Using EXPLICIT Mode
In an EXPLICIT mode, the query writer controls shape of the XML document returned by the execution of the query. The query must be written in a specific way so that the additional information about the expected nesting is explicitly specified as part of the query. You can also specify additional configurations at the column level using the directives. When you specify EXPLICIT mode, you must assume the responsibility for ensuring that the generated XML is well-formed and valid (in case of an XML-DATA schema).
Processing EXPLICIT Mode Queries and the Universal Table
The EXPLICIT mode transforms the rowset resulting from the query execution into an XML document. For the EXPLICIT mode to produce the XML document, the rowset must have certain format. This requires the SELECT query to be written in a certain way to produce the rowset with a specific format (called the universal table), which can then be processed to produce the requested XML document.
First the EXPLICIT mode requires the query to produce two meta data columns:
- The first column specified in the SELECT clause must be a named (Tag) tag number. The Tag column stores the tag number of the current element. Tag is an integer data type.
- The second column specified must be a named (Parent) tag number of the parent element. The Parent column stores the tag number of the parent element. Tag is an integer data type.
These columns are used to determine the parent-child hierarchy in the XML tree. This information is then used to produce the desired XML tree. If the parent tag value stored in Parent column is 0 or NULL, the row is placed on the top level of the XML hierarchy.
The remainder of the universal table fully describes the resulting XML document. An example of a universal table showing the nesting for the <Customer>, <Order>, and <OrderDetail> elements is shown in this illustration.
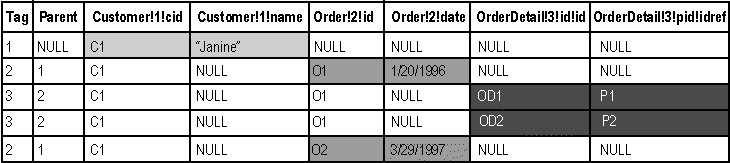
The data in the rowset (universal table) is partitioned vertically into groups. Each group becomes an XML element in the result.
A query that generates this sample universal table will produce the following XML document in the EXPLICIT mode (one of the examples below describes the query). Only the partial output is shown:
<Customer cid="C1" name="Janine">
<Order id="O1" date="1/20/1996">
<OrderDetail id="OD1" pid="P1"/>
<OrderDetail id="OD2" pid="P2"/>
</Order>
<Order id="O2" date="3/29/1997">
...
</Customer>
The FOR XML EXPLICIT mode requires that the SELECT query specify the column names in the universal table in a certain way. It requires that the SELECT query associate the element names with the tag numbers and provide the property names (attribute names by default) in the column names of the universal table. In addition, to get the correct children instances associated with their parent, the rowset needs to be ordered such that the parent is followed immediately by its children.
To summarize, the information provided in the column names of the universal table, the values in the Tag and Parent meta columns, and the data in the universal table format are used to generate the desired XML document in the EXPLICIT mode.
Specifying Column Names in a Universal Table
The SELECT query must specify the column names in a universal table. The column names in the universal table are encoded using XML generic identifiers and attribute names. The encoding of the element name, the attribute names, and other transformation information in the column name in the universal table are specified as:
ElementName!TagNumber!AttributeName!Directive
Arguments
ElementName
Is the resulting generic identifier of the element (for example, if Customers is specified as ElementName, then <Customers> is the element tag).
TagNumber
Is the tag number of the element. TagNumber, with the help of the two meta data columns (Tag and Parent) in the universal table, is used to express the nesting of XML elements in the XML tree. Every TagNumber correspond to exactly one ElementName.
AttributeName
Is either the name of the XML attribute (if Directive is not specified) or the name of the contained element (if Directive is either xml, cdata, or element). If Directive is specified, AttributeName can be empty. In this case, the value contained in the column is directly contained by the element with the specified ElementName.
Directive
Is an optional directive. If Directive is not specified, AttributeName must be specified. If AttributeName is not specified and Directive is not specified (for example, Customer!1), an element directive is implied (for example, Customer!1!!element), and data is contained.
Directive has two purposes. This option is used to encode ID, IDREF, and IDREFS by using the keywords ID, IDREF, and IDREFS. It is also used to indicate how to map the string data to XML using the keywords hide, element, xml, xmltext, and cdata. Combining directives between these two groups is allowed in most of the cases, but not combining among themselves.
- ID
- An element attribute can be specified to be an ID type attribute. IDREF and IDREFS attributes can then be used to refer to them, enabling intradocument links. If XMLDATA is not requested, this keyword has no effect.
- IDREF
- Attributes specified as IDREF can be used to refer to ID type attributes, enabling intradocument links. If XMLDATA is not requested, this keyword has no effect.
- IDREFS
- Attributes specified as IDREFS can be used to refer to ID type attributes, enabling intradocument links. If XMLDATA is not requested, this keyword has no effect.
- hide
- The attribute is not displayed. This may be useful for ordering the result by an attribute that will not appear in the result.
