber has the most recent snapshot of the table schema and data that has been generated. When snapshots are distributed and applied to Subscribers, only those Subscribers needing initial snapshots are affected. Subscribers that are already receiving INSERTs, UPDATEs, DELETEs, or other modifications to the published data are unaffected unless the subscription is marked for reinitialization or the publication is marked for a reintialization, in which case all subscriptions corresponding to a given publication are reintialized during the next merge process.
A subscription table can subscribe only to one merge publication at a time. For example, suppose you publish the Customers table in two publications, and then you subscribe to both publications from one Subscriber, indicating the same subscription database will receive data from both publications. One of the Merge Agents will fail during the initial synchronization.
The initial snapshot can be an attached subscription database in snapshot replication, transactional replication, and merge replication. If you use attachable subscription database, a subscription database and its subscriptions will be copied and you can apply them at another Subscriber. For more information, see Attachable Subscription Databases.
The Snapshot Agent implements the initial snapshot in merge replication using similar steps to the Snapshot Agent in snapshot replication. For more information, see Snapshot Replication .
After the snapshot files have been generated, you can view them in the Snapshot Folder using the Snapshot Explorer. In SQL Server Enterprise Manager, expand the Replication and Publications folders, right-click a publication, and then click Explore the Latest Snapshot Folder. For more information, see Exploring Snapshots.
Dynamic Snapshots
Dynamic snapshots provide a performance advantage when applying the snapshot of a merge publication with dynamic filters. By using SQL Server 2000 bulk copy programming files to apply data to a specific Subscriber instead of a series of INSERT statements, you will improve the performance of applying the initial snapshot for dynamically filtered merge publications.
For more information, see Dynamic Snapshots.
Merge Agent
After the initial snapshot has been applied to a Subscriber, SQL Server triggers will begin tracking INSERT, UPDATE and DELETE statements made at the Publisher and at Subscribers.
Every table that participates in merge replication is assigned a generation slot in the MSmerge_articles table. When a row is updated in a merge publication at the Publisher or at Subscribers, even if they are not connected, a trigger updates the generation column in the MSmerge_contents system table for that row to the appropriate generations slot for the given base table. When the Publisher and Subscriber are reconnected and the Merge Agent runs, the Merge Agent collects all the undelivered row changes (with new generation values) into one or more groups and assigns generation values that are higher than all previous generations. This allows the Merge Agent to batch changes to different tables in separate generations and process these batches to achieve efficiency over slow networks.
The Merge Agent at each site keeps track of the highest generation it has sent to each of the other sites, and the highest generation that each of the other sites has sent to it. These provide starting points, so that each table can be examined without looking at data already shared with the other site. The generations stored in a given row can differ between sites because the numbers at a site reflect the order in which changes were processed at that site.
You can limit the number of merge processes running simultaneously by setting the @max_concurrent_merge parameter of sp_addmergepublication or sp_changemergepublication. If the maximum number of merge processes is already running, any new merge processes will wait in a queue. You can set –StartQueueTimeout on the Merge Agent command line to specify how long the agent should wait for the other merge processes to complete. If the –StartQueueTimeout period is exceeded, and the new merge process is still waiting, it will stop and exit.
Synchronization
Synchronization occurs when Publishers and Subscribers in a merge replication topology reconnect and changes are propagated between sites, and if necessary, conflicts detected and resolved. At the time of synchronization, the Merge Agent sends all changed data to the Subscriber. Data flows from the originator of the change to the site that needs to be updated or synchronized.
The direction of the exchange controls whether the Merge Agent uploads changes from the Subscriber (-ExchangeType='Upload'), downloads changes to the Publisher (-ExchangeType='Download') or executes an upload followed by a download (-ExchangeType='Bidirectional'). If the number of changes applied must be controlled, the Merge Agent command line parameters –MaxUploadChanges and –MaxDownloadChanges can be configured. In this case, the data at the Publisher and Subscribers converges only when all changes are propagated.
At the destination database, updates propagated from other sites are merged with existing values according to conflict detection and resolution rules. A Merge Agent evaluates the arriving and current data values, and any conflicts between new and old values are resolved automatically based on the default resolver, a resolver you specified when creating the publication or a custom resolver. Merge replication in SQL Server 2000 offers many out-of-the-box custom resolvers that will help you implement the business logic.
