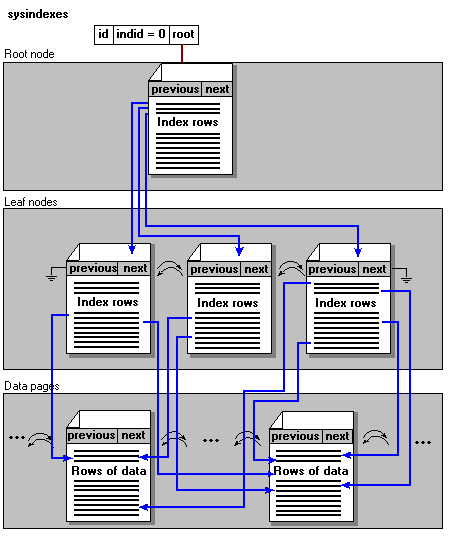
Nonclustered Indexes
Nonclustered indexes have the same B-tree structure as clustered indexes, with two significant differences:
- The data rows are not sorted and stored in order based on their nonclustered keys.
- The leaf layer of a nonclustered index does not consist of the data pages.
Instead, the leaf nodes contain index rows. Each index row contains the nonclustered key value and one or more row locators that point to the data row (or rows if the index is not unique) having the key value.
Nonclustered indexes can be defined on a table with a clustered index, a heap, or an indexed view. In Microsoft® SQL Server™ 2000, the row locators in nonclustered index rows have two forms:
- If the table is a heap (does not have a clustered index), the row locator is a pointer to the row. The pointer is built from the file identifier (ID), page number, and number of the row on the page. The entire pointer is known as a Row ID.
- If the table does have a clustered index, or the index is on an indexed view, the row locator is the clustered index key for the row. If the clustered index is not a unique index, SQL Server 2000 makes duplicate keys unique by adding an internally generated value. This value is not visible to users; it is used to make the key unique for use in nonclustered indexes. SQL Server retrieves the data row by searching the clustered index using the clustered index key stored in the leaf row of the nonclustered index.
Because nonclustered indexes store clustered index keys as their row locators, it is important to keep clustered index keys as small as possible. Do not choose large columns as the keys to clustered indexes if a table also has nonclustered indexes.