- element
- This does not generate an attribute. Instead it generates a contained element with the specified name (or generate contained element directly if no attribute name is specified). The contained data is encoded as an entity (for example, the < character becomes <). This keyword can be combined with ID, IDREF, or IDREFS.
- xml
- This is the same as an element directive except that no entity encoding takes place (for example, the < character remains <). This directive is not allowed with any other directive except hide.
- xmltext
- The column content should be wrapped in a single tag that will be integrated with the rest of the document. This directive is useful in fetching overflow (unconsumed) XML data stored in a column by OPENXML. For more information, see Writing XML Using OPENXML.
If AttributeName is specified, the tag name is replaced by the specified name; otherwise, the attribute is appended to the current list of attributes of the enclosing elements and by putting the content at the beginning of the containment without entity encoding. The column with this directive must be a text type (varchar, nvarchar, char, nchar, text, ntext). This directive can be used only with hide. This directive is useful in fetching overflow data stored in a column.
If the content is not a well-formed XML, the behavior is undefined.
- cdata
- Contains the data by wrapping it with a CDATA section. The content is not entity encoded. The original data type must be a text type (varchar, nvarchar, text, ntext). This directive can be used only with hide. When this directive is used, AttributeName must not be specified.
Examples
The queries in these examples can be executed using SQL Query Analyzer. To execute these queries using HTTP, see Accessing SQL Server Using HTTP.
The process for writing queries using EXPLICIT mode is explained in detail in Examples A and B. This process applies to the other examples that follow.
A. Retrieve customer and order information
This example retrieves customer and order information. Assume you want the following hierarchy generated:
<Customer CustomerID="ALFKI">
<Order OrderID=10643>
<Order OrderID=10692>
...
</Customer>
<Customer CustomerID="ANATR" >
<Order OrderID=10308 >
<Order OrderID=10625 >
...
</Customer>
The universal table produced by the query from which the resulting XML tree is produced contains two meta data columns: Tag and Parent. Therefore, in specifying the query the SELECT clause must specify these columns. The values in these columns are used in generating the XML hierarchy.
The <Customer> element is at the top level. In this example, this element is assigned a Tag value of 1 (this can be any number, but there is unique number associated with each element name). Because <Customer> is a top-level element, its Parent tag value is NULL.
The <Order> element is a child of the <Customer> element. Therefore, the Parent tag value for <Order> element is 1 (identifying <Customer> as its parent element). The <Order> element is assigned a Tag value of 2.
You can write a query with two SELECT statements and use UNION ALL to combine the results of the statements:
- In the first SELECT statement in the query, all the <Customer> elements and their attribute values are obtained. In a query with multiple SELECT statements, only the column names (universal table column names) that are specified in the first query are used. The column names specified in the subsequent SELECT statements are ignored. Therefore, the column names for the universal table that specify the XML element and attribute names are included in this query:
SELECT 1 as Tag, NULL as Parent, Customers.CustomerID as [Customer!1!CustomerID], NULL as [Order!2!OrderID] FROM Customers - In the second query, all <Order> elements and their attribute values are retrieved:
SELECT 2, 1, Customers.CustomerID, Orders.OrderID FROM Customers, Orders WHERE Customers.CustomerID = Orders.CustomerID - The two SELECT statements in the query are combined with a UNION ALL.
- The universal table rowset (containing all data and meta data) is scanned one row at a time, in a forward-only manner, producing the resulting XML tree. To yield the proper XML document hierarchy, it is also important to specify the order of rows in the universal table. This is achieved by using the ORDER BY clause in the query.
- This is the final query:
SELECT 1 as Tag, NULL as Parent, Customers.CustomerID as [Customer!1!CustomerID], NULL as [Order!2!OrderID] FROM Customers UNION ALL SELECT 2, 1, Customers.CustomerID, Orders.OrderID FROM Customers, Orders WHERE Customers.CustomerID = Orders.CustomerID ORDER BY [Customer!1!CustomerID], [Order!2!OrderID] FOR XML EXPLICIT
The resulting universal table is a four-column table. For illustration purposes, only a few rows are shown.
| Tag | Parent | Customer!1!CustomerID | Order!2!OrderID |
|---|---|---|---|
| 1 | NULL | ALFKI | NULL |
| 2 | 1 | ALFKI | 10643 |
| 2 | 1 | ALFKI | 10692 |
| 2 | 1 | ALFKI | 10702 |
| 2 | 1 | ALFKI | 11011 |
| 2 | 1 | ALFKI | ... |
| 1 | NULL | ANATR | NULL |
| 2 | 1 | ANATR | 10308 |
| 2 | 1 | ANATR | 10625 |
| 2 | 1 | ANATR | ... |
The processing of the rows in the universal table to produce the resulting XML tree is described here:
- The first row identifies Tag value 1. All columns with the Tag value 1 are identified. In this case, there is only one column: Customer!1!CustomerID. This column name is composed of element name (Customer), tag number (1), and attribute name (CustomerID). Therefore, a <Customer> element is created, and an attribute CustomerID is added to it. The column value is then assigned as the attribute value.
