Readme
From Word Lister
Word Lister (c) gazlan@gmx.de 2011
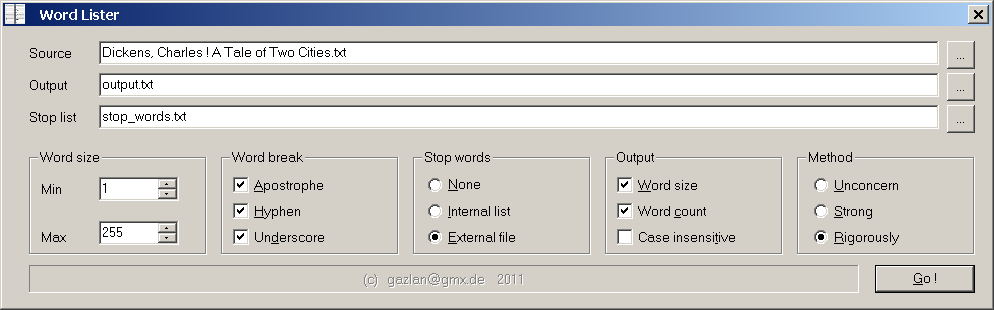
English version Программа предназначена для составления списка уникальных слов, встречающихся в файле. Обрабатываются файлы любых форматов (включая бинарные). Под словом при этом понимается непрерывная последовательность латинских букв (в обоих регистрах) в диапазоне длин от MIN до MAX (зависит от настроек). Три специальных символа: Апостроф, Подчеркивание и Тире (и их "типографские" варианты a la M$Word), в зависимости от настроек, трактуются либо как часть слова (считаются за латинскую букву) либо как разрыв между словами. Дополнительно, может быть использован фильтр т.н. "стоп-слов" (часто встречающихся слов, таких как предлоги, союзы, междометия и т.п., нерелевантных содержанию документа и бесполезных для поискового запроса) либо встроенный в программу, либо использующий слова из специально форматированного файла (Word List). В программе реализовано три метода обработки: 1. Unconcern Наиболее быстрый. Для проверки слов на уникальность вычисляется хэш-функция с высокой диффузностью. Для хранения вычисленных хэшей используется временный файл. 2. Strong Медленный. Метод аналогичен предыдущему, но использована Strong Crypto Hash function, гарантирующая отсутствие коллизий (теоретическая оценка вероятности коллизии - 1 / 2 ^ 80 - пренебрежимо малая величина). 3. Rigorously Самый медленный. Хэши вычисляются так же, как в предыдущем методе, но, дополнительно, создается временный файл статистики для подсчета общего числа вхождений для каждого слова. Файл отчета создается в стандартном формате Word List (word per line), при необходимости, дополнительно может быть выведена длина слова и общее количество вхождений (только для метода Rigorously).