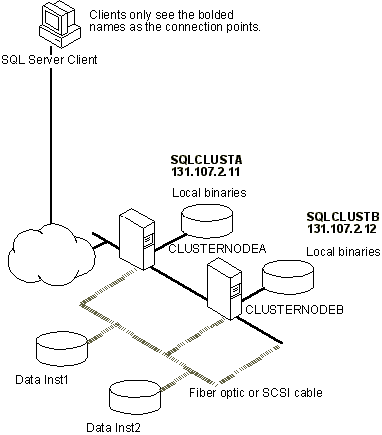
Failover Clustering Example
The following example illustrates how you configure Microsoft® SQL Server™ 2000 failover clustering.
CLUSTERNODEA and CLUSTERNODEB are two computers in a failover cluster. Run SQL Server Setup on CLUSTERNODEA and create a virtual server named "SQLCLUSTA." Then install a default instance of SQL Server 2000, which can run on both CLUSTERNODEA and CLUSTERNODEB. From this point forward, connect to the server by specifying "SQLCLUSTA" as the server name in the connection string.
Run the Setup program again on CLUSTERNODEB. Create a new virtual server named "SQLCLUSTB" (in a different Microsoft Cluster Service (MSCS) cluster group) and install an instance named "Inst1" that can run on both CLUSTERNODEA and CLUSTERNODEB. From this point forward, connect to the server by specifying "SQLCLUSTB\Inst1" as the connection string.
The two virtual servers are running in the MSCS cluster consisting of CLUSTERNODEA and CLUSTERNODEB. Other than that, they are completely separate from each other. Each virtual server resides in a different MSCS cluster group, and each has a different set of IP addresses, a distinct network name, and data files that reside on a separate set of shared cluster disks.
When a failover occurs for any resource in an MSCS cluster group, all resources that are members of that group also fail over. For SQLCLUSTA, any failure (from the disk resources, IP address, the network name, or the installations of SQL Server 2000 within the virtual server) causes all members of the cluster group to fail over when the failover threshold is reached.
The following illustration is a two-node cluster with binaries and data. Each virtual server in this illustration must have exclusive ownership of the disk on which the data and log files are located.