- The second row has the Tag value 2. Therefore, all columns with the Tag value 2 are identified. There is only one column with the Tag value 2: Order!2!OrderID. The column name is composed of element name (Order), tag number (2) and attribute name (OrderID). This row also identifies <Customer> as its parent (Parent value is 1). As a result, an <Order> element is created as a child of the <Customer> element and an attribute OrderID is added to it. The column value is then assigned as the attribute value.
- All the subsequent rows with Tag value 2 are processed in the same manner.
- A row with Tag value 1 is identified. It identifies the Customer!1!CustomerID column with the Tag value 1. This column identifies a <Customer> element with no parent (Parent is NULL). Thus, both the previous <Order> tag and the previous <Customer> tag are closed. A new <Customer> tag is opened, and the process is repeated.
Because Directive is not specified in the query, the attribute name is the name of the XML attribute. This is the partial result set:
<Customer CustomerID="ALFKI">
<Order OrderID="10643" />
<Order OrderID="10692" />
<Order OrderID="10702" />
<Order OrderID="11011" />
</Customer>
<Customer CustomerID="ANATR">
<Order OrderID="10308" />
<Order OrderID="10625" />
</Customer>
B. Specify the element directive
This example retrieves the customer and order information. Assume you want the following hierarchy generated: (note that <OrderID> is a subelement of <Order> and not an attribute):
<Customer CustomerID="ALFKI">
<Order OrderDate="1997-08-25T00:00:00">
<OrderID>10643</OrderID>
</Order>
<Order OrderDate="1997-10-03T00:00:00">
<OrderID>10692</OrderID>
</Order>
...
</Customer>
The <Customer> element is at the top level. In this example, it is assigned a Tag value of 1. Because <Customer> is a top-level element, its Parent tag value is NULL.
The <Order> element is a child of <Customer> element. Therefore, the Parent tag value for <Order> element is 1 (identifying <Customer> as its parent element) and it is assigned a Tag value of 2.
The <Order> element has <OrderID> as a contained element (not an attribute). Therefore, in retrieving this value, the element directive must be specified.
You can write a query with two SELECT statements and use a UNION ALL to combine the results of the statements:
- In the first SELECT statement in the query, all the <Customer> elements and their attribute values are obtained. In a query with multiple SELECT statements, only the column names (universal table column names) that are specified in the first query are used. The column names specified in the subsequent SELECT statements are ignored. Therefore, the column names for the universal table that specify the XML element and attribute names are included in this query:
SELECT 1 as Tag, NULL as Parent, Customers.CustomerID as [Customer!1!CustomerID], NULL as [Order!2!OrderID!element], NULL as [Order!2!OrderDate] FROM Customers
- In the second query, all <Order> elements and their attribute values are retrieved. This query selects Customers.CustomerID because of the required grouping of parent with children using ORDER BY clause.
SELECT 2, 1, Customers.CustomerID, Orders.OrderID, Orders.OrderDate FROM Customers, Orders WHERE Customers.CustomerID = Orders.CustomerID - The two SELECT statements in the query are combined with a UNION ALL.
- The ORDER BY clause is used to specify the order of the rows in the universal table rowset that is generated.
- This is the final query:
SELECT 1 as Tag, NULL as Parent, Customers.CustomerID as [Customer!1!CustomerID], NULL as [Order!2!OrderID!element], NULL as [Order!2!OrderDate] FROM Customers UNION ALL SELECT 2, 1, Customers.CustomerID, Orders.OrderID, Orders.OrderDate FROM Customers, Orders WHERE Customers.CustomerID = Orders.CustomerID ORDER BY [Customer!1!CustomerID], [Order!2!OrderID!element] FOR XML EXPLICIT
The resulting universal table is a five-column table. For illustration purposes, only a few rows are shown.
Tag |
Parent |
Customer!1!CustomerID | Order!2!OrderID!element | Order!2!OrderDate |
|---|---|---|---|---|
| 1 | NULL | ALFKI | NULL | NULL |
| 2 | 1 | ALFKI | 10692 | 1997-10-03T00:00:00 |
| 2 | 1 | ALFKI | 10702 | 1997-10-13T00:00:00 |
| 2 | 1 | ALFKI | 10835 | 1998-01-15T00:00:00 |
| ... | ... | ... | ... | ... |
| 1 | NULL | ANATR | 10308 | 1996-09-18T00:00:00 |
| 1 | NULL | ANATR | ... | ... |
The processing of the rows in the rowset to produce the resulting XML tree is described here:
- The first row identifies Tag value 1. Therefore, all the columns with Tag value 1 are identified. In this case there is only one column: Customer!1!CustomerID column. This column name is composed of element name (Customer), tag number (1) and attribute name (CustomerID). Therefore, a <Customer> element is created and an attribute CustomerID is added to it. The column value is then assigned as the attribute value.