Changed data values are replicated to other sites and converged with changes made at those sites only when synchronization occurs. Synchronizations can occur minutes, days, or even weeks apart and are defined in the Merge Agent schedule. Data is converged and all sites ultimately end up with the same data values, but for this to happen, you would have to stop all updates and merge between sites a couple of times.
The retention period for subscriptions specified for each publication controls how often the Publisher and Subscribers should synchronize. If subscriptions do not synchronize with the Publisher within the retention period, they are marked as 'expired' and will need to be reinitialized. This is to prevent old Subscriber data from synchronizing and uploading these changes to the Publisher. The default retention period for a publication is 14 days. Because the Merge Agent cleans up the publication and subscription databases based on this value, care must be taken to configure this value appropriate to the application.
Note The merge process requires an entry for the Publisher in the sysservers table on the Subscriber. If the entry does not exist, SQL Server will attempt to add this entry. If the login used by the Merge Agent does not have access to add the entry (such as db_owner of the subscription database), an error will be returned.
Reinitializing Subscriptions
Merge replication Subscribers update data based on the original snapshot provided to them unless you mark the subscription for reinitialization. When you mark the subscription for reinitialization, the next time the Merge Agent runs, it will apply a new snapshot to the Subscriber. Optionally, changes made at the Subscriber can be uploaded to the Publisher before the snapshot is reapplied. This ensures that any data changes at the Subscriber are not lost when the subscription is reinitialized.
If you created a subscription and indicated no initial snapshot was to be applied at the Subscriber (the @sync_type parameter set to nosync in sp_addmergesubscription system stored procedure), and you reinitialize the subscription, the snapshot will be reapplied to the Subscriber. This functionality ensures that Subscribers have data and schema identical to data and schema at the Publisher.
If you reinitialize all subscriptions to a merge publication, the subscriptions specified with no initial snapshot synchronization will be reinitialized the same way the subscriptions with synchronization type of 'automatic' are reinitialized. To prevent the reapplication of the snapshot to the Subscriber, drop the subscription specified with no initial snapshot synchronization, and then recreate it after reinitialization.
For more information about synchronization, see Synchronizing Data.
The Merge Agent is a component of SQL Server Agent and can be administered directly by using SQL Server Enterprise Manager. The Snapshot Agent and Merge Agent can also be embedded into applications by using Microsoft ActiveX® controls. The Snapshot Agent executes on the Distributor. The Merge Agent usually executes on the Distributor for push subscriptions and on Subscribers for pull subscriptions. Remote agent activation can be used to offload agent processing to another server. For more information, see Remote Agent Activation.
SQL Server can validate the data at the Subscriber as the replication process is occurring so that you can ensure that data updates applied at the Publisher are applied at Subscribers. For more information, see Validating Replicated Data.
Validating Permissions for a Subscriber
SQL Server 2000 provides the option to validate permissions for a Subscriber to upload data changes to a Publisher. This verifies that the Merge Agent login has the permissions to perform INSERT, UPDATE, and DELETE commands on the publication database. Validating permissions requires that the Merge Agent login be a valid user with the appropriate permissions in the publication database.
This permissions validation is in addition to the verification that the logins used at the Subscriber are in the publication access list (PAL).
Validating permissions for a Subscriber can be set using the @check_permissions property in sp_addmergearticle or by using the CheckPermissions Property in SQL-DMO. For more information, see CheckPermissions Property. You can specify one or more of the following values for the @check_permissions parameter in sp_addmergearticle.
| Value | Description |
|---|---|
| 0 (Default) | Permissions will not be checked. |
| 1 | Check permissions at the Publisher before INSERTs made at a Subscriber can be uploaded. |
| 2 | Check permissions at the Publisher before UPDATEs made at a Subscriber can be uploaded. |
| 4 | Check permissions at the Publisher before DELETEs made at a Subscriber can be uploaded. |
Note If you set the @check_permissions parameter after the initial snapshot has been generated, a new snapshot must be generated and reapplied at the Subscriber in order for permissions to be validated when data changes are merged.
