Clustered Indexes
Clustered indexes have one row in sysindexes with indid = 1. The pages in the data chain and the rows in them are ordered on the value of the clustered index key. All inserts are made at the point the key value in the inserted row fits in the ordering sequence.
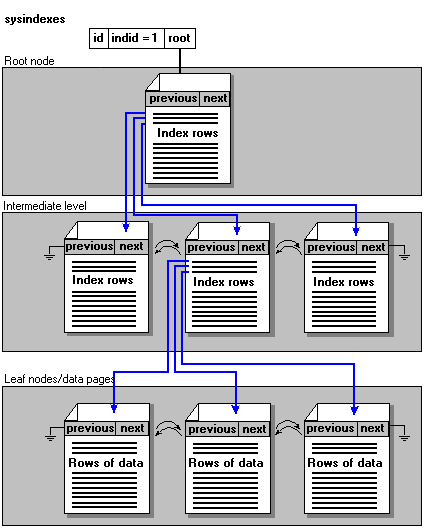
Microsoft® SQL Server™ 2000 indexes are organized as B-trees. Each page in an index holds a page header followed by index rows. Each index row contains a key value and a pointer to either a lower-level page or a data row. Each page in an index is called an index node. The top node of the B-tree is called the root node. The bottom layer of nodes in the index are called the leaf nodes. The pages in each level of the index are linked together in a doubly-linked list. In a clustered index, the data pages make up the leaf nodes. Any index levels between the root and the leaves are collectively known as intermediate levels.
For a clustered index, sysindexes.root points to the top of the clustered index. SQL Server navigates down the index to find the row corresponding to a clustered index key. To find a range of keys, SQL Server navigates through the index to find the starting key value in the range, and then scans through the data pages using the previous or next pointers. To find the first page in the chain of data pages, SQL Server follows the leftmost pointers from the root node of the index.
This illustration shows the structure of a clustered index.