- The second row has Tag value 2. All the columns with Tag value 2 are identified. There are two columns (Order!2!OrderID!element and Order!2!OrderDate) with the tag number 2.
- Column Order!2!OrderDate is composed of element name (Order), tag number (2) and the attribute name (OrderDate). This row identifies <Customer> as its parent (Parent value is 1). Therefore, an <Order> element is created as a child of the <Customer> element, and an attribute OrderID is added to it. The column value is assigned as the attribute value.
- The column name, Order!2!OrderID!element consists of the directive (element). Therefore, a contained element (<OrderID>) is generated. The column value is assigned as the element value.
- Column Order!2!OrderDate is composed of element name (Order), tag number (2) and the attribute name (OrderDate). This row identifies <Customer> as its parent (Parent value is 1). Therefore, an <Order> element is created as a child of the <Customer> element, and an attribute OrderID is added to it. The column value is assigned as the attribute value.
- All the subsequent rows with Tag value 2 are processed in the same manner.
- A row with Tag value 1 is identified. It identifies Customer!1!CustomerID column with Tag value 1. This column identifies a <Customer> element with no parent (Parent is NULL). Therefore, both the previous <Order> tag and the previous <Customer> tag are closed. A new <Customer> tag is opened, and the process is repeated.
Note In the query, if the column name (Order!2!OrderID!element) is changed so that the attribute name is not specified (Order!2!!element), the query generates the contained element directly.
C. Specify the element directive and the entity encoding
If the directive is set to element, the contained data is entity encoded. For example, if one of the customer contact names in the Customers table is Mar<ia Anders, the following query encodes the contained data:
--Update customer record.
UPDATE Customers
SET ContactName='Mar<ia Anders'
WHERE ContactName='Maria Anders'
GO
The following query returns the customer ID and contact name information.
The process of writing the query to produce the universal table and the processing of the universal table rowset to produce the resulting XML document is similar to the process described in Example A and Example B.
SELECT 1 as Tag, NULL as Parent,
Customers.CustomerID as [Customer!1!CustomerID],
Customers.ContactName as [Customer!1!ContactName!element]
FROM Customers
ORDER BY [Customer!1!CustomerID]
FOR XML EXPLICIT
GO
-- set the value back to original
UPDATE Customers
SET ContactName='Maria Anders'
WHERE ContactName='Mar<ia Anders'
GO
The partial result is shown below. Because the element directive is specified in the query, the attribute name specified is the name of the contained element. Also the ContactName is entity encoded (the < character in the ContactName is returned as <)
<Customer CustomerID="ALFKI">
<ContactName>Mar<ia Anders</ContactName>
</Customer>
<Customer CustomerID="ANATR">
<ContactName>Ana Trujillo</ContactName>
</Customer>
D. Specify the xml directive
The xml directive is similar to element directive except that the contained data is not entity encoded (the < character remains <). For example, if one of the customer contact names in the Customers table is Mar<ia Andears, the following query does not entity encode the contained data and generates an XML document that is not well-formed.
-- Update a customer record.
UPDATE Customers
SET ContactName='Mar<ia Anders'
WHERE ContactName='Maria Anders'
GO
The following query returns the customer ID and contact name information.
The process of writing the query to produce the universal table and the processing of the universal table rowset to produce the resulting XML document is similar to the process described in Example A and Example B.
SELECT 1 as Tag, NULL as Parent,
Customers.CustomerID as [Customer!1!CustomerID],
Customers.ContactName as [Customer!1!ContactName!xml]
FROM Customers
ORDER BY [Customer!1!CustomerID]
FOR XML EXPLICIT
GO
-- Set customer record back to the original.
UPDATE Customers
SET ContactName='Maria Anders'
WHERE ContactName='Mar<ia Anders'
GO
The partial result is shown below. Because the directive is specified in the query, the attribute name specified is the name of the contained element.
<Customer CustomerID="ALFKI">
<ContactName>Mar<ia Anders</ContactName>
</Customer>
<Customer CustomerID="ANATR">
<ContactName>Ana Trujillo</ContactName>
</Customer>
E. Specify the hide directive
This example shows the use of the hide directive. This directive is useful when you want the query to return an attribute for ordering the rows in the universal table returned by the query but you do not want that attribute in the final resulting XML document.
Assume you want the following hierarchy generated where the <Customer> elements are ordered by CustomerID, and within each <Customer> element, the <Order> elements are sorted by OrderID. Note that the OrderID attribute is not in the resulting XML document:
<Customer CustomerID="ALFKI">
<Order OrderDate="1997-08-25T00:00:00" />
<Order OrderDate="1997-10-03T00:00:00" />
<Order OrderDate="1997-10-13T00:00:00" />
</Customer>
In this case, the OrderID is retrieved for ordering purposes but in specifying the column name for this attribute, the hide directive is specified. As a result the OrderID attribute is not displayed as part of the resulting XML document.
The process of writing the query to produce the universal table and the processing of the universal table rowset to produce the resulting XML document is similar to the process described in Example A and Example B.
This is the query:
SELECT 1 as Tag,
NULL as Parent,
Customers.CustomerID as [Customer!1!CustomerID],
NULL as [Order!2!OrderID!hide],
NULL as [Order!2!OrderDate]
FROM Customers
UNION ALL
SELECT 2,
1,
Customers.CustomerID,
Orders.OrderID,
Orders.OrderDate
FROM Customers, Orders
WHERE Customers.CustomerID = Orders.CustomerID
ORDER BY [Customer!1!CustomerID], [Order!2!OrderID!hide]
FOR XML EXPLICIT
This is the partial result. The OrderID attribute is not in the resulting document.
<Customer CustomerID="ALFKI">
<Order OrderDate="1997-08-25T00:00:00" />
<Order OrderDate="1997-10-03T00:00:00" />
<Order OrderDate="1997-10-13T00:00:00" />
</Customer>
<Customer CustomerID="ANATR">
<Order OrderDate="1996-09-18T00:00:00" />
<Order OrderDate="1997-08-08T00:00:00" />
</Customer>
F. Specify the cdata directive
If the directive is set to cdata, the contained data is not entity encoded but is put in the CDATA section. The cdata attributes must be nameless.
The following query wraps the contact names in the CDATA sections. The process of writing the query to produce the universal table and the processing of the universal table rowset to produce the resulting XML document is similar to the process described in Example A and Example B.
SELECT 1 as Tag,
NULL as Parent,
Customers.CustomerID as [Customer!1!CustomerID],
Customers.ContactName as [Customer!1!!cdata]
FROM Customers
ORDER BY [Customer!1!CustomerID]
FOR XML EXPLICIT
The partial result is shown below. The contained data is wrapped in the CDATA section, and the contained data is not entity encoded (the contact name remains Mar<ia Ande!rs).
<Customer CustomerID="ALFKI">
<![CDATA[Maria Anders]]>
</Customer>
<Customer CustomerID="ANATR">
<![CDATA[Ana Trujillo]]>
</Customer>
G. Specify the ID and IDREF directives
In an XML document, an element attribute can be specified as an ID type attribute and the IDREF attributes in the document can then be used to refer to them, thereby enabling intradocument links (similar to the primary key and foreign key relationship in relational databases).
The query in this example returns an XML document that consists of the ID and IDREF attributes. The example retrieves customer and order information. The query is to return this XML document:
<Customer CustomerID="ALFKI">
<Order CustomerID="ALFKI" OrderDate="1997-08-25T00:00:00">
<OrderID>10643</OrderID>
</Order>
<Order CustomerID="ALFKI" OrderDate="1997-10-03T00:00:00">
<OrderID>10692</OrderID>
</Order>
</Customer>
...Assume also that the CustomerID attribute of the <Customer> element is to be of ID type and the CustomerID attribute of <Order> element is to be an IDREF type. Because an order can belong to only one customer, an IDREF is specified.
The process of writing the query to produce the universal table and the processing of the universal table rowset to produce the resulting XML document is similar to the process described in Example A and Example B. The only addition to the query is that the directives (ID and IDREF) are specified as part of the columns.
This is the query:
SELECT 1 as Tag,
NULL as Parent,
Customers.CustomerID as [Customer!1!CustomerID!id],
NULL as [Order!2!OrderID!element],
NULL as [Order!2!CustomerID!idref],
NULL as [Order!2!OrderDate]
FROM Customers
UNION ALL
SELECT 2,
1,
Customers.CustomerID,
Orders.OrderID, Orders.CustomerID,
Orders.OrderDate
FROM Customers, Orders
WHERE Customers.CustomerID = Orders.CustomerID
ORDER BY [Customer!1!CustomerID!id], [Order!2!OrderID!element]
FOR XML EXPLICIT, XMLDATA
The ID or IDREF directives specified in the query mark the elements/attributes in the XML-Data schema. In the query:
- ID directive is specified as part of the universal table column name (Customer!1!CustomerID!id). This directive makes the CustomerID attribute of the <Customer> element in the returned XML documents an ID type attribute. In the XML-Data schema the dt:type value is ID in the AttributeType declaration.
- IDREF directive is specified as part of the universal table column name (Order!2!OrderID!idref). This directive makes the OrderID attribute of the <Order> element in the returned XML documents an IDREF type attribute. In the XML-Data schema the dt:type value is IDREF in the AttributeType declaration.
You can obtain the XML-Data schema by specifying the XMLDATA schema option in the query. Note that the ID and IDREF directives specified in the query overwrite the data types in the XML-Data schema.
This is the partial result. Because the XMLDATA schema option is specified in the query, the schema is prepended to the result.