Cleaning Up Merge Replication
When the distribution database is created, SQL Server adds the following tasks automatically to SQL Server Agent to purge the data no longer needed:
- Subscription cleanup at the Publisher
- History cleanup at the Distributor
These tasks help replication to function effectively in a long-running environment; therefore, administrators should plan for this periodic maintenance. The cleanup tasks delete the initial snapshot for each publication and remove history information in the Msmerge_history table.
Merge Meta Data Cleanup
The sp_mergecleanupmetadata system stored procedure allows administrators to clean up meta data in the MSmerge_contents and MSmerge_tombstone system tables. Although these tables can expand infinitely, in some cases it improves merge performance to clean up the meta data. This procedure can be used to save space by reducing the size of these tables at the Publisher and Subscribers.
Before executing this stored procedure, merge all data from Subscribers with the Publisher to load all the Subscriber data changes that must be saved. Snapshot files for all merge publications involved at all levels must be regenerated after executing this stored procedure. If you try to merge without running the snapshot first, you will receive a prompt to run the snapshot.
Caution After sp_mergecleanupmetadata is executed, by default, all subscriptions at the Subscribers of publications that have meta data stored in the two tables are marked for reinitialization, changes at the Subscriber are lost, and the current snapshot is marked obsolete.
The reinitialization propagates the merge topology automatically. The administrator does not have to reinitialize all subscriptions at every republisher manually. When using SQL Server 7.0 with Service Pack 2, the reinitialization does not propagate through the merge topology automatically.
By default, the @reinitialize_subscriber parameter of sp_mergecleanupmetadata is set to TRUE, and all subscriptions are marked for reinitialization. If you set the @reinitialize_subscriber parameter to FALSE, the subscriptions are not marked for reinitialization. Setting the parameter to FALSE should be used with caution because if you choose not to have the subscriptions reinitialized, you must make sure that data at the Publisher and Subscribers is synchronized.
If sp_mergecleanupmetadata is executed with the @reinitialize_subscriber parameter set to TRUE, the snapshot will be reapplied at the Subscriber even if the subscription was created without an initial snapshot applied (for example, if the snapshot data and schema were manually applied or already existed at the Subscriber). If you do not want the subscription to be reinitialized and the snapshot reapplied, the subscription must be dropped and re-created as a subscription with no initial synchronization after ensuring that the data is in synchronization between Publisher and Subscriber.
If you want to run sp_mergecleanupmetadata without the subscriptions being marked for reinitialization:
- Synchronize all Subscribers.
- Stop all updates to the publication and subscription databases.
- It is recommended that you execute a merge that validates the Subscriber data with the Publisher by running the Merge Agent with the -Validate command line option at each Subscriber.
- Execute the sp_mergecleanupmetadata system stored procedure. After the stored procedure has executed, you can allow users to update the publication and subscription databases again.
Execute sp_mergecleanupmetadata after all merges, including continuous mode merges, have been completed. One method for controlling this is to deactivate the publication and activate it after the merge cleanup has been completed.
For example, execute code similar to the following at the Publisher:
EXEC central..sp_changemergepublication 'publicationname', 'status', 'inactive'
This ensures that all continuous mode merges that are polling for the publication status will fail if the publication has been inactivated. Execute the following after all continuous mode merges have terminated:
EXEC central..sp_mergecleanupmetadata 'publicationname',
@reinitialize_subscriber='false'
EXEC central..sp_changemergepublication 'publicationname', 'status', 'active'
If the merge cleanup is propagated to a republisher that is not yet inactive,an error message is returned stating that cleanup of merge meta data could not be performed.
To use this stored procedure, the Publisher and all Subscribers must be running Microsoft SQL Server 7.0 with Service Pack 2 or later. Only members of sysadmin and db_owner role can use this stored procedure. To clean up merge meta data, execute the sp_mergecleanupmetadata system stored procedure. If you specify a @tablename parameter, only the merge meta data for that table will be cleaned. If no table name is specified, all merge meta data in MSmerge_contents and MSmerge_tombstone will be cleaned.
Important If there are multiple publications on a database, and any one of those publications uses an infinite publication retention period (@retention=0), running sp_mergecleanupmetadata will not clean up the merge replication change tracking meta data for the database. For this reason, use infinite publication retention with caution.