<Schema name="Schema1" xmlns="urn:schemas-microsoft-com:xml-data" xmlns:dt="urn:schemas-microsoft-com:datatypes">
<ElementType name="Customer" content="mixed" model="open">
<AttributeType name="CustomerID" dt:type="id"/>
<attribute type="CustomerID"/>
</ElementType>
<ElementType name="Order" content="mixed" model="open">
<AttributeType name="CustomerID" dt:type="idref"/>
<AttributeType name="OrderDate" dt:type="dateTime"/>
<element type="OrderID"/>
<attribute type="CustomerID"/>
<attribute type="OrderDate"/>
</ElementType>
<ElementType name="OrderID" content="textOnly" model="closed"
dt:type="i4"/>
</Schema>
<Customer xmlns="x-schema:#Schema1" CustomerID="ALFKI">
<Order CustomerID="ALFKI" OrderDate="1997-08-25T00:00:00">
<OrderID>10643</OrderID>
</Order>
<Order CustomerID="ALFKI" OrderDate="1997-10-03T00:00:00">
<OrderID>10692</OrderID>
</Order>
</Customer>
H. Specify the ID and IDREFS attributes
An element attribute can be specified as an ID type attribute, and the IDREFS attribute can then be used to refer to it, thereby enabling intradocument links (similar to the primary key, foreign key relationships in relational databases).
This example shows how the ID and IDREFS directives can be specified as part of the column names in a query to create XML attributes of ID and IDREFS types. Because IDs cannot be integer values, the ID values in this example are converted (type casted); prefixes are used for the ID values.
In the ORDER BY clause, the customer name is specified as the ordering attribute to show that attributes that are not ID can be used to sort the result.
Assume these tables exist in the database:
-- Create Customers2 table.
CREATE TABLE Customers2 (CustomerID int primary key,
CustomerName varchar(50))
GO
-- Insert records in Customers2 table.
INSERT INTO Customers2 values (1, 'Joe')
INSERT INTO Customers2 values (2, 'Bob')
INSERT INTO Customers2 values (3, 'Mary')
Go
-- Create Orders2 table.
CREATE TABLE Orders2 (OrderID int primary key,
CustomerID int references Customers2)
GO
-- Insert records in Orders2 table.
INSERT INTO Orders2 values (5, 3)
INSERT INTO Orders2 values (6, 1)
INSERT INTO Orders2 values (9, 1)
INSERT INTO Orders2 values (3, 1)
INSERT INTO Orders2 values (8, 2)
INSERT INTO Orders2 values (7, 2)
GO
Assume a query is to return an XML document with this hierarchy:
<Cust CustID="1" CustName="Joe" OrderIDList="O-3 O-6 O-9">
<Order Oid="O-3"/>
<Order Oid="O-6"/>
<Order Oid="O-9"/>
</Cust>
<Cust CustID="2" CustName="Bob" OrderIDList="O-7 O-8">
<Order Oid="O-7"/>
<Order Oid="O-8"/>
</Cust>
<Cust CustID="3" CustName="Mary" OrderIDList="O-5">
<Order Oid="O-5"/>
</Cust>
The OrderIDList attribute of the <Cust> element is a multivalued attribute referring to the Oid attribute of <Order> element. To establish this link, the Oid attribute must be declared of ID type, and the OrderIDList attribute of the <Cust> element must be declared of IDREFS type. Because a customer can place many orders, IDREFS type is used.
The process of writing the query to produce the universal table and the processing of the universal table rowset to produce the resulting XML document is similar to the process described in Example A and Example B. The only addition to the query is that the directives (ID and IDREFS) are specified as part of the columns.
This is the query:
-- Generate Customer element without IDREFS attribute.
SELECT 1 AS tag,
NULL AS parent,
CustomerID AS "Cust!1!CustID",
CustomerName AS "Cust!1!CustName",
NULL AS "Cust!1!OrderIDList!idrefs",
NULL AS "Order!2!Oid!id"
FROM Customers2
UNION ALL
-- Now add the IDREFS. Note that Customers2.CustomerName
-- is repeated because it is listed in the ORDER BY clause
-- (otherwise, NULL would suffice).
SELECT 1 AS tag,
NULL AS parent,
Customers2.CustomerID,
Customers2.CustomerName,
'O-'+CAST(Orders2.OrderID as varchar(5)),
NULL
FROM Customers2 join Orders2 on Customers2.CustomerID = Orders2.CustomerID
UNION ALL
-- Now add the subelements (Orders2).
-- Customers2.CustomerID is repeated because it is the parent key.
-- Customers2.CustomerName is repeated because it is listed
-- in the ORDER BY clause.
SELECT 2 AS tag,
1 AS parent,
Customers2.CustomerID,
Customers2.CustomerName,
NULL,
'O-'+CAST(Orders2.OrderID as varchar(5))
FROM Customers2 JOIN Orders2 ON Customers2.CustomerID = Orders2.CustomerID
-- Now order by name and by key. No order on the last column
-- is required because the key of Orders2 is not a parent.
ORDER BY "Cust!1!CustID", "Order!2!Oid!id", "Cust!1!OrderIDList!idrefs"
FOR XML EXPLICIT, XMLDATA
The ID or IDREFS directives specified in the query mark the elements/attributes in the XML-Data schema. In the query:
- ID directive is specified as part of the universal table column name (Order!2!Oid!id). The directive makes the Oid attribute of the <Order> element in the returned XML documents an ID type attribute. In the XML-Data schema the dt:type value is ID in the AttributeType declaration.
- IDREF directive is specified as part of the universal table column name (Cust!1!OrderIDList!idrefs). The directive makes the OrderIDList attribute of the <Cust> element in the returned XML documents an IDREF type attribute. In the XML-Data schema the dt:type value is IDREFS in the AttributeType declaration.
You can obtain the XML-Data schema by specifying the XMLDATA option in the query. Note that the ID and IDREFS directives specified in the query overwrite the data types in the XML-Data schema.
This is the result:
<Schema name="Schema8" xmlns="urn:schemas-microsoft-com:xml-data"
xmlns:dt="urn:schemas-microsoft-com:datatypes">
<ElementType name="Cust" content="mixed" model="open">
<AttributeType name="CustID" dt:type="i4"/>
<AttributeType name="CustName" dt:type="string"/>
<AttributeType name="OrderIDList" dt:type="idrefs"/>
<attribute type="CustID"/>
<attribute type="CustName"/>
<attribute type="OrderIDList"/>
</ElementType>
<ElementType name="Order" content="mixed" model="open">
<AttributeType name="Oid" dt:type="id"/>
<attribute type="Oid"/>
</ElementType>
</Schema>
<Cust xmlns="x-schema:#Schema8" CustID="1" CustName="Joe"
OrderIDList="O-3 O-6 O-9">
<Order Oid="O-3"/>
<Order Oid="O-6"/>
<Order Oid="O-9"/>
</Cust>
<Cust xmlns="x-schema:#Schema8" CustID="2" CustName="Bob"
OrderIDList="O-7 O-8">
<Order Oid="O-7"/>
<Order Oid="O-8"/>
</Cust>
<Cust xmlns="x-schema:#Schema8" CustID="3" CustName="Mary"
OrderIDList="O-5">
<Order Oid="O-5"/>
</Cust>
I. Specify the xmltext directive
This example shows how data in the overflow column is addressed using the xmltext directive in a SELECT statement using EXPLICIT mode.
Consider the Person table. This table has the Overflow column that stores unconsumed part of XML document.
CREATE TABLE Person(PersonID varchar(5), PersonName varchar(20), Overflow nvarchar(200))
INSERT INTO Person VALUES ('P1','Joe',N'<SomeTag attr1="data">content</SomeTag>')
INSERT INTO Person VALUES ('P2','Joe',N'<SomeTag attr2="data"/>')
INSERT INTO Person VALUES ('P3','Joe',N'<SomeTag attr3="data" PersonID="P">content</SomeTag>')
This query retrieves columns from the Person table. For the Overflow column, AttributeName is not specified, but directive is set to xmltext as part of providing universal table column name.
SELECT 1 as Tag, NULL as parent,
PersonID as [Parent!1!PersonID],
PersonName as [Parent!1!PersonName],
overflow as [Parent!1!!xmltext] -- No AttributeName; xmltext directive
FROM Person
FOR XML EXPLICIT
Because AttributeName is not specified for the Overflow column and the xmltext directive is specified, in the resulting XML document the attributes in the <overflow> element are appended to the attribute list of the enclosing <Parent> element, and because the PersonID attribute in the <xmltext> element conflicts with the PersonID attribute retrieved on the same element level, the attribute in the <xmltext> element is ignored (even if PersonID is NULL). Generally, an attribute overrides an attribute of the same name in the overflow.
This is the result:
<Parent PersonID="P1" PersonName="Joe" attr1="data">
content</Parent>
<Parent PersonID="P2" PersonName="Joe" attr2="data">
</Parent>
<Parent PersonID="P3" PersonName="Joe" attr3="data">
content</Parent>
If the overflow data had subelements and the same query is specified, the subelements in the Overflow column are added as the subelements of the enclosing <Parent> element.
For example, change the data in the Person table so that the Overflow column now has subelements:
TRUNCATE TABLE Person
INSERT INTO Person VALUES ('P1','Joe',N'<SomeTag attr1="data">content</SomeTag>')
INSERT INTO Person VALUES ('P2','Joe',N'<SomeTag attr2="data"/>')
INSERT INTO Person VALUES ('P3','Joe',N'<SomeTag attr3="data" PersonID="P"><name>content</name></SomeTag>')
If the same query is executed, the subelements in the <xmltext> element are added as subelements of the enclosing <Parent> element.
SELECT 1 as Tag, NULL as parent,
PersonID as [Parent!1!PersonID],
PersonName as [Parent!1!PersonName],
overflow as [Parent!1!!xmltext] -- no AttributeName, xmltext directive
FROM Person
FOR XML EXPLICIT
This is the result:
<Parent PersonID="P1" PersonName="Joe" attr1="data">
content</Parent>
<Parent PersonID="P2" PersonName="Joe" attr2="data">
</Parent>
<Parent PersonID="P3" PersonName="Joe" attr3="data">
<name>content</name></Parent>
If AttributeName is specified with the xmltext directive, the attributes of the <overflow> element are added as attributes of the subelements of the enclosing <Parent> element. The name specified for AttributeName becomes the name of the subelement
In this query, AttributeName (<overflow>) is specified along with the xmltext directive.
SELECT 1 as Tag, NULL as parent,
PersonID as [Parent!1!PersonID],
PersonName as [Parent!1!PersonName],
overflow as [Parent!1!overflow!xmltext] -- overflow is AttributeName
-- xmltext is directive
FROM Person
FOR XML EXPLICIT
This is the result:
<Parent PersonID="P1" PersonName="Joe">
<overflow attr1="data">
content</overflow>
</Parent>
<Parent PersonID="P2" PersonName="Joe">
<overflow attr2="data"/>
</Parent>
<Parent PersonID="P3" PersonName="Joe">
<overflow attr3="data" PersonID="P">
<name>content</name></overflow>
</Parent>
In this query element, directive is specified for PersonName attribute. This results in PersonName added as subelement of the enclosing <Parent> element. The attributes of the <xmltext> are still appended to the enclosing <Parent> element. The contents of <overflow> element (subelements and so on) are prepended to the other subelements of the enclosing <Parent> elements.
SELECT 1 as Tag, NULL as parent,
PersonID as [Parent!1!PersonID],
PersonName as [Parent!1!PersonName!element], -- element directive
overflow as [Parent!1!!xmltext]
FROM Person
FOR XML EXPLICIT
This is the result:
<Parent PersonID="P1" attr1="data">
content <PersonName>Joe</PersonName>
</Parent>
<Parent PersonID="P2" attr2="data">
<PersonName>Joe</PersonName>
</Parent>
<Parent PersonID="P3" attr3="data">
<name>content</name> <PersonName>Joe</PersonName>
</Parent>
If the xmltext column data contain attributes on the root element, these attributes are not shown in XML-Data schema and the MSXML parser does not validate the resulting XML document fragment, for example:
SELECT 1 as Tag,
0 as Parent,
N'<overflow a="1"/>' as 'overflow!1!!xmltext'
FOR XML EXPLICIT, xmldata
This is the result. Note that in the returned schema, the overflow attribute a is missing from the schema.
<Schema name="Schema12" xmlns="urn:schemas-microsoft-com:xml-data"
xmlns:dt="urn:schemas-microsoft-com:datatypes">
<ElementType name="overflow" content="mixed" model="open">
</ElementType>
</Schema>
<overflow xmlns="x-schema:#Schema12" a="1"> </overflow>
J. Obtain an XML document consisting of customers, orders, and order details
The query in this example generates the universal table rowset described in the conceptual discussion earlier in the topic.
Assume this is the hierarchy to be generated:
<Customer cid="C1" name="Janine">
<Order id="O1" date="1/20/1996">
<OrderDetail id="OD1" pid="P1"/>
<OrderDetail id="OD2" pid="P2"/>
</Order>
<Order id="O2" date="3/29/1997">
...
</Customer>
The process of writing the query to produce the universal table and the processing of the universal table rowset to produce the resulting XML document is similar to the process described in Example A and Example B.
SELECT 1 as Tag,
NULL as Parent,
C.CustomerID as [Customer!1!cid],
C.ContactName as [Customer!1!name],
NULL as [Order!2!id],
NULL as [Order!2!date],
NULL as [OrderDetail!3!id!id],
NULL as [OrderDetail!3!pid!idref]
FROM Customers C
UNION ALL
SELECT 2 as Tag,
1 as Parent,
C.CustomerID,
NULL,
O.OrderID,
O.OrderDate,
NULL,
NULL
FROM Customers C, Orders O
WHERE C.CustomerID = O.CustomerID
UNION ALL
SELECT 3 as Tag,
2 as Parent,
C.CustomerID,
NULL,
O.OrderID,
NULL,
OD.OrderID,
OD.ProductID
FROM Customers C, Orders O, [Order Details] OD
WHERE C.CustomerID = O.CustomerID
AND O.OrderID = OD.OrderID
ORDER BY [Customer!1!cid], [Order!2!id]
FOR XML EXPLICIT
This is the partial result:
<Customer cid="ALFKI" name="Maria Anders">
<Order id="10643" date="1997-08-25T00:00:00">
<OrderDetail id="10643" pid="28"></OrderDetail>
<OrderDetail id="10643" pid="39"></OrderDetail>
</Order>
<Order id="10692" date="1997-10-03T00:00:00">
<OrderDetail id="10692" pid="63"></OrderDetail>
</Order>
<Order id="10702" date="1997-10-13T00:00:00">
<OrderDetail id="10702" pid="3"></OrderDetail>
<OrderDetail id="10702" pid="76"></OrderDetail>
</Order>
</